개발자로서 현장에서 일하면서 새로 접하는 기술들이나 알게된 정보 등을 정리하기 위한 블로그입니다. 운 좋게 미국에서 큰 회사들의 프로젝트에서 컬설턴트로 일하고 있어서 새로운 기술들을 접할 기회가 많이 있습니다. 미국의 IT 프로젝트에서 사용되는 툴들에 대해 많은 분들과 정보를 공유하고 싶습니다.
This document is a draft of a guide that will be added to the next revision of the OpenAI documentation. If you have any feedback, feel free to let us know.
이 문서는 OpenAI 문서의 다음 개정판에 추가될 가이드의 초안입니다. 의견이 있으시면 언제든지 알려주십시오.
One note: this doc shares metrics for text-davinci-002, but that model is not yet available for fine-tuning.
참고: 이 문서는 text-davinci-002에 대한 메트릭을 공유하지만 해당 모델은 아직 미세 조정에 사용할 수 없습니다.
Best practices for fine-tuning GPT-3 to classify text
GPT-3’s understanding of language makes it excellent at text classification. Typically, the best way to classify text with GPT-3 is to fine-tune GPT-3 on training examples. Fine-tuned GPT-3 models can meet and exceed state-of-the-art records on text classification benchmarks.
GPT-3의 언어 이해력은 텍스트 분류에 탁월합니다. 일반적으로 GPT-3으로 텍스트를 분류하는 가장 좋은 방법은 training examples 로 GPT-3을 fine-tune하는 것입니다. Fine-tuned GPT-3 모델은 텍스트 분류 벤치마크에서 최신 기록을 충족하거나 능가할 수 있습니다.
This article shares best practices for fine-tuning GPT-3 to classify text.
이 문서에서는 GPT-3을 fine-tuning 하여 텍스트를 분류하는 모범 사례를 공유합니다.
The OpenAI fine-tuning guide explains how to fine-tune your own custom version of GPT-3. You provide a list of training examples (each split into prompt and completion) and the model learns from those examples to predict the completion to a given prompt.
OpenAIfine-tuning guide는 사용자 지정 GPT-3 버전을 fine-tune하는 방법을 설명합니다. 교육 예제 목록(각각 prompt와 completion로 분할)을 제공하면 모델이 해당 예제에서 학습하여 주어진 prompt에 대한 completion를 예측합니다.
{"prompt": "dog toy -->", "completion": " inedible"}
During fine-tuning, the model reads the training examples and after each token of text, it predicts the next token. This predicted next token is compared with the actual next token, and the model’s internal weights are updated to make it more likely to predict correctly in the future. As training continues, the model learns to produce the patterns demonstrated in your training examples.
fine-tuning 중에 모델은 교육 예제를 읽고 텍스트의 각 토큰을 받아들여 그 다음 토큰이 무엇이 올 지 예측을 하게 됩니다. 이 예측된 다음 토큰은 실제 다음 토큰과 비교되고 모델의 내부 가중치가 업데이트되어 향후에 올바르게 예측할 가능성이 높아집니다. 학습이 계속됨에 따라 모델은 학습 예제에 표시된 패턴을 생성하는 방법을 배웁니다.
After your custom model is fine-tuned, you can call it via the API to classify new examples:
사용자 지정 모델이 fine-tuned된 후 API를 통해 호출하여 새 예제를 분류할 수 있습니다.
As ‘ edible’ is 1 token and ‘ inedible’ is 3 tokens, in this example, we request just one completion token and count ‘ in’ as a match for ‘ inedible’.
'edible'은 토큰 1개이고 'inedible'은 토큰 3개이므로 이 예에서는 완료 토큰 하나만 요청하고 'inedible'에 대한 일치 항목으로 'in'을 계산합니다.
Example API call to get probabilities for the 5 most likely tokens
가장 유사한 토큰 5개에 대한 probabilities를 얻기 위한 API call 예제
api_response = openai.Completion.create(
model="{fine-tuned model goes here, without brackets}",
prompt="toothpaste -->",
temperature=0,
max_tokens=1,
logprobs=5
)
dict_of_logprobs = api_response['choices'][0]['logprobs']['top_logprobs'][0].to_dict()
dict_of_probs = {k: 2.718**v for k, v in dict_of_logprobs.items()}
Training data
The most important determinant of success is training data.
Fine-tuning 성공의 가장 중요한 결정 요인은 학습 데이터입니다.
Your training data should be:
학습 데이터는 다음과 같아야 합니다.
Large (ideally thousands or tens of thousands of examples)
대규모(이상적으로는 수천 또는 수만 개의 예)
High-quality (consistently formatted and cleaned of incomplete or incorrect examples)
고품질(불완전하거나 잘못된 예를 일관되게 형식화하고 정리)
Representative (training data should be similar to the data upon which you’ll use your model)
대표(학습 데이터는 모델을 사용할 데이터와 유사해야 함)
Sufficiently specified (i.e., containing enough information in the input to generate what you want to see in the output)
충분히 특정화 되어야 함 (즉, 출력에서 보고 싶은 것을 생성하기 위해 입력에 충분한 정보 포함)
If you aren’t getting good results, the first place to look is your training data. Try following the tips below about data formatting, label selection, and quantity of training data needed. Also review our list of common mistakes.
좋은 결과를 얻지 못한 경우 가장 먼저 살펴봐야 할 곳은 훈련 데이터입니다. 데이터 형식, 레이블 선택 및 필요한 학습 데이터 양에 대한 아래 팁을 따르십시오. common mistakes 목록도 검토하십시오.
How to format your training data
Prompts for a fine-tuned model do not typically need instructions or examples, as the model can learn the task from the training examples. Including instructions shouldn’t hurt performance, but the extra text tokens will add cost to each API call.
모델이 교육 예제에서 작업을 학습할 수 있으므로 fine-tuned 모델에 대한 프롬프트에는 일반적으로 지침(instruction)이나 예제가 필요하지 않습니다. 지침(instruction)을 포함해도 성능이 저하되지는 않지만 추가 텍스트 토큰으로 인해 각 API 호출에 비용이 추가됩니다.
Prompt
Tokens
Recommended
“burger -->"
3
✅
“Label the following item as either edible or inedible.
Item: burger Label:”
20
❌
“Item: cake Category: edible
Item: pan Category: inedible
Item: burger Category:”
26
❌
Instructions can still be useful when fine-tuning a single model to do multiple tasks. For example, if you train a model to classify multiple features from the same text string (e.g., whether an item is edible or whether it’s handheld), you’ll need some type of instruction to tell the model which feature you want labeled.
지침(instruction)은 여러 작업을 수행하기 위해 단일 모델을 fine-tuning할 때 여전히 유용할 수 있습니다. 예를 들어, 동일한 텍스트 문자열에서 여러 기능을 분류하도록 모델을 훈련하는 경우(예: 항목이 먹을 수 있는지 또는 휴대 가능한지 여부) 라벨을 지정하려는 기능을 모델에 알려주는 일종의 지침이 필요합니다.
Example training data:
Prompt
Completion
“burger --> edible:”
“ yes”
“burger --> handheld:”
“ yes”
“car --> edible:”
“ no”
“car --> handheld:”
“ no”
Example prompt for unseen example:
Prompt
Completion
“cheese --> edible:”
???
Note that for most models, the prompt + completion for each example must be less than 2048 tokens (roughly two pages of text). For text-davinci-002, the limit is 4000 tokens (roughly four pages of text).
대부분의 모델에서 각 예제에 대한 prompt + completion은 2048 토큰(약 2페이지의 텍스트) 미만이어야 합니다. text-davinci-002의 경우 한도는 4000개 토큰(약 4페이지의 텍스트)입니다.
Separator sequences
For classification, end your text prompts with a text sequence to tell the model that the input text is done and the classification should begin. Without such a signal, the model may append additional invented text before appending a class label, resulting in outputs like:
분류를 위해 입력 텍스트가 완료되고 분류가 시작되어야 함을 모델에 알리는 텍스트 시퀀스로 텍스트 프롬프트를 종료합니다. 이러한 신호가 없으면 모델은 클래스 레이블을 appending하기 전에 추가 invented text 를 append하여 다음과 같은 결과를 얻을 수 있습니다.
burger edible (accurate)
burger and fries edible (not quite was asked for)
burger-patterned novelty tie inedible (inaccurate)
burger burger burger burger (no label generated)
Examples of separator sequences
Prompt
Recommended
“burger”
❌
“burger -->”
✅
“burger
###
“
✅
“burger >>>”
✅
“burger
Label:”
✅
Be sure that the sequence you choose is very unlikely to otherwise appear in your text (e.g., avoid ‘###’ or ‘->’ when classifying Python code). Otherwise, your choice of sequence usually doesn’t matter much.
선택한 sequence가 텍스트에 다른 방법으로 사용되는 부호인지 확인하세요. (예: Python 코드를 분류할 때 '###' 또는 '->'를 피하십시오). 그러한 경우가 아니라면 시퀀스 선택은 일반적으로 그다지 중요하지 않습니다.
How to pick labels
One common question is what to use as class labels.
일반적인 질문 중 하나는 클래스 레이블로 무엇을 사용할 것인가입니다.
In general, fine-tuning can work with any label, whether the label has semantic meaning (e.g., “ edible”) or not (e.g., “1”). That said, in cases with little training data per label, it’s possible that semantic labels work better, so that the model can leverage its knowledge of the label’s meaning.
일반적으로 fine-tuning은 레이블에 semantic 의미(예: "식용")가 있든 없든(예: "1") 모든 레이블에서 작동할 수 있습니다. 즉, 레이블당 학습 데이터가 적은 경우 시맨틱 레이블이 더 잘 작동하여 모델이 레이블의 의미에 대한 지식을 활용할 수 있습니다.
When convenient, we recommend single-token labels. You can check the number of tokens in a string with the OpenAI tokenizer. Single-token labels have a few advantages:
가능하면 단일 토큰 레이블을 사용하는 것이 좋습니다. OpenAI 토크나이저를 사용하여 문자열의 토큰 수를 확인할 수 있습니다. 단일 토큰 레이블에는 다음과 같은 몇 가지 장점이 있습니다.
Lowest cost . 적은 비용
Easier to get their probabilities, which are useful for metrics confidence scores, precision, recall
메트릭 신뢰도 점수, 정밀도, recall에 유용한 확률을 쉽게 얻을 수 있습니다.
No hassle from specifying stop sequences or post-processing completions in order to compare labels of different length
다른 길이의 레이블을 비교하기 위해 중지 시퀀스 또는 후처리 완료를 지정하는 번거로움이 없습니다.
Example labels
Prompt
Label
Recommended
“burger -->”
“ edible”
✅
“burger -->”
“ 1”
✅
“burger -->”
“ yes”
✅
“burger -->”
“ A burger can be eaten”
❌ (but still works)
One useful fact: all numbers <500 are single tokens. 500 이하는 single token입니다.
If you do use multi-token labels, we recommend that each label begin with a different token. If multiple labels begin with the same token, an unsure model might end up biased toward those labels due to greedy sampling.
multi-token label을 사용하는 경우 각 레이블이 서로 다른 토큰으로 시작하는 것이 좋습니다. 여러 레이블이 동일한 토큰으로 시작하는 경우 greedy 샘플링으로 인해 불확실한 모델이 해당 레이블로 편향될 수 있습니다.
How much training data do you need
How much data you need depends on the task and desired performance.
필요한 데이터의 양은 작업과 원하는 성능에 따라 다릅니다.
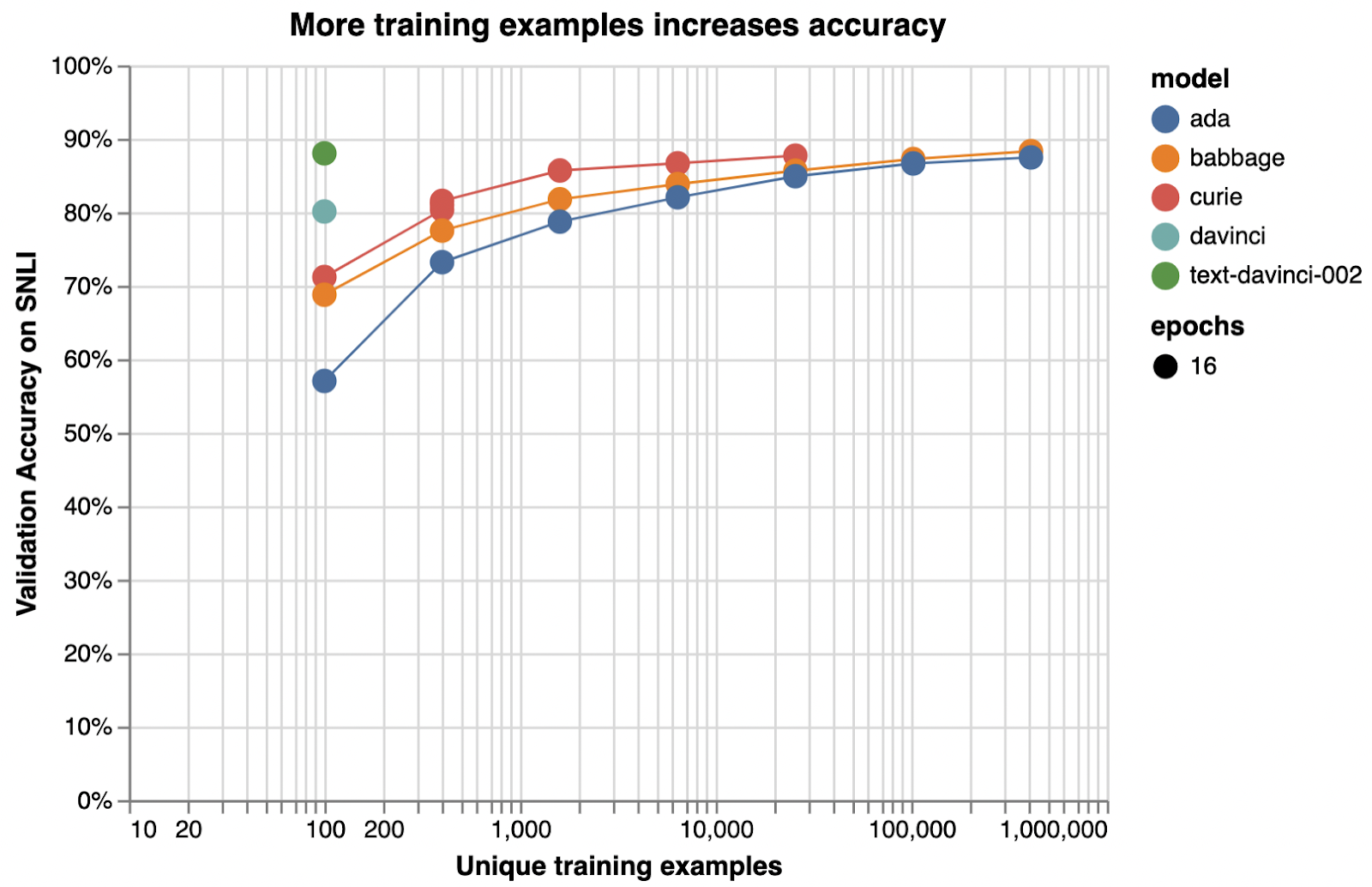
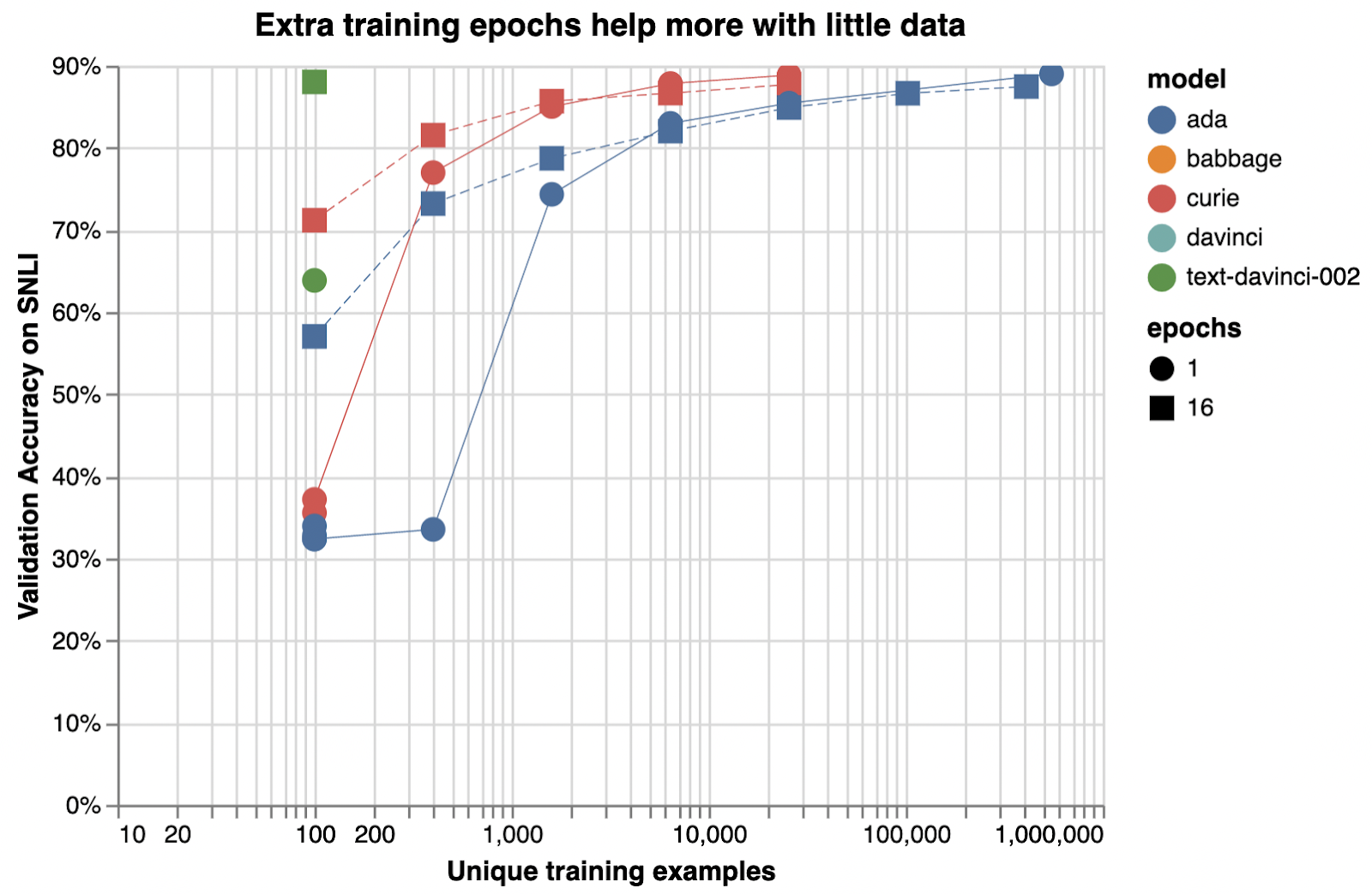
Below is an illustrative example of how adding training examples improves classification accuracy.
아래는 학습 예제를 추가하여 분류 정확도를 향상시키는 방법을 보여주는 예시입니다.
Illustrative examples of text classification performance on the Stanford Natural Language Inference (SNLI) Corpus, in which ordered pairs of sentences are classified by their logical relationship: either contradicted, entailed (implied), or neutral. Default fine-tuning parameters were used when not otherwise specified.
SNLI(Stanford Natural Language Inference) 코퍼스의 텍스트 분류 성능에 대한 예시로, 정렬된 문장 쌍이 논리적 관계(모순됨, 함축됨(암시됨) 또는 중립)에 따라 분류됩니다. 달리 지정되지 않은 경우 기본 fine-tuning 매개변수가 사용되었습니다.
Very roughly, we typically see that a few thousand examples are needed to get good performance:
아주 대략적으로 말해서 좋은 성능을 얻으려면 일반적으로 수천 개의 예제가 필요하다는 것을 알 수 있습니다.
Examples per label
Performance (rough estimate)
Hundreds
Decent
Thousands
Good
Tens of thousands or more
Great
To assess the value of getting more data, you can train models on subsets of your current dataset—e.g., 25%, 50%, 100%—and then see how performance scales with dataset size. If you plot accuracy versus number of training examples, the slope at 100% will indicate the improvement you can expect from getting more data. (Note that you cannot infer the value of additional data from the evolution of accuracy during a single training run, as a model half-trained on twice the data is not equivalent to a fully trained model.)
더 많은 데이터를 얻는 가치를 평가하기 위해 현재 데이터 세트의 하위 집합(예: 25%, 50%, 100%)에서 모델을 교육한 다음 데이터 세트 크기에 따라 성능이 어떻게 확장되는지 확인할 수 있습니다. 정확도 대 교육 예제 수를 플로팅하는 경우 100%의 기울기는 더 많은 데이터를 얻을 때 기대할 수 있는 개선을 나타냅니다. (두 배의 데이터로 절반만 훈련된 모델은 완전히 훈련된 모델과 동일하지 않기 때문에 단일 훈련 실행 동안 정확도의 진화에서 추가 데이터의 가치를 추론할 수 없습니다.)
How to evaluate your fine-tuned model
Evaluating your fine-tuned model is crucial to (a) improve your model and (b) tell when it’s good enough to be deployed.
fine-tuned 모델을 평가하는 것은 (a) 모델을 개선하고 (b) 언제 배포하기에 충분한 지를 알려주는 데 중요합니다.
Many metrics can be used to characterize the performance of a classifier
많은 메트릭을 사용하여 분류기의 성능을 특성화할 수 있습니다.
Accuracy
F1
Precision / Positive Predicted Value / False Discovery Rate
Recall / Sensitivity
Specificity
AUC / AUROC (area under the receiver operator characteristic curve)
AUPRC (area under the precision recall curve)
Cross entropy
Which metric to use depends on your specific application and how you weigh different types of mistakes. For example, if detecting something rare but consequential, where a false negative is costlier than a false positive, you might care about recall more than accuracy.
사용할 메트릭은 특정 응용 프로그램과 다양한 유형의 실수에 가중치를 두는 방법에 따라 다릅니다. 예를 들어 거짓 음성이 거짓 긍정보다 비용이 많이 드는 드물지만 결과적인 것을 감지하는 경우 정확도보다 리콜에 더 관심을 가질 수 있습니다.
The OpenAI API offers the option to calculate some of these classification metrics. If enabled, these metrics will be periodically calculated during fine-tuning as well as for your final model. You will see them as additional columns in your results file
OpenAI API는 이러한 분류 메트릭 중 일부를 계산하는 옵션을 제공합니다. 활성화된 경우 이러한 지표는 최종 모델뿐만 아니라 미세 조정 중에 주기적으로 계산됩니다. 결과 파일에 추가 열로 표시됩니다.
To enable classification metrics, you’ll need to:
분류 지표를 활성화하려면 다음을 수행해야 합니다.:
use single-token class labels
단일 토큰 클래스 레이블 사용
provide a validation file (same format as the training file)
유효성 검사 파일 제공(교육 파일과 동일한 형식)
set the flag --compute_classification_metrics
compute_classification_metrics 플래그 설정
for multiclass classification: set the argument --classification_n_classes
다중 클래스 분류: --classification_n_classes 인수 설정
for binary classification: set the argument --classification_positive_class
The following metrics are based on a classification threshold of 0.5 (i.e. when the probability is > 0.5, an example is classified as belonging to the positive class.)
다음 메트릭은 0.5의 분류 임계값을 기반으로 합니다(즉, 확률이 > 0.5인 경우 예는 포지티브 클래스에 속하는 것으로 분류됨).
classification/accuracy
classification/precision
classification/recall
classification/f{beta}
classification/auroc - AUROC
classification/auprc - AUPRC
Note that these evaluations assume that you are using text labels for classes that tokenize down to a single token, as described above. If these conditions do not hold, the numbers you get will likely be wrong.
이러한 평가에서는 위에서 설명한 대로 단일 토큰으로 토큰화하는 클래스에 대해 텍스트 레이블을 사용하고 있다고 가정합니다. 이러한 조건이 충족되지 않으면 얻은 숫자가 잘못되었을 수 있습니다.
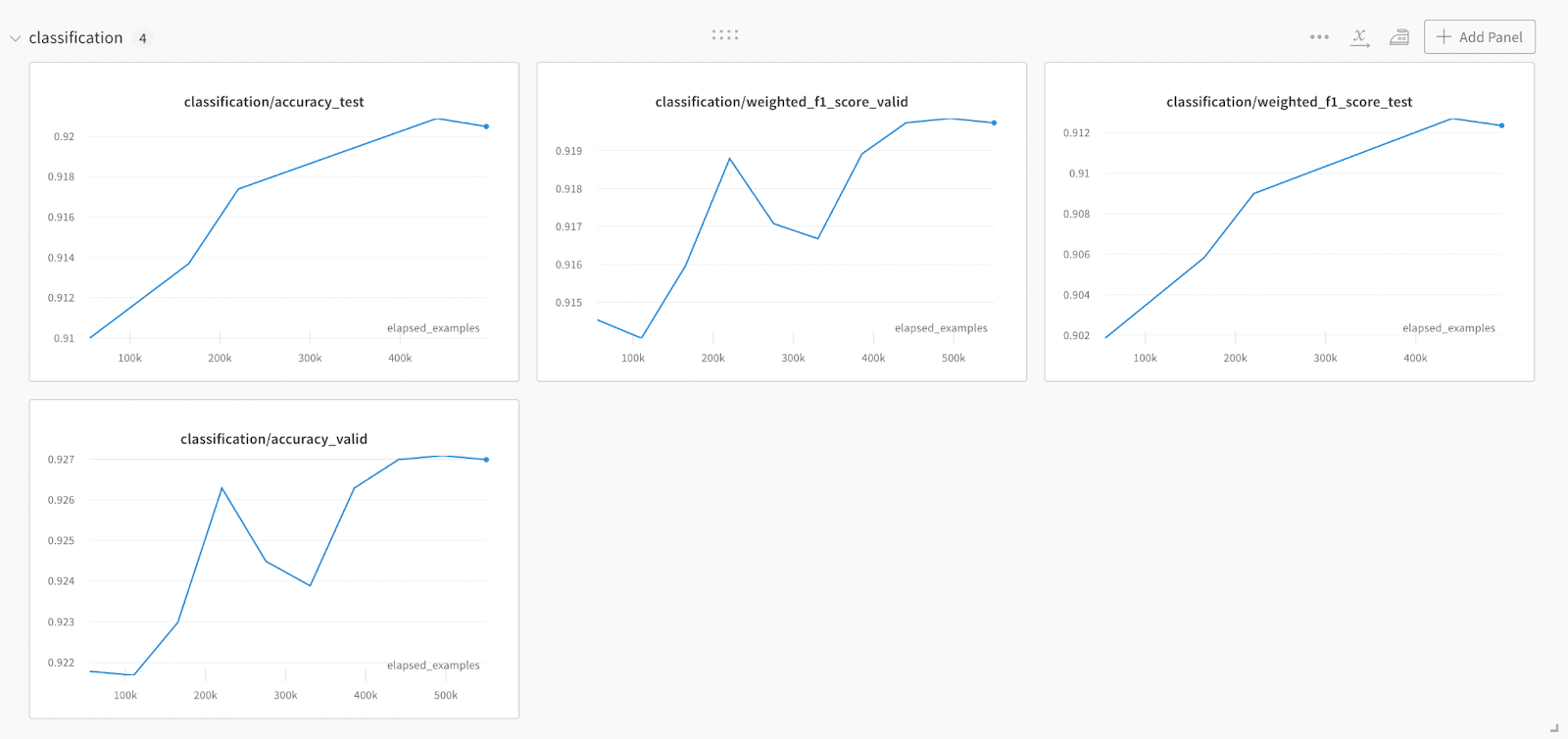
Example outputs
Example metrics evolution over a training run, visualized with Weights & Biases
Weights & Biases로 시각화된 교육 실행에 대한 메트릭 진화의 예
How to pick the right model
OpenAI offers fine-tuning for 5 models: OpenAI는 fine-tuning에 다음 5가지 모델을 사용할 것을 권장합니다.
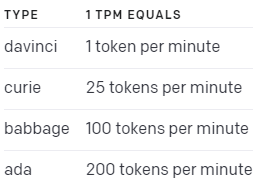
ada (cheapest and fastest)
babbage
curie
davinci
text-davinci-002 (highest quality)
Which model to use will depend on your use case and how you value quality versus price and speed.
사용할 모델은 사용 사례와 품질 대 가격 및 속도의 가치를 어떻게 평가하는지에 따라 달라집니다.
Generally, we see text classification use cases falling into two categories: simple and complex.
일반적으로 텍스트 분류 사용 사례는 단순과 복합의 두 가지 범주로 나뉩니다.
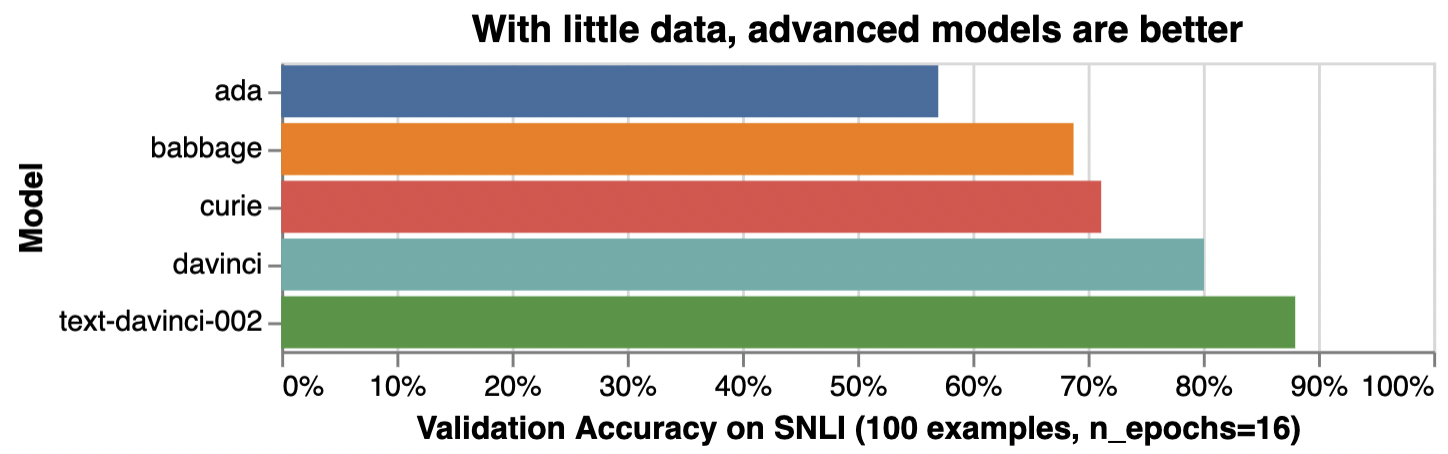
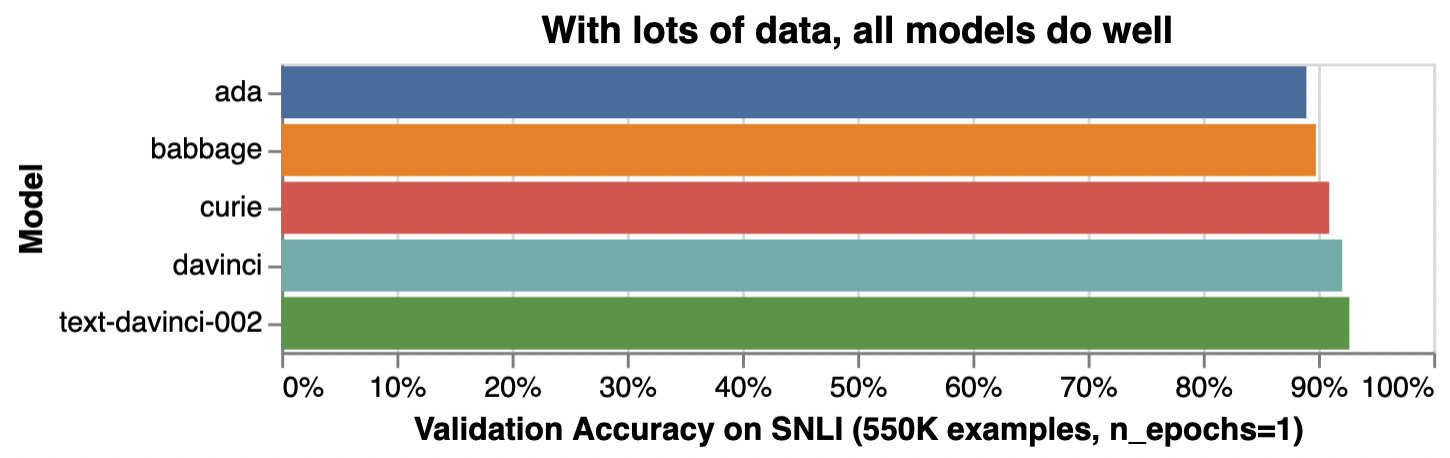
For tasks that are simple or straightforward, such as classifying sentiment, larger models offer diminishing benefit, as illustrated below:
감정 분류와 같이 간단하거나 직접적인 작업의 경우 더 큰 모델은 아래 그림과 같이 이점이 적습니다.
Model
Illustrative accuracy*
Training cost**
Inference cost**
ada
89%
$0.0004 / 1K tokens (~3,000 pages per dollar)
$0.0016 / 1K tokens (~800 pages per dollar)
babbage
90%
$0.0006 / 1K tokens (~2,000 pages per dollar)
$0.0024 / 1K tokens (~500 pages per dollar)
curie
91%
$0.003 / 1K tokens (~400 pages per dollar)
$0.012 / 1K tokens (~100 pages per dollar)
davinci
92%
$0.03 / 1K tokens (~40 pages per dollar)
$0.12 / 1K tokens (~10 pages per dollar)
text-davinci-002
93%
unreleased
unreleased
*Illustrative accuracy on the SNLI dataset, in which sentence pairs are classified as contradictions, implications, or neutral
*문장 쌍이 모순, 암시 또는 중립으로 분류되는 SNLI 데이터 세트에 대한 설명 정확도
**Pages per dollar figures assume ~800 tokens per page. OpenAI Pricing.
Illustrative examples of text classification performance on the Stanford Natural Language Inference (SNLI) Corpus, in which ordered pairs of sentences are classified by their logical relationship: either contradicted, entailed (implied), or neutral. Default fine-tuning parameters were used when not otherwise specified.
SNLI(Stanford Natural Language Inference) 코퍼스의 텍스트 분류 성능에 대한 예시로, 정렬된 문장 쌍이 논리적 관계(모순됨, 함축됨(암시됨) 또는 중립)에 따라 분류됩니다. 달리 지정되지 않은 경우 기본 미세 조정 매개변수가 사용되었습니다.
For complex tasks, requiring subtle interpretation or reasoning or prior knowledge or coding ability, the performance gaps between models can be larger, and better models like curie or text-davinci-002 could be the best fit.
미묘한 해석이나 추론 또는 사전 지식이나 코딩 능력이 필요한 복잡한 작업의 경우 모델 간의 성능 차이가 더 클 수 있으며 curie 또는 text-davinci-002와 같은 더 나은 모델이 가장 적합할 수 있습니다.
A single project might end up trying all models. One illustrative development path might look like this:
단일 프로젝트에서 모든 모델을 시도하게 될 수 있습니다. 예시적인 개발 경로는 다음과 같습니다.
Test code using the cheapest & fastest model (ada)
가장 저렴하고 빠른 모델(ada)을 사용하여 테스트 코드
Run a few early experiments to check whether your dataset works as expected with a middling model (curie)
중간 모델(curie)에서 데이터 세트가 예상대로 작동하는지 확인하기 위해 몇 가지 초기 실험을 실행합니다.
Run a few more experiments with the best model to see how far you can push performance (text-davinci-002)
최상의 모델로 몇 가지 실험을 더 실행하여 성능을 얼마나 높일 수 있는지 확인하십시오(text-davinci-002).
Once you have good results, do a training run with all models to map out the price-performance frontier and select the model that makes the most sense for your use case (ada, babbage, curie, davinci, text-davinci-002)
좋은 결과를 얻으면 모든 모델로 교육 실행을 수행하여 가격 대비 성능 한계를 파악하고 사용 사례에 가장 적합한 모델(ada, babbage, curie, davinci, text-davinci-002)을 선택합니다.
Another possible development path that uses multiple models could be:
여러 모델을 사용하는 또 다른 가능한 개발 경로는 다음과 같습니다.
Starting with a small dataset, train the best possible model (text-davinci-002)
작은 데이터 세트로 시작하여 가능한 최상의 모델 훈련(text-davinci-002)
Use this fine-tuned model to generate many more labels and expand your dataset by multiples
이 미세 조정된 모델을 사용하여 더 많은 레이블을 생성하고 데이터 세트를 배수로 확장하십시오.
Use this new dataset to train a cheaper model (ada)
이 새로운 데이터 세트를 사용하여 더 저렴한 모델(ada) 훈련
How to pick training hyperparameters
Fine-tuning can be adjusted with various parameters. Typically, the default parameters work well and adjustments only result in small performance changes.
미세 조정은 다양한 매개변수로 조정할 수 있습니다. 일반적으로 기본 매개변수는 잘 작동하며 조정해도 성능이 약간만 변경됩니다.
Parameter
Default
Recommendation
n_epochs
controls how many times each example is trained on
각 예제가 훈련되는 횟수를 제어합니다.
4
For classification, we’ve seen good performance with numbers like 4 or 10. Small datasets may need more epochs and large datasets may need fewer epochs.
분류의 경우 4 또는 10과 같은 숫자로 좋은 성능을 보였습니다. 작은 데이터 세트에는 더 많은 에포크가 필요할 수 있고 큰 데이터 세트에는 더 적은 에포크가 필요할 수 있습니다.
If you see low training accuracy, try increasing n_epochs. If you see high training accuracy but low validation accuracy (overfitting), try lowering n_epochs.
훈련 정확도가 낮은 경우 n_epochs를 늘려 보십시오. 훈련 정확도는 높지만 검증 정확도(과적합)가 낮은 경우 n_epochs를 낮추십시오.
You can get training and validation accuracies by setting compute_classification_metrics to True and passing a validation file with labeled examples not in the training data. You can see graphs of these metrics evolving during fine-tuning with a Weights & Biases account.
compute_classification_metrics를 True로 설정하고 교육 데이터에 없는 레이블이 지정된 예제가 있는 유효성 검사 파일을 전달하여 교육 및 유효성 검사 정확도를 얻을 수 있습니다. Weights & Biases 계정을 사용하여 미세 조정하는 동안 진화하는 이러한 지표의 그래프를 볼 수 있습니다.
batch_size controls the number of training examples used in a single training pass 단일 교육 패스에 사용되는 교육 예제의 수를 제어합니다.
null (which dynamically adjusts to 0.2% of training set, capped at 256) (트레이닝 세트의 0.2%로 동적으로 조정되며 256으로 제한됨)
We’ve seen good performance in the range of 0.01% to 2%, but worse performance at 5%+. In general, larger batch sizes tend to work better for larger datasets.
우리는 0.01%에서 2% 범위에서 좋은 성능을 보았지만 5% 이상에서는 더 나쁜 성능을 보였습니다. 일반적으로 더 큰 배치 크기는 더 큰 데이터 세트에서 더 잘 작동하는 경향이 있습니다.
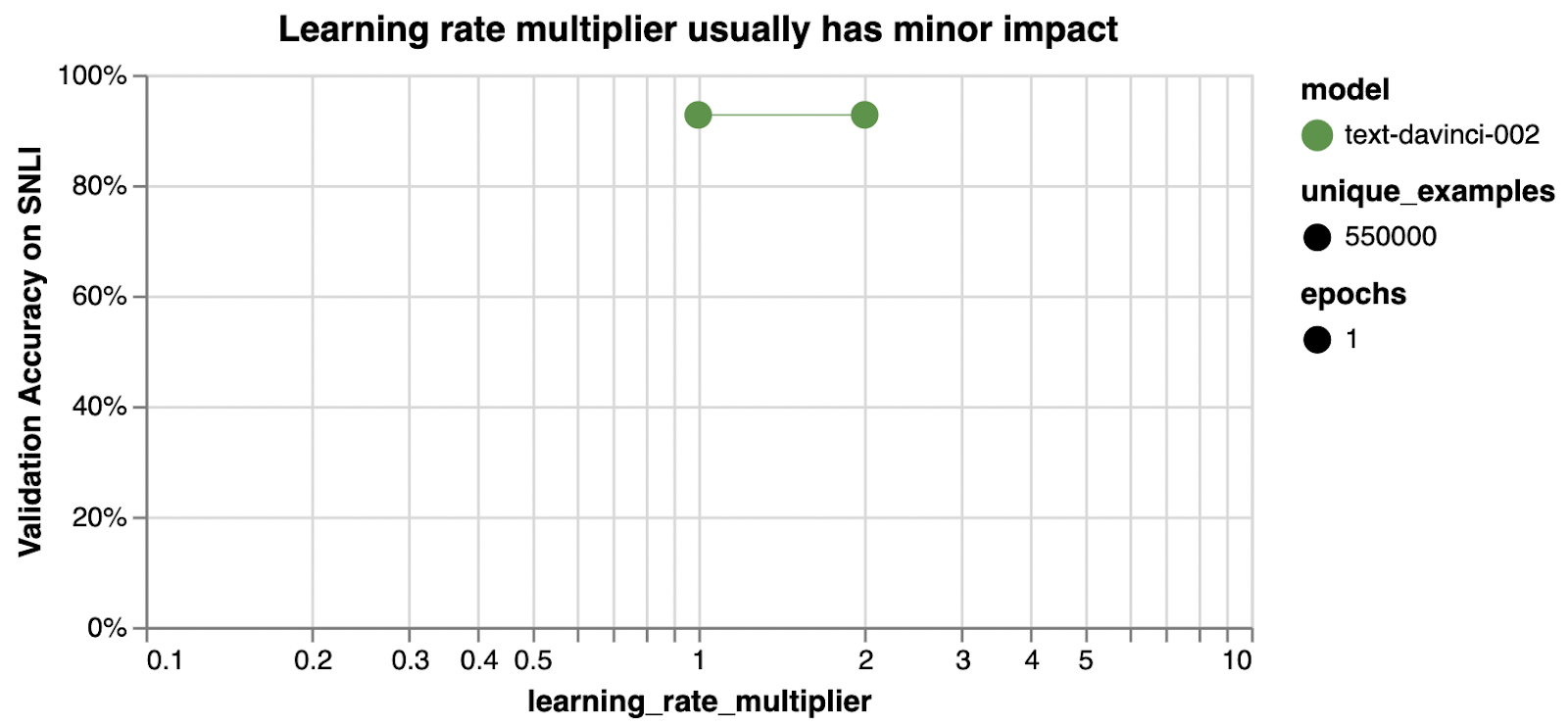
learning_rate_multiplier controls rate at which the model weights are updated 모델 가중치가 업데이트되는 속도를 제어합니다.
null (which dynamically adjusts to 0.05, 0.1, or 0.2 depending on batch size) (배치 크기에 따라 0.05, 0.1 또는 0.2로 동적으로 조정됨)
We’ve seen good performance in the range of 0.02 to 0.5. Larger learning rates tend to perform better with larger batch sizes.
0.02~0.5 범위에서 좋은 성능을 보였습니다. 더 큰 학습 속도는 더 큰 배치 크기에서 더 잘 수행되는 경향이 있습니다.
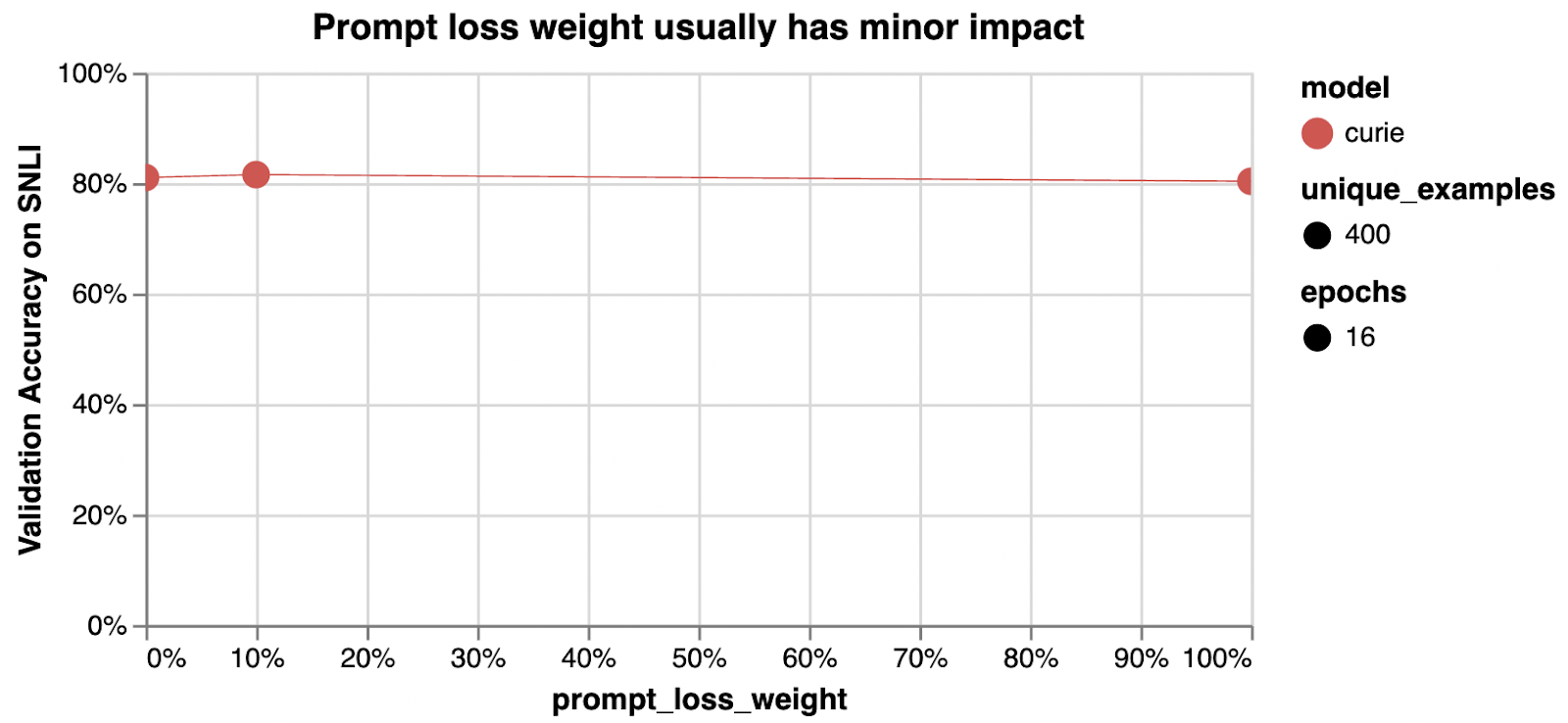
prompt_loss_weight controls how much the model learns from prompt tokens vs completion tokens 모델이 프롬프트 토큰과 완료 토큰에서 학습하는 양을 제어합니다.
0.1
If prompts are very long relative to completions, it may make sense to reduce this weight to avoid over-prioritizing learning the prompt. In our tests, reducing this to 0 is sometimes slightly worse or sometimes about the same, depending on the dataset.
프롬프트가 완료에 비해 매우 긴 경우 프롬프트 학습에 과도한 우선순위를 두지 않도록 이 가중치를 줄이는 것이 좋습니다. 테스트에서 데이터 세트에 따라 이를 0으로 줄이는 것이 때때로 약간 더 나쁘거나 거의 동일합니다.
More detail on prompt_loss_weight
When a model is fine-tuned, it learns to produce text it sees in both the prompt and the completion. In fact, from the point of view of the model being fine-tuned, the distinction between prompt and completion is mostly arbitrary. The only difference between prompt text and completion text is that the model learns less from each prompt token than it does from each completion token. This ratio is controlled by the prompt_loss_weight, which by default is 10%.
모델이 미세 조정되면 prompt and the completion 모두에 표시되는 텍스트를 생성하는 방법을 학습합니다. 실제로 미세 조정되는 모델의 관점에서 신속함과 완료의 구분은 대부분 임의적입니다. 프롬프트 텍스트와 완료 텍스트의 유일한 차이점은 모델이 각 완료 토큰에서 학습하는 것보다 각 프롬프트 토큰에서 학습하는 내용이 적다는 것입니다. 이 비율은 prompt_loss_weight에 의해 제어되며 기본적으로 10%입니다.
A prompt_loss_weight of 100% means that the model learns from prompt and completion tokens equally. In this scenario, you would get identical results with all training text in the prompt, all training text in the completion, or any split between them. For classification, we recommend against 100%.
100%의 prompt_loss_weight는 모델이 프롬프트 및 완료 토큰에서 동일하게 학습함을 의미합니다. 이 시나리오에서는 프롬프트의 모든 학습 텍스트, 완성의 모든 학습 텍스트 또는 이들 간의 분할에 대해 동일한 결과를 얻습니다. 분류의 경우 100% 대비를 권장합니다.
A prompt loss weight of 0% means that the model’s learning is focused entirely on the completion tokens. Note that even in this case, prompts are still necessary because they set the context for each completion. Sometimes we’ve seen a weight of 0% reduce classification performance slightly or make results slightly more sensitive to learning rate; one hypothesis is that a small amount of prompt learning helps preserve or enhance the model’s ability to understand inputs.
0%의 즉각적인 손실 가중치는 모델의 학습이 완료 토큰에 전적으로 집중되어 있음을 의미합니다. 이 경우에도 프롬프트는 각 완료에 대한 컨텍스트를 설정하기 때문에 여전히 필요합니다. 때때로 우리는 0%의 가중치가 분류 성능을 약간 감소시키거나 결과가 학습률에 약간 더 민감해지는 것을 보았습니다. 한 가지 가설은 소량의 즉각적인 학습이 입력을 이해하는 모델의 능력을 유지하거나 향상시키는 데 도움이 된다는 것입니다.
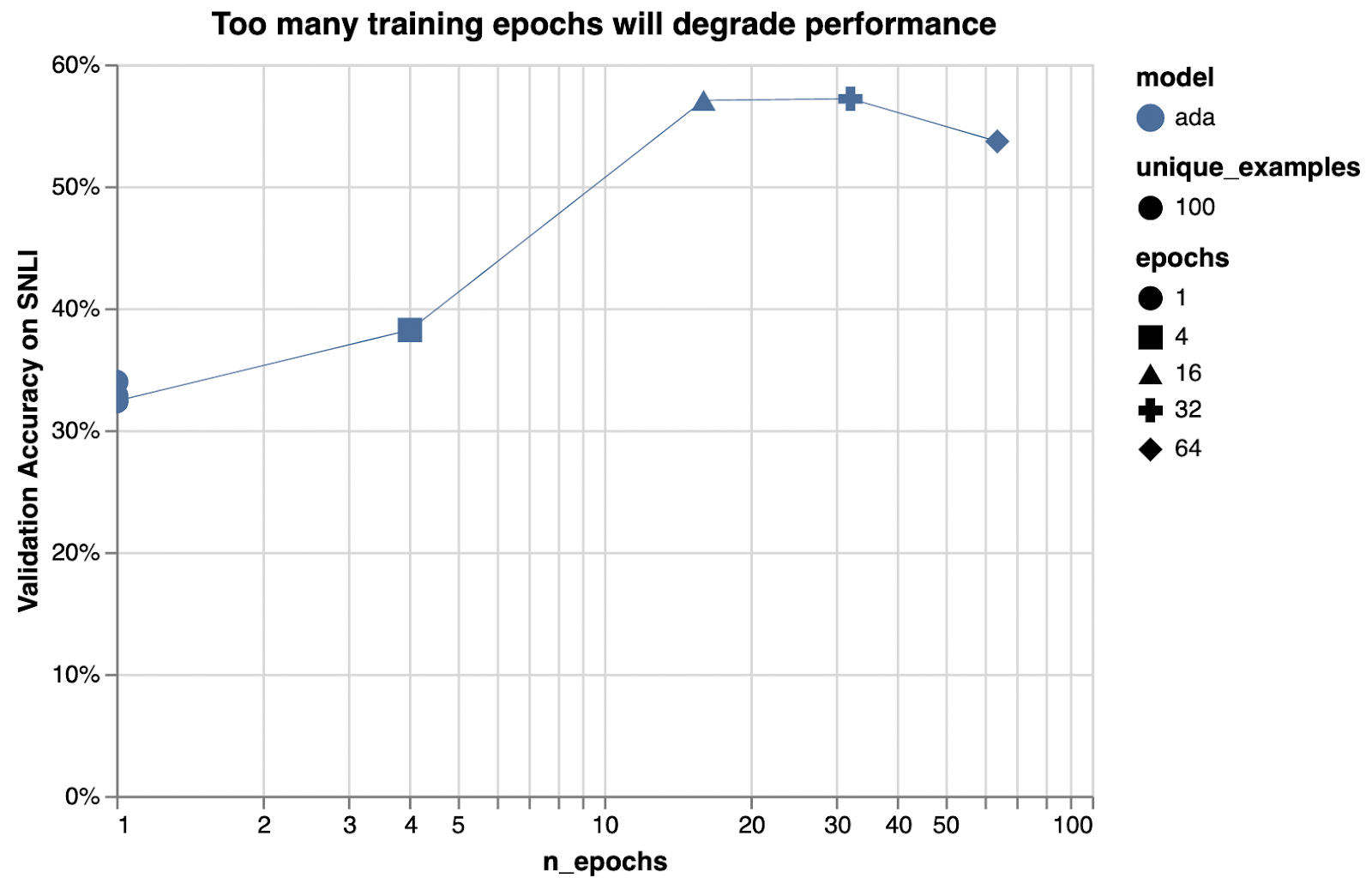
Example hyperparameter sweeps
n_epochs
The impact of additional epochs is particularly high here, because only 100 training examples were used.
100개의 학습 예제만 사용되었기 때문에 추가 에포크의 영향이 여기에서 특히 높습니다.
learning_rate_multiplier
prompt_loss_weight
How to pick inference parameters
Parameter
Recommendation
model
(discussed above) [add link]
temperature
Set temperature=0 for classification. Positive values add randomness to completions, which can be good for creative tasks but is bad for a short deterministic task like classification. 분류를 위해 온도=0으로 설정합니다. 양수 값은 완성에 임의성을 추가하므로 창의적인 작업에는 좋을 수 있지만 분류와 같은 짧은 결정론적 작업에는 좋지 않습니다.
max_tokens
If using single-token labels (or labels with unique first tokens), set max_tokens=1. If using longer labels, set to the length of your longest label. 단일 토큰 레이블(또는 고유한 첫 번째 토큰이 있는 레이블)을 사용하는 경우 max_tokens=1로 설정합니다. 더 긴 레이블을 사용하는 경우 가장 긴 레이블의 길이로 설정하십시오.
stop
If using labels of different length, you can optionally append a stop sequence like ‘ END’ to your training completions. Then, pass stop=‘ END’ in your inference call to prevent the model from generating excess text after appending short labels. (Otherwise, you can get completions like “burger -->” “ edible edible edible edible edible edible” as the model continues to generate output after the label is appended.) An alternative solution is to post-process the completions and look for prefixes that match any labels. 길이가 다른 레이블을 사용하는 경우 선택적으로 학습 완료에 ' END'와 같은 중지 시퀀스를 추가할 수 있습니다. 그런 다음 짧은 레이블을 추가한 후 모델이 과도한 텍스트를 생성하지 않도록 추론 호출에서 stop=' END'를 전달합니다. (그렇지 않으면 레이블이 추가된 후에도 모델이 계속 출력을 생성하므로 "burger -->" " edible edible edible edible edible"와 같은 완성을 얻을 수 있습니다.) 대체 솔루션은 완성을 후처리하고 접두사를 찾는 것입니다. 모든 레이블과 일치합니다.
logit_bias
If using single-token labels, set logit_bias={“label1”: 100, “label2”:100, …} with your labels in place of “label1” etc.
For tasks with little data or complex labels, models can output tokens for invented classes never specified in your training set. logit_bias can fix this by upweighting your label tokens so that illegal label tokens are never produced. If using logit_bias in conjunction with multi-token labels, take extra care to check how your labels are being split into tokens, as logit_bias only operates on individual tokens, not sequences.
데이터가 적거나 레이블이 복잡한 작업의 경우 모델은 훈련 세트에 지정되지 않은 발명된 클래스에 대한 토큰을 출력할 수 있습니다. logit_bias는 불법 레이블 토큰이 생성되지 않도록 레이블 토큰의 가중치를 높여 이 문제를 해결할 수 있습니다. 다중 토큰 레이블과 함께 logit_bias를 사용하는 경우 logit_bias는 시퀀스가 아닌 개별 토큰에서만 작동하므로 레이블이 토큰으로 분할되는 방식을 특히 주의하십시오.
Logit_bias can also be used to bias specific labels to appear more or less frequently. Logit_bias를 사용하여 특정 레이블이 더 자주 또는 덜 자주 표시되도록 바이어스할 수도 있습니다.
logprobs
Getting the probabilities of each label can be useful for computing confidence scores, precision-recall curves, calibrating debiasing using logit_bias, or general debugging. 각 레이블의 확률을 얻는 것은 신뢰도 점수 계산, 정밀도 재현 곡선, logit_bias를 사용한 편향성 보정 보정 또는 일반 디버깅에 유용할 수 있습니다.
Setting logprobs=5 will return, for each token position of the completion, the top 5 most likely tokens and the natural logs of their probabilities. To convert logprobs into probabilities, raise e to the power of the logprob (probability = e^logprob). The probabilities returned are independent of temperature and represent what the probability would have been if the temperature had been set to 1. By default 5 is the maximum number of logprobs returned, but exceptions can be requested by emailing support@openai.com and describing your use case.
logprobs=5로 설정하면 완료의 각 토큰 위치에 대해 가장 가능성이 높은 상위 5개 토큰과 해당 확률의 자연 로그가 반환됩니다. logprobs를 확률로 변환하려면 e를 logprob의 거듭제곱으로 올립니다(probability = e^logprob). 반환된 확률은 온도와 무관하며 온도가 1로 설정되었을 경우의 확률을 나타냅니다. 기본적으로 5는 반환되는 logprobs의 최대 수. 예외는 support@openai.com으로 이메일을 보내주세요 귀하의 사용 사례를 보내 주세요.
Example API call to get probabilities for the 5 most likely tokens 가능성이 가장 높은 5개의 토큰에 대한 확률을 얻기 위한 API 호출 예
api_response = openai.Completion.create( model="{fine-tuned model goes here, without brackets}", prompt="toothpaste -->", temperature=0, max_tokens=1, logprobs=5 ) dict_of_logprobs = api_response['choices'][0]['logprobs']['top_logprobs'][0].to_dict() dict_of_probs = {k: 2.718**v for k, v in dict_of_logprobs.items()}
echo
In cases where you want the probability of a particular label that isn’t showing up in the list of logprobs, the echo parameter is useful. If echo is set to True and logprobs is set to a number, the API response will include logprobs for every token of the prompt as well as the completion. So, to get the logprob for any particular label, append that label to the prompt and make an API call with echo=True, logprobs=0, and max_tokens=0.
logprobs 목록에 나타나지 않는 특정 레이블의 확률을 원하는 경우 echo 매개변수가 유용합니다. echo가 True로 설정되고 logprobs가 숫자로 설정되면 API 응답에는 완료뿐 아니라 프롬프트의 모든 토큰에 대한 logprobs가 포함됩니다. 따라서 특정 레이블에 대한 logprob를 가져오려면 해당 레이블을 프롬프트에 추가하고 echo=True, logprobs=0 및 max_tokens=0으로 API 호출을 수행합니다.
Example API call to get the logprobs of prompt tokens
For complex tasks that require reasoning, one useful technique you can experiment with is inserting explanations before the final answer. Giving the model extra time and space to think ‘aloud’ can increase the odds it arrives at the correct final answer.
추론이 필요한 복잡한 작업의 경우 실험할 수 있는 유용한 기술 중 하나는 최종 답변 앞에 설명을 삽입하는 것입니다. 모델에게 '큰 소리로' 생각할 수 있는 추가 시간과 공간을 제공하면 올바른 최종 답변에 도달할 가능성이 높아질 수 있습니다.
“Q: Where do you put your grapes just before checking out? Answer Choices: (a) mouth (b) grocery cart (c) supermarket (d) fruit basket (e) fruit market A:”
“(b)”
“The answer should be the place where grocery items are placed before checking out. Of the above choices, grocery cart makes the most sense for holding grocery items. Therefore, the answer is grocery cart (b).”
“답은 체크아웃하기 전에 식료품을 두는 장소여야 합니다. 위의 선택 중에서 식료품 카트는 식료품을 보관하는 데 가장 적합합니다. 따라서 정답은 식료품 카트(b)입니다.”
Although it can sound daunting to write many example explanations, it turns out you can use large language models to write the explanations. In 2022, Zelikman, Wu, et al. published a procedure called STaR (Self-Taught Reasoner) in which a few-shot prompt can be used to generate a set of {questions, rationales, answers} from just a set of {questions, answers}
많은 예제 설명을 작성하는 것이 어렵게 들릴 수 있지만 큰 언어 모델을 사용하여 설명을 작성할 수 있습니다. 2022년 Zelikman, Wu, et al. {질문, 답변} 세트에서 {질문, 근거, 답변} 세트를 생성하기 위해 몇 번의 프롬프트를 사용할 수 있는 STaR(Self-Taught Reasoner)라는 절차를 발표했습니다.
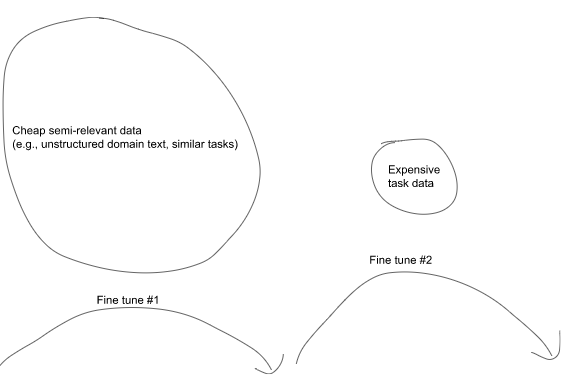
Sequential fine-tuning
Models can be fine-tuned sequentially as many times as you like. One way you can use this is to pre-train your model on a large amount of relevant text, such as unstructured domain text or similar classification tasks, and then afterwards fine-tune on examples of the task you want the model to perform. An example procedure could look like:
모델은 원하는 만큼 순차적으로 미세 조정할 수 있습니다. 이를 사용할 수 있는 한 가지 방법은 구조화되지 않은 도메인 텍스트 또는 유사한 분류 작업과 같은 많은 양의 관련 텍스트에 대해 모델을 사전 훈련한 다음 나중에 모델이 수행할 작업의 예를 미세 조정하는 것입니다. 예제 절차는 다음과 같습니다.
Step 1: Fine-tune on cheap, semi-relevant data
E.g., unstructured domain text (such as legal or medical text)
E.g., similar task data (such as another large classification set)
Step 2: Fine-tune on expensive labeled examples
E.g., text and classes (if training a classifier)
To fine-tune a previously fine-tuned model, pass in the fine-tuned model name when creating a new fine-tuning job (e.g. -m curie:ft-<org>-<date>). Other training parameters do not have to be changed, however if your new training data is much smaller than your previous training data, you may find it useful to reduce learning_rate_multiplier by a factor of 2 to 4.
이전에 미세 조정된 모델을 미세 조정하려면 새 미세 조정 작업을 생성할 때 미세 조정된 모델 이름을 전달합니다(예: -m curie:ft-<org>-<date>). 다른 훈련 매개변수는 변경할 필요가 없지만 새 훈련 데이터가 이전 훈련 데이터보다 훨씬 작은 경우 learning_rate_multiplier를 2~4배 줄이는 것이 유용할 수 있습니다.
Common mistakes
The most common mistakes when fine-tuning text classifiers are usually related to training data.
텍스트 분류기를 미세 조정할 때 가장 흔한 실수는 일반적으로 훈련 데이터와 관련이 있습니다.
Common mistake #1: Insufficiently specified training data
One thing to keep in mind is that training data is more than just a mapping of inputs to correct answers. Crucially, the inputs need to contain the information needed to derive an answer.
한 가지 명심해야 할 점은 교육 데이터가 정답에 대한 입력의 매핑 이상이라는 것입니다. 결정적으로 입력에는 답을 도출하는 데 필요한 정보가 포함되어야 합니다.
For example, consider fine-tuning a model to predict someone’s grades using the following dataset:
예를 들어 다음 데이터 세트를 사용하여 누군가의 성적을 예측하도록 모델을 미세 조정하는 것을 고려하십시오.
Prompt
Completion
“Alice >>>”
“ A”
“Bob >>>”
“ B+”
“Coco >>>”
“ A-”
“Dominic >>>”
“ B”
Prompt
Completion
“Esmeralda >>>”
???
Without knowing why these students got the grades they did, there is insufficient information for the model to learn from and no hope of making a good personalized prediction for Esmeralda.
이 학생들이 자신이 받은 성적을 받은 이유를 모르면 모델이 배울 수 있는 정보가 충분하지 않으며 Esmeralda에 대해 좋은 개인화된 예측을 할 수 있는 희망이 없습니다.
This can happen more subtly when some information is given but some is still missing. For example, if fine-tuning a classifier on whether a business expense is allowed or disallowed, and the business expense policy varies by date or by location or by employee type, make sure the input contains information on dates, locations, and employee type.
이것은 일부 정보가 제공되었지만 일부가 여전히 누락된 경우 더 미묘하게 발생할 수 있습니다. 예를 들어 비즈니스 비용이 허용되는지 여부에 대한 분류자를 미세 조정하고 비즈니스 비용 정책이 날짜, 위치 또는 직원 유형에 따라 달라지는 경우 입력에 날짜, 위치 및 직원 유형에 대한 정보가 포함되어 있는지 확인하십시오.
Prompt
Completion
“Amount: $50 Item: Steak dinner
###
”
“ allowed”
“Amount: $50 Item: Steak dinner
###
”
“ disallowed”
Prompt
Completion
“Amount: $50 Item: Steak dinner
###
”
???
Common mistake #2: Input data format that doesn’t match the training data format
Make sure that when you use your fine-tuned model, your submitted prompts match the format of your training data.
미세 조정된 모델을 사용할 때 제출된 프롬프트가 훈련 데이터의 형식과 일치하는지 확인하십시오.
Training data format
API call
OK?
“dog toy -->”
“dog toy”
❌Missing separator
“Amount: $50 Item: Steak dinner
###
”
“Is a $50 steak dinner allowed?
###
“
❌Different format
“Esmeralda >>>”
“Esmeralda >>> ”
❌Extra space appended
More examples
Below, we share more examples of training data for possible classifiers.
아래에서 가능한 분류기에 대한 훈련 데이터의 더 많은 예를 공유합니다.
Truthful consistency classifier
Prompt
Completion
"Company: BHFF insurance Product: allround insurance Ad: One stop shop for all your insurance needs! Supported:"
Product review classifier (with multiple classes labeled in parallel)
Prompt
Completion
"4/5 stars
Camera seems fine. Not amazing, but perfectly decent.
Biggest complaint is that the cable is only 5 feet long, which I didn't think to check. It's my fault, so I won't return it, but 5 feet is really short if you have multiple monitors and probably impossible if you have a desktop on the floor next to a standing desk.
###
Positives:"
“ fine, perfectly decent Negatives: not amazing, cable is only 5 feet long Overall sentiment: positive Possible improvements: longer cable Return risk: 1 Support priority: low Customer type: N/A”
"4/5 stars
I bought this on sale for $70. I'm satisfied with it.
(1) The instructions weren't that bad. (There was really only one ambiguous step, and it was easy to make an educated guess at the right way to go. Surprised by the ordering of one of the steps because some bars were hanging there for a while, but whatever.)
(2) It definitely is labor intensive - the most painful step is screwing in 24 small wood screws to get the hooks attached. And it takes a bit of skill to get them all vertically parallel. Got a big blister from all the screwing. And the angles made it hard to use power tools - ended up screwing in by hand because it was easier to stay vertical next to the hook.
(3) I weight 170 pounds and honestly the bench seems fine for supporting my weight. I was worried from the other reviews. But my trick was to leave things a little loose until the end and then really tighten everything once it was all together. I think really tightening at the end prevents any squeaky rocking. But only used it one day so far, so we'll see.
Overall this is definitely cheap, but feels totally fine. It's cheap in a cheap way, not cheap in a junky knockoff way. Would buy again. Looks great.
###
Positives:"
“ instructions weren’t that bad, looks great Negatives: ambiguous step, labor intensive, got a big blister, cheap Overall sentiment: positive Possible improvements: less ambiguous instructions Return risk: 0 Support priority: low Customer type: N/A”
"5/5 stars
I'm a fan. It's shiny and pure metal. Exactly what I wanted.
###
Positives:”
“ shiny, pure metal Negatives: N/A Overall sentiment: positive Possible improvements: N/A Return risk: 0 Support priority: low Customer type: N/A
Sentiment analyzer
Prompt
Completion
"Overjoyed with the new iPhone! ->"
“ positive”
"@lakers disappoint for a third straight night https://t.co/38EFe43 ->"
“ negative”
Email prioritizer
Prompt
Completion
"Subject: Update my address From: Joe Doe To: support@ourcompany.com Date: 2021-06-03 Content: Hi, I would like to update my billing address to match my delivery address.
Please let me know once done.
Thanks, Joe
###
"
“ 4”
Legal claim detector
Prompt
Completion
"When the IPV (injection) is used, 90% or more of individuals develop protective antibodies to all three serotypes of polio virus after two doses of inactivated polio vaccine (IPV), and at least 99% are immune to polio virus following three doses. -->"
“ efficacy”
"Jonas Edward Salk (/sɔːlk/; born Jonas Salk; October 28, 1914 – June 23, 1995) was an American virologist and medical researcher who developed one of the first successful polio vaccines. He was born in New York City and attended the City College of New York and New York University School of Medicine. -->"
“ not”
News subject detector
Prompt
Completion
"PC World - Upcoming chip set will include built-in security features for your PC. >>>"
“ 4”
(where 4 = Sci/Tech)
“Newspapers in Greece reflect a mixture of exhilaration that the Athens Olympics proved successful, and relief that they passed off without any major setback. >>>”
“ 2”
(where 2 = Sports)
Logical relationship detector
Prompt
Completion
"A land rover is being driven across a river. A vehicle is crossing a river.
###
"
“ implication”
"Violin soloists take the stage during the orchestra's opening show at the theater. People are playing the harmonica while standing on a roof.
{
"text": "Imagine the wildest idea that you've ever had, and you're curious about how it might scale to something that's a 100, a 1,000 times bigger. This is a place where you can get to do that."
}
Request body
file
string Required
The audio file to transcribe, in one of these formats: mp3, mp4, mpeg, mpga, m4a, wav, or webm.
문자로 변환 하게 될 오디오 파일 입니다. mp3, mp4, mpeg, mpga, m4a, wav 또는 webm 형식 중 하나 이어야 합니다.
model
string Required
ID of the model to use. Onlywhisper-1is currently available.
사용할 모델의 ID입니다. 현재 whisper-1 모델만 사용할 수 있습니다.
prompt
string Optional
An optional text to guide the model's style or continue a previous audio segment. Thepromptshould match the audio language.
모델의 스타일을 안내하거나 이전 오디오 세그먼트를 계속하는 선택적 텍스트입니다. 프롬프트는 오디오 언어와 일치해야 합니다.
response_format
string Optional Defaults tojson
The format of the transcript output, in one of these options: json, text, srt, verbose_json, or vtt.
필사한 값의 output format입니다. json, text, srt, verbose_json 또는 vtt 포맷 중 하나 입니다.
temperature
number Optional Defaults to0
The sampling temperature, between 0 and 1. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. If set to 0, the model will uselog probabilityto automatically increase the temperature until certain thresholds are hit.
샘플링 온도는 0에서 1 사이입니다. 0.8과 같이 값이 높을수록 출력이 더 무작위적으로 생성되고 0.2와 같이 값이 낮을수록 더 집중되고 결정적입니다. 0으로 설정하면 모델은 로그 확률을 사용하여 특정 임계값에 도달할 때까지 자동으로 temperature를 높입니다.
language
string Optional
The language of the input audio. Supplying the input language inISO-639-1format will improve accuracy and latency.
입력 오디오의 언어입니다. ISO-639-1 형식으로 입력 언어를 제공하면 정확도와 대기 시간이 향상됩니다.
{
"text": "Hello, my name is Wolfgang and I come from Germany. Where are you heading today?"
}
Request body
file
string Required
The audio file to translate, in one of these formats: mp3, mp4, mpeg, mpga, m4a, wav, or webm.
문자로 변환 하게 될 오디오 파일 입니다. mp3, mp4, mpeg, mpga, m4a, wav 또는 webm 형식 중 하나 이어야 합니다.
model
string Required
ID of the model to use. Onlywhisper-1is currently available.
사용할 모델의 ID입니다. 현재 whisper-1 모델만 사용할 수 있습니다.
prompt
string Optional
An optional text to guide the model's style or continue a previous audio segment. Thepromptshould be in English.
모델의 스타일을 안내하거나 이전 오디오 세그먼트를 계속하는 선택적 텍스트입니다. 프롬프트는 오디오 언어와 일치해야 합니다.
response_format
string Optional Defaults tojson
The format of the transcript output, in one of these options: json, text, srt, verbose_json, or vtt.
transcript output 의 포맷입니다. json, text, srt, verbose_json 또는 vtt 포맷 중 하나 입니다.
temperature
number Optional Defaults to0
The sampling temperature, between 0 and 1. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. If set to 0, the model will uselog probabilityto automatically increase the temperature until certain thresholds are hit.
샘플링 온도는 0에서 1 사이입니다. 0.8과 같이 값이 높을수록 출력이 더 무작위적으로 생성되고 0.2와 같이 값이 낮을수록 더 집중되고 결정적입니다. 0으로 설정하면 모델은 로그 확률을 사용하여 특정 임계값에 도달할 때까지 자동으로temperature를 높입니다.
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "\n\nHello there, how may I assist you today?",
},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}
Request body
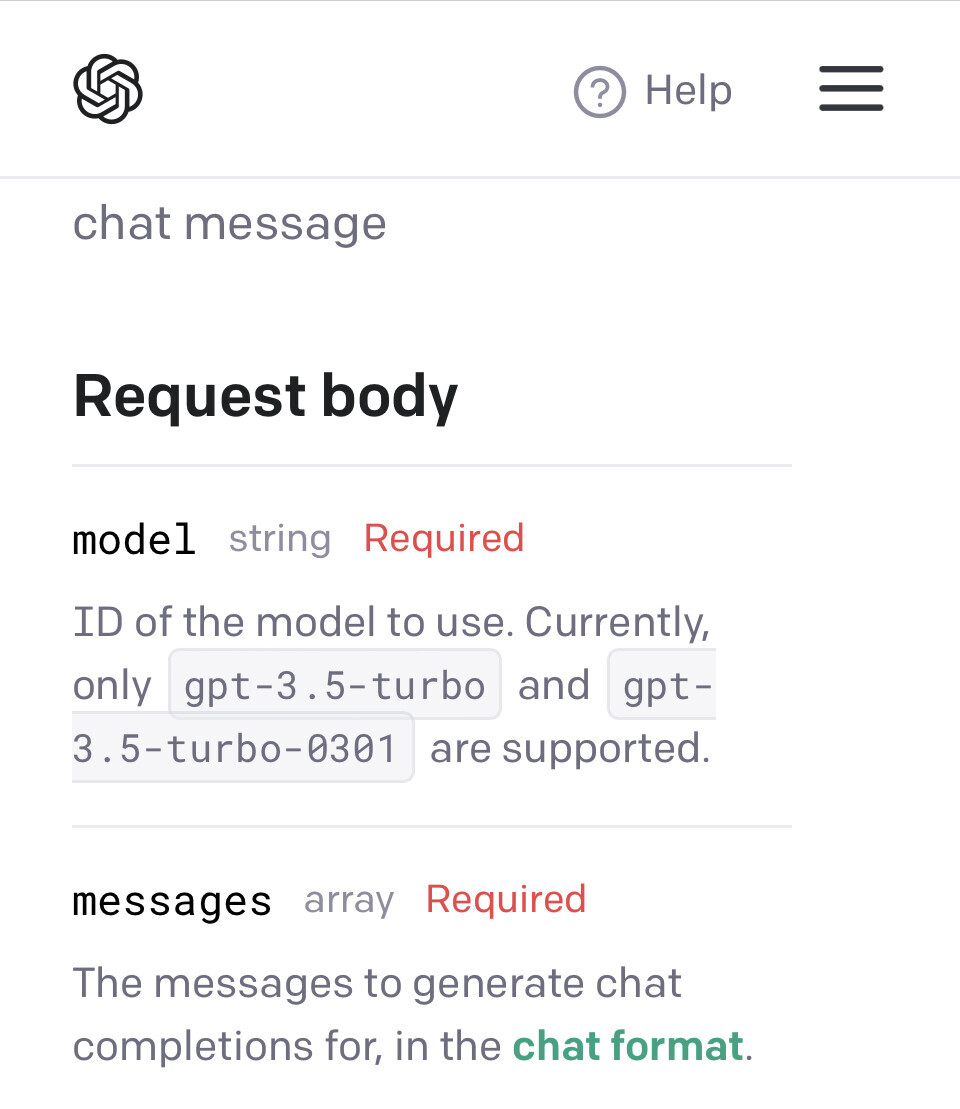
model
string Required
ID of the model to use. Currently, onlygpt-3.5-turboandgpt-3.5-turbo-0301are supported.
사용할 모델의 ID입니다. 현재 gpt-3.5-turbo 및 gpt-3.5-turbo-0301만 지원됩니다.
messages
array Required
The messages to generate chat completions for, in thechat format.
채팅 형식으로 chat completions를 생성할 메시지입니다.
temperature
number Optional Defaults to1
What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
0과 2 사이에서 사용할 샘플링 온도. 0.8과 같은 높은 값은 출력을 더 무작위로 만들고 0.2와 같은 낮은 값은 더 집중적이고 결정적으로 만듭니다.
We generally recommend altering this ortop_pbut not both.
이 값이나 top_p 값을 변경할 수 있는데 두가지를 한꺼번에 변경하는 것은 권장하지 않습니다.
top_p
number Optional Defaults to1
An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.
Temperature 의 대안 방법 입니다. ,nucleus 샘플링 이라고 합니다. 모델은 top_p probability mass 와 관련 된 토큰의 결과들을 고려하게 됩니다. 즉 0.1 값을 갖게 되면 상의 10%의 probability mass (확률량)를 구성하는 토큰만 고려된다는 것을 의미합니다.
We generally recommend altering this ortemperaturebut not both.
이 값이나 temperature 값을 변경할 수 있는데 두가지를 한꺼번에 변경하는 것은 권장하지 않습니다.
n
integer Optional Defaults to1
How many chat completion choices to generate for each input message.
각 입력 메시지에 대해 생성하기 위한 chat completion choices 는 얼마나 많이 있는지를 나타냄
stream
boolean Optional Defaults tofalse
If set, partial message deltas will be sent, like in ChatGPT. Tokens will be sent as data-onlyserver-sent eventsas they become available, with the stream terminated by adata: [DONE]message.
True로 설정하면 ChatGPT에서와 같이 부분 메시지(델타)가 전송됩니다. 토큰은 사용 가능해지면 데이터 전용 서버 전송 이벤트로 전송되며, 스트림은 data: [DONE] 메시지로 종료됩니다.
stop
string or array Optional Defaults tonull
Up to 4 sequences where the API will stop generating further tokens.
API가 추가 토큰 생성을 중지하는 최대 4개의 시퀀스.
max_tokens
integer Optional Defaults toinf
The maximum number of tokens allowed for the generated answer. By default, the number of tokens the model can return will be (4096 - prompt tokens).
생성된 답변에 허용되는 최대 토큰 수입니다. 기본적으로 모델이 반환할 수 있는 토큰 수는 (4096 - 프롬프트 토큰)입니다.
presence_penalty
number Optional Defaults to0
Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model's likelihood to talk about new topics.
-2.0에서 2.0 사이의 숫자입니다. 양수 값은 지금까지 텍스트에 나타나는지 여부에 따라 새 토큰에 페널티를 주어 모델이 새 주제에 대해 이야기할 가능성을 높입니다.
Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model's likelihood to repeat the same line verbatim.
-2.0에서 2.0 사이의 숫자입니다. 양수 값은 지금까지 텍스트의 기존 빈도를 기반으로 새 토큰에 페널티를 주어 모델이 동일한 줄을 그대로 반복할 가능성을 줄입니다.
Modify the likelihood of specified tokens appearing in the completion.
completion에 지정된 토큰이 나타날 가능성을 수정합니다.
Accepts a json object that maps tokens (specified by their token ID in the tokenizer) to an associated bias value from -100 to 100. Mathematically, the bias is added to the logits generated by the model prior to sampling. The exact effect will vary per model, but values between -1 and 1 should decrease or increase likelihood of selection; values like -100 or 100 should result in a ban or exclusive selection of the relevant token.
토큰(토크나이저의 토큰 ID로 지정됨)을 -100에서 100까지의 관련 바이어스 값에 매핑하는 json 개체를 accept합니다. 수학적으로 바이어스는 샘플링 전에 모델에서 생성된 로짓에 추가됩니다. 정확한 효과는 모델마다 다르지만 -1과 1 사이의 값은 선택 가능성을 낮추거나 높여야 합니다. -100 또는 100과 같은 값은 관련 토큰을 금지하거나 배타적으로 선택해야 합니다.
user
string Optional
A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse.Learn more.
OpenAI가 남용을 모니터링하고 탐지하는 데 도움이 될 수 있는 최종 사용자를 나타내는 고유 식별자입니다.
Starting on March 1, 2023, we are making two changes to our data usage and retention policies:
2023년 3월 1일부터 데이터 사용 및 보존 정책에 두 가지 변경 사항이 적용됩니다.
OpenAI will not use data submitted by customers via our API to train or improve our models, unless you explicitly decide to share your data with us for this purpose. You canopt-in to share data.
OpenAI는 귀하가 어떠한 목적으로 귀하의 데이터를 당사와 공유하기로 명시적으로 결정하지 않는 한 당사 API를 통해 고객이 제출한 데이터를 사용하여 모델을 교육하거나 개선하지 않습니다. 귀하는 데이터 공유를 선택할 수도 있습니다. opt-in to share data
Any data sent through the API will be retained for abuse and misuse monitoring purposes for a maximum of 30 days, after which it will be deleted (unless otherwise required by law).
API를 통해 전송된 모든 데이터는 남용 및 오용 모니터링 목적으로 최대 30일 동안 보관되며 그 이후에는 삭제됩니다(법률에서 달리 요구하지 않는 한).
The OpenAI API processes user prompts and completions, as well as training data submitted to fine-tune models via the Files endpoint. We refer to this data as API data.
OpenAI API는 Files endpoint를 통해 fine-tune 모델에 제출된 교육 데이터뿐만 아니라 사용자 프롬프트 및 completions을 처리합니다. 이 때 사용 되는 데이터를 API 데이터라고 합니다.
By default, OpenAI will not use data submitted by customers via our API to train OpenAI models or improve OpenAI’s service offering. Data submitted by the user for fine-tuning will only be used to fine-tune the customer's model. However, OpenAI will allow users to opt-in to share their data toimprove model performance.Sharing your datawill ensure that future iterations of the model improve for your use cases. Data submitted to the API prior to March 1, 2023 (the effective date of this change) may have been used for improvements if the customer had not previously opted out of sharing data.
기본적으로 OpenAI는 API를 통해 고객이 제출한 데이터를 사용하여 OpenAI 모델을 교육하거나 OpenAI의 서비스 제공을 개선하지 않습니다. fine-tune을 위해 사용자가 제출한 데이터는 고객의 모델을 fine-tune하는 데만 사용됩니다. 그러나 OpenAI는 사용자가 데이터 공유를 선택하여 모델 성능을 향상시킬 수 있도록 하는 기회도 제공 합니다. 데이터를 공유하면 모델의 향후 반복이 사용 사례에 맞게 개선됩니다. 2023년 3월 1일(이 변경 발효일) 이전에 API에 제출된 데이터는 고객이 이전에 데이터 공유를 거부하지 않은 경우 개선을 위해 사용되었을 수 있습니다.
OpenAI retains API data for 30 days for abuse and misuse monitoring purposes. A limited number of authorized OpenAI employees, as well as specialized third-party contractors that are subject to confidentiality and security obligations, can access this data solely to investigate and verify suspected abuse. Enterprise customers deploying use cases with low likelihood of misuse may request to not have API data stored at all, including for safety monitoring and prevention. OpenAI may still have content classifiers flag when data is suspected to contain platform abuse. Data submitted by the user through the Files endpoint, for instance to fine-tune a model, is retained until the userdeletes the file.
OpenAI는 남용 및 오용 모니터링 목적으로 API 데이터를 30일 동안 보관합니다. 제한된 수의 승인된 OpenAI 직원과 기밀 유지 및 보안 의무가 적용되는 전문 제3자 계약자는 의심되는 남용을 조사하고 확인하기 위해서만 이 데이터에 액세스할 수 있습니다. 오용 가능성이 낮은 사용 사례를 배포하는 기업 고객은 안전 모니터링 및 예방을 포함하여 API 데이터를 전혀 저장하지 않도록 요청할 수 있습니다. 데이터에 플랫폼 남용이 포함된 것으로 의심되는 경우 OpenAI에 여전히 콘텐츠 분류 플래그가 있을 수 있습니다. 예를 들어 모델 미세 조정을 위해 파일 엔드포인트를 통해 사용자가 제출한 데이터는 사용자가 파일을 삭제할 때까지 유지됩니다.
OpenAI는 SOC 2 Type 1을 준수하며 2017 보안에 대한 신뢰 서비스 기준에 대해 독립적인 제3자 감사 기관의 감사를 받았습니다.
Where is API data stored?
Content is stored on OpenAI systems and our sub-processors’ systems. We may also send select portions of de-identified content to third-party contractors (subject to confidentiality and security obligations) safety purposes. Our 30-day data retention policy also applies to our sub-processors and contractors. You can view ourlist of sub-processors and their locationsfor details.
콘텐츠는 OpenAI 시스템과 하위 프로세서 시스템에 저장됩니다. 또한 당사는 안전 목적으로 비식별화된 콘텐츠의 일부를 제3자 계약자에게 보낼 수도 있습니다(기밀 유지 및 보안 의무 적용). 당사의 30일 데이터 보존 정책은 하도급 프로세서 및 계약자에게도 적용됩니다. 자세한 내용은 하위 프로세서 목록과 위치를 볼 수 있습니다.
When I call the API, is the data encrypted in transit?
The OpenAI API is only available over Transport Layer Security (TLS), and therefore customer-to-OpenAI requests and responses are encrypted.
OpenAI API는 TLS(Transport Layer Security)를 통해서만 사용할 수 있으므로 고객-OpenAI 요청 및 응답이 암호화됩니다.
Do you have a European data center?
All customer data is processed and stored in the US. We do not currently store data in Europe or in other countries.
모든 고객 데이터는 미국에서 처리되고 저장됩니다. 당사는 현재 유럽 또는 기타 국가에 데이터를 저장하지 않습니다.
Can I use the API for HIPAA workloads?
We are able to sign Business Associate Agreements in support of customers’ compliance with the Health Insurance Portability and Accountability Act (HIPAA). To qualify for this, you must have an Enterprise Agreement with OpenAI and a qualifying use case. Pleasereach out to our sales teamif you are interested.
우리는 고객이 HIPAA(Health Insurance Portability and Accountability Act)를 준수하도록 지원하는 사업 제휴 계약에 서명할 수 있습니다. 이에 대한 자격을 얻으려면 OpenAI와의 기업 계약 및 적격 사용 사례가 있어야 합니다. 관심이 있으시면 영업팀에 문의하십시오.
I’ve received a data deletion request, how do I ask OpenAI to delete data?
We only retain data sent through the API for up to 30 days for abuse and monitoring purposes. If you would like to delete your account before then, pleasefollow these steps.
악용 및 모니터링 목적으로 최대 30일 동안 API를 통해 전송된 데이터만 보관합니다. 그 전에 계정을 삭제하려면 다음 단계를 따르세요. follow these steps
Does OpenAI have a Data Processing Addendum (DPA)?
Yes. Please complete ourDPA formto execute our Data Processing Addendum.
저는 OpenAI Cookbook을 공부하다가 3월 1일 ChatGPT API 와 speech to text 모델인 Whisper 가 공개 되면서 여러가지 업데이트가 많이 돼서 잠깐 그 업데이트들을 살펴 보고 있습니다.
이 업데이트들을 다 살펴 본 후 다시 OpenAI Cookbook을 공부하고 그 다음에 Examples gallery 에 있는 예제들을 분석해 볼 예정입니다.
그 다음 여건이 되면 개인 프로젝트를 하고 싶은데.... 아직 희망사항이구요.
이번 업데이트는 Get Started, Guides 그리고 API Reference 에 많은 페이지들이 추가 됐구요 그 중 Guides 에 추가 된 Chat completion, Speech to text, Rate limit 그리고 Error codes 페이지는 다 살펴 보았습니다.
How to build an AI that can answer questions about your website
This tutorial walks through a simple example of crawling a website (in this example, the OpenAI website), turning the crawled pages into embeddings using theEmbeddings API, and then creating a basic search functionality that allows a user to ask questions about the embedded information. This is intended to be a starting point for more sophisticated applications that make use of custom knowledge bases.
이 튜토리얼에서는 웹사이트(이 예에서는 OpenAI 웹사이트)를 크롤링하고 Embeddings API를 사용하여 크롤링된 페이지를 임베딩으로 변환한 다음 사용자가 임베디드 정보에 대해 질문할 수 있는 기본 검색 기능을 생성하는 간단한 예제를 안내합니다. . 이는 custom knowledge bases를 사용하는 보다 정교한 애플리케이션 개발의 첫 발걸음을 어떻게 떼어야 하는지 보여드릴 것입니다..
Getting started
Some basic knowledge of Python and GitHub is helpful for this tutorial. Before diving in, make sure toset up an OpenAI API keyand walk through thequickstart tutorial. This will give a good intuition on how to use the API to its full potential.
Python 및 GitHub에 대한 기본 지식이 이 자습서를 공부하는데 도움이 됩니다. 시작하기 전에 OpenAI API 키를 설정하고 quickstart tutorial를 살펴보십시오. 이렇게 하면 API를 최대한 활용하는 방법에 대한 좋은 직관을 얻을 수 있습니다.
Python is used as the main programming language along with the OpenAI, Pandas, transformers, NumPy, and other popular packages. If you run into any issues working through this tutorial, please ask a question on theOpenAI Community Forum.
Python은 OpenAI, Pandas, 변환기, NumPy 및 기타 널리 사용되는 패키지와 함께 기본 프로그래밍 언어로 사용됩니다. 이 튜토리얼을 진행하면서 문제가 발생하면 OpenAI Community Forum에서 질문하십시오.
To start with the code, clone thefull code for this tutorial on GitHub. Alternatively, follow along and copy each section into a Jupyter notebook and run the code step by step, or just read along. A good way to avoid any issues is to set up a new virtual environment and install the required packages by running the following commands:
코드로 시작하려면 GitHub에서 이 자습서의 전체 코드를 복제하세요. 또는 따라가서 각 섹션을 Jupyter 노트북에 복사하고 코드를 단계별로 실행하세요. 그런 시간이 없으면 그냥 이 페이지를 읽어 보시기만 하셔도 됩니다. 문제를 피하는 좋은 방법은 다음 명령을 실행하여 새 가상 환경을 설정하고 필요한 패키지를 설치하는 것입니다.
The primary focus of this tutorial is the OpenAI API so if you prefer, you can skip the context on how to create a web crawler and justdownload the source code. Otherwise, expand the section below to work through the scraping mechanism implementation.
이 자습서의 주요 초점은 OpenAI API이므로 원하는 경우 웹 크롤러를 만드는 방법에 대한 컨텍스트를 건너뛰고 소스 코드를 다운로드할 수 있습니다. 그렇지 않으면 아래 섹션을 확장하여 스크래핑 메커니즘 구현을 통해 작업하십시오.
Learn how to build a web crawler
Acquiring data in text form is the first step to use embeddings. This tutorial creates a new set of data by crawling the OpenAI website, a technique that you can also use for your own company or personal website.
임베딩을 사용하기 위한 첫 번째 단계는 텍스트 형태로 데이터를 수집하는 것입니다. 이 자습서에서는 회사 또는 개인 웹 사이트에도 사용할 수 있는 기술인 OpenAI 웹 사이트를 크롤링하여 새로운 데이터 집합을 만듭니다.
While this crawler is written from scratch, open source packages likeScrapycan also help with these operations.
이 크롤러는 처음부터 작성되었지만 Scrapy와 같은 오픈 소스 패키지도 이러한 작업에 도움이 될 수 있습니다.
This crawler will start from the root URL passed in at the bottom of the code below, visit each page, find additional links, and visit those pages as well (as long as they have the same root domain). To begin, import the required packages, set up the basic URL, and define a HTMLParser class.
이 크롤러는 아래 코드 하단에 전달된 루트 URL에서 시작하여 각 페이지를 방문하고 추가 링크를 찾고 해당 페이지도 방문합니다(루트 도메인이 동일한 경우). 시작하려면 필요한 패키지를 가져오고 기본 URL을 설정하고 HTMLParser 클래스를 정의합니다.
import requests
import re
import urllib.request
from bs4 import BeautifulSoup
from collections import deque
from html.parser import HTMLParser
from urllib.parse import urlparse
import os
# Regex pattern to match a URL
HTTP_URL_PATTERN = r'^http[s]*://.+'
domain = "openai.com" # <- put your domain to be crawled
full_url = "https://openai.com/" # <- put your domain to be crawled with https or http
# Create a class to parse the HTML and get the hyperlinks
class HyperlinkParser(HTMLParser):
def __init__(self):
super().__init__()
# Create a list to store the hyperlinks
self.hyperlinks = []
# Override the HTMLParser's handle_starttag method to get the hyperlinks
def handle_starttag(self, tag, attrs):
attrs = dict(attrs)
# If the tag is an anchor tag and it has an href attribute, add the href attribute to the list of hyperlinks
if tag == "a" and "href" in attrs:
self.hyperlinks.append(attrs["href"])
다음 함수는 URL을 인수로 사용하여 URL을 열고 HTML 콘텐츠를 읽습니다. 그런 다음 해당 페이지에서 찾은 모든 하이퍼링크를 반환합니다.
# Function to get the hyperlinks from a URL
def get_hyperlinks(url):
# Try to open the URL and read the HTML
try:
# Open the URL and read the HTML
with urllib.request.urlopen(url) as response:
# If the response is not HTML, return an empty list
if not response.info().get('Content-Type').startswith("text/html"):
return []
# Decode the HTML
html = response.read().decode('utf-8')
except Exception as e:
print(e)
return []
# Create the HTML Parser and then Parse the HTML to get hyperlinks
parser = HyperlinkParser()
parser.feed(html)
return parser.hyperlinks
The goal is to crawl through and index only the content that lives under the OpenAI domain. For this purpose, a function that calls theget_hyperlinksfunction but filters out any URLs that are not part of the specified domain is needed.
목표는 OpenAI 도메인에 있는 콘텐츠만 크롤링하고 인덱싱하는 것입니다. 이를 위해서는 get_hyperlinks 함수를 호출하되 지정된 도메인에 속하지 않는 URL을 필터링하는 함수가 필요합니다.
# Function to get the hyperlinks from a URL that are within the same domain
def get_domain_hyperlinks(local_domain, url):
clean_links = []
for link in set(get_hyperlinks(url)):
clean_link = None
# If the link is a URL, check if it is within the same domain
if re.search(HTTP_URL_PATTERN, link):
# Parse the URL and check if the domain is the same
url_obj = urlparse(link)
if url_obj.netloc == local_domain:
clean_link = link
# If the link is not a URL, check if it is a relative link
else:
if link.startswith("/"):
link = link[1:]
elif link.startswith("#") or link.startswith("mailto:"):
continue
clean_link = "https://" + local_domain + "/" + link
if clean_link is not None:
if clean_link.endswith("/"):
clean_link = clean_link[:-1]
clean_links.append(clean_link)
# Return the list of hyperlinks that are within the same domain
return list(set(clean_links))
Thecrawlfunction is the final step in the web scraping task setup. It keeps track of the visited URLs to avoid repeating the same page, which might be linked across multiple pages on a site. It also extracts the raw text from a page without the HTML tags, and writes the text content into a local .txt file specific to the page.
크롤링 기능은 웹 스크래핑 작업 설정의 마지막 단계입니다. 사이트의 여러 페이지에 연결될 수 있는 동일한 페이지를 반복하지 않도록 방문한 URL을 추적합니다. 또한 HTML 태그가 없는 페이지에서 원시 텍스트를 추출하고 텍스트 콘텐츠를 페이지 고유의 로컬 .txt 파일에 기록합니다.
def crawl(url):
# Parse the URL and get the domain
local_domain = urlparse(url).netloc
# Create a queue to store the URLs to crawl
queue = deque([url])
# Create a set to store the URLs that have already been seen (no duplicates)
seen = set([url])
# Create a directory to store the text files
if not os.path.exists("text/"):
os.mkdir("text/")
if not os.path.exists("text/"+local_domain+"/"):
os.mkdir("text/" + local_domain + "/")
# Create a directory to store the csv files
if not os.path.exists("processed"):
os.mkdir("processed")
# While the queue is not empty, continue crawling
while queue:
# Get the next URL from the queue
url = queue.pop()
print(url) # for debugging and to see the progress
# Save text from the url to a <url>.txt file
with open('text/'+local_domain+'/'+url[8:].replace("/", "_") + ".txt", "w", encoding="UTF-8") as f:
# Get the text from the URL using BeautifulSoup
soup = BeautifulSoup(requests.get(url).text, "html.parser")
# Get the text but remove the tags
text = soup.get_text()
# If the crawler gets to a page that requires JavaScript, it will stop the crawl
if ("You need to enable JavaScript to run this app." in text):
print("Unable to parse page " + url + " due to JavaScript being required")
# Otherwise, write the text to the file in the text directory
f.write(text)
# Get the hyperlinks from the URL and add them to the queue
for link in get_domain_hyperlinks(local_domain, url):
if link not in seen:
queue.append(link)
seen.add(link)
crawl(full_url)
The last line of the above example runs the crawler which goes through all the accessible links and turns those pages into text files. This will take a few minutes to run depending on the size and complexity of your site.
위 예제의 마지막 줄은 크롤러를 실행하여 액세스 가능한 모든 링크를 통과하고 해당 페이지를 텍스트 파일로 변환합니다. 사이트의 크기와 복잡성에 따라 실행하는 데 몇 분 정도 걸립니다.
Building an embeddings index
CSV is a common format for storing embeddings. You can use this format with Python by converting the raw text files (which are in the text directory) into Pandas data frames. Pandas is a popular open source library that helps you work with tabular data (data stored in rows and columns).
CSV는 임베딩을 저장하기 위한 일반적인 형식입니다. 원시 텍스트 파일(텍스트 디렉터리에 있음)을 Pandas 데이터 프레임으로 변환하여 Python에서 이 형식을 사용할 수 있습니다. Pandas는 테이블 형식 데이터(행과 열에 저장된 데이터)로 작업하는 데 도움이 되는 인기 있는 오픈 소스 라이브러리입니다.
Blank empty lines can clutter the text files and make them harder to process. A simple function can remove those lines and tidy up the files.
비어 있는 빈 줄은 텍스트 파일을 복잡하게 만들고 처리하기 어렵게 만들 수 있습니다. 간단한 기능으로 해당 줄을 제거하고 파일을 정리할 수 있습니다.
def remove_newlines(serie):
serie = serie.str.replace('\n', ' ')
serie = serie.str.replace('\\n', ' ')
serie = serie.str.replace(' ', ' ')
serie = serie.str.replace(' ', ' ')
return serie
Converting the text to CSV requires looping through the text files in the text directory created earlier. After opening each file, remove the extra spacing and append the modified text to a list. Then, add the text with the new lines removed to an empty Pandas data frame and write the data frame to a CSV file.
텍스트를 CSV로 변환하려면 이전에 만든 텍스트 디렉터리의 텍스트 파일을 통해 반복해야 합니다. 각 파일을 연 후 여분의 공백을 제거하고 수정된 텍스트를 목록에 추가합니다. 그런 다음 새 줄이 제거된 텍스트를 빈 Pandas 데이터 프레임에 추가하고 데이터 프레임을 CSV 파일에 씁니다.
Extra spacing and new lines can clutter the text and complicate the embeddings process. The code used here helps to remove some of them but you may find 3rd party libraries or other methods useful to get rid of more unnecessary characters.
여분의 간격과 새 줄은 텍스트를 어지럽히고 임베딩 프로세스를 복잡하게 만들 수 있습니다. 여기에 사용된 코드는 그 중 일부를 제거하는 데 도움이 되지만 더 많은 불필요한 문자를 제거하는 데 유용한 타사 라이브러리 또는 기타 방법을 찾을 수 있습니다.
import pandas as pd
# Create a list to store the text files
texts=[]
# Get all the text files in the text directory
for file in os.listdir("text/" + domain + "/"):
# Open the file and read the text
with open("text/" + domain + "/" + file, "r", encoding="UTF-8") as f:
text = f.read()
# Omit the first 11 lines and the last 4 lines, then replace -, _, and #update with spaces.
texts.append((file[11:-4].replace('-',' ').replace('_', ' ').replace('#update',''), text))
# Create a dataframe from the list of texts
df = pd.DataFrame(texts, columns = ['fname', 'text'])
# Set the text column to be the raw text with the newlines removed
df['text'] = df.fname + ". " + remove_newlines(df.text)
df.to_csv('processed/scraped.csv')
df.head()
Tokenization is the next step after saving the raw text into a CSV file. This process splits the input text into tokens by breaking down the sentences and words. A visual demonstration of this can be seen bychecking out our Tokenizerin the docs.
토큰화는 원시 텍스트를 CSV 파일로 저장한 후의 다음 단계입니다. 이 프로세스는 문장과 단어를 분해하여 입력 텍스트를 토큰으로 분할합니다. 이에 대한 시각적 데모는 checking out our Tokenizer문서에서 확인하여 볼 수 있습니다.
A helpful rule of thumb is that one token generally corresponds to ~4 characters of text for common English text. This translates to roughly ¾ of a word (so 100 tokens ~= 75 words).
유용한 경험 법칙은 하나의 토큰이 일반적으로 일반 영어 텍스트의 텍스트에서 ~4자에 해당한다는 것입니다. 이것은 대략 단어의 3/4로 변환됩니다(따라서 100 토큰 ~= 75 단어).
The API has a limit on the maximum number of input tokens for embeddings. To stay below the limit, the text in the CSV file needs to be broken down into multiple rows. The existing length of each row will be recorded first to identify which rows need to be split.
API에는 임베딩을 위한 최대 입력 토큰 수에 대한 제한이 있습니다. 한도 미만으로 유지하려면 CSV 파일의 텍스트를 여러 행으로 나누어야 합니다. 분할해야 하는 행을 식별하기 위해 각 행의 기존 길이가 먼저 기록됩니다.
import tiktoken
# Load the cl100k_base tokenizer which is designed to work with the ada-002 model
tokenizer = tiktoken.get_encoding("cl100k_base")
df = pd.read_csv('processed/scraped.csv', index_col=0)
df.columns = ['title', 'text']
# Tokenize the text and save the number of tokens to a new column
df['n_tokens'] = df.text.apply(lambda x: len(tokenizer.encode(x)))
# Visualize the distribution of the number of tokens per row using a histogram
df.n_tokens.hist()
The newest embeddings model can handle inputs with up to 8191 input tokens so most of the rows would not need any chunking, but this may not be the case for every subpage scraped so the next code chunk will split the longer lines into smaller chunks.
최신 임베딩 모델은 최대 8191개의 입력 토큰으로 입력을 처리할 수 있으므로 대부분의 행에 청킹이 필요하지 않지만 스크랩된 모든 하위 페이지에 해당하는 것은 아니므로 다음 코드 청크가 더 긴 줄을 더 작은 청크로 분할합니다.
max_tokens = 500
# Function to split the text into chunks of a maximum number of tokens
def split_into_many(text, max_tokens = max_tokens):
# Split the text into sentences
sentences = text.split('. ')
# Get the number of tokens for each sentence
n_tokens = [len(tokenizer.encode(" " + sentence)) for sentence in sentences]
chunks = []
tokens_so_far = 0
chunk = []
# Loop through the sentences and tokens joined together in a tuple
for sentence, token in zip(sentences, n_tokens):
# If the number of tokens so far plus the number of tokens in the current sentence is greater
# than the max number of tokens, then add the chunk to the list of chunks and reset
# the chunk and tokens so far
if tokens_so_far + token > max_tokens:
chunks.append(". ".join(chunk) + ".")
chunk = []
tokens_so_far = 0
# If the number of tokens in the current sentence is greater than the max number of
# tokens, go to the next sentence
if token > max_tokens:
continue
# Otherwise, add the sentence to the chunk and add the number of tokens to the total
chunk.append(sentence)
tokens_so_far += token + 1
return chunks
shortened = []
# Loop through the dataframe
for row in df.iterrows():
# If the text is None, go to the next row
if row[1]['text'] is None:
continue
# If the number of tokens is greater than the max number of tokens, split the text into chunks
if row[1]['n_tokens'] > max_tokens:
shortened += split_into_many(row[1]['text'])
# Otherwise, add the text to the list of shortened texts
else:
shortened.append( row[1]['text'] )
Visualizing the updated histogram again can help to confirm if the rows were successfully split into shortened sections.
업데이트된 히스토그램을 다시 시각화하면 행이 단축된 섹션으로 성공적으로 분할되었는지 확인하는 데 도움이 될 수 있습니다.
The content is now broken down into smaller chunks and a simple request can be sent to the OpenAI API specifying the use of the new text-embedding-ada-002 model to create the embeddings:
콘텐츠는 이제 더 작은 청크로 분류되며 새 text-embedding-ada-002 모델을 사용하여 임베딩을 생성하도록 지정하는 간단한 요청을 OpenAI API로 보낼 수 있습니다.
This should take about 3-5 minutes but after you will have your embeddings ready to use!
이 작업은 약 3-5분 정도 소요되지만 임베딩을 사용할 준비가 된 후에야 합니다!
Building a question answer system with your embeddings
The embeddings are ready and the final step of this process is to create a simple question and answer system. This will take a user's question, create an embedding of it, and compare it with the existing embeddings to retrieve the most relevant text from the scraped website. The text-davinci-003 model will then generate a natural sounding answer based on the retrieved text.
임베딩이 준비되었으며 이 프로세스의 마지막 단계는 간단한 질문 및 답변 시스템을 만드는 것입니다. 이것은 사용자의 질문을 받아 임베딩을 생성하고 기존 임베딩과 비교하여 스크랩한 웹사이트에서 가장 관련성이 높은 텍스트를 검색합니다. 그러면 text-davinci-003 모델이 검색된 텍스트를 기반으로 자연스러운 답변을 생성합니다.
Turning the embeddings into a NumPy array is the first step, which will provide more flexibility in how to use it given the many functions available that operate on NumPy arrays. It will also flatten the dimension to 1-D, which is the required format for many subsequent operations.
임베딩을 NumPy 배열로 전환하는 것이 첫 번째 단계이며 NumPy 배열에서 작동하는 많은 기능을 사용할 수 있는 경우 사용 방법에 더 많은 유연성을 제공합니다. 또한 많은 후속 작업에 필요한 형식인 1D로 차원을 평면화합니다.
import numpy as np
from openai.embeddings_utils import distances_from_embeddings
df=pd.read_csv('processed/embeddings.csv', index_col=0)
df['embeddings'] = df['embeddings'].apply(eval).apply(np.array)
df.head()
The question needs to be converted to an embedding with a simple function, now that the data is ready. This is important because the search with embeddings compares the vector of numbers (which was the conversion of the raw text) using cosine distance. The vectors are likely related and might be the answer to the question if they are close in cosine distance. The OpenAI python package has a built indistances_from_embeddingsfunction which is useful here.
이제 데이터가 준비되었으므로 질문을 간단한 기능을 사용하여 임베딩으로 변환해야 합니다. 임베딩을 사용한 검색은 코사인 거리를 사용하여 숫자 벡터(원본 텍스트의 변환)를 비교하기 때문에 이는 중요합니다. 벡터는 관련이 있을 가능성이 높으며 코사인 거리가 가까운 경우 질문에 대한 답이 될 수 있습니다. OpenAI Python 패키지에는 여기에서 유용한 distances_from_embeddings 함수가 내장되어 있습니다.
def create_context(
question, df, max_len=1800, size="ada"
):
"""
Create a context for a question by finding the most similar context from the dataframe
"""
# Get the embeddings for the question
q_embeddings = openai.Embedding.create(input=question, engine='text-embedding-ada-002')['data'][0]['embedding']
# Get the distances from the embeddings
df['distances'] = distances_from_embeddings(q_embeddings, df['embeddings'].values, distance_metric='cosine')
returns = []
cur_len = 0
# Sort by distance and add the text to the context until the context is too long
for i, row in df.sort_values('distances', ascending=True).iterrows():
# Add the length of the text to the current length
cur_len += row['n_tokens'] + 4
# If the context is too long, break
if cur_len > max_len:
break
# Else add it to the text that is being returned
returns.append(row["text"])
# Return the context
return "\n\n###\n\n".join(returns)
The text was broken up into smaller sets of tokens, so looping through in ascending order and continuing to add the text is a critical step to ensure a full answer. The max_len can also be modified to something smaller, if more content than desired is returned.
텍스트는 더 작은 토큰 세트로 분할되었으므로 오름차순으로 반복하고 텍스트를 계속 추가하는 것이 전체 답변을 보장하는 중요한 단계입니다. 원하는 것보다 더 많은 콘텐츠가 반환되는 경우 max_len을 더 작은 값으로 수정할 수도 있습니다.
The previous step only retrieved chunks of texts that are semantically related to the question, so they might contain the answer, but there's no guarantee of it. The chance of finding an answer can be further increased by returning the top 5 most likely results.
이전 단계에서는 질문과 의미론적으로 관련된 텍스트 덩어리만 검색했으므로 답변이 포함되어 있을 수 있지만 이에 대한 보장은 없습니다. 가장 가능성이 높은 상위 5개의 결과를 반환하여 답변을 찾을 가능성을 더욱 높일 수 있습니다.
The answering prompt will then try to extract the relevant facts from the retrieved contexts, in order to formulate a coherent answer. If there is no relevant answer, the prompt will return “I don’t know”.
응답 프롬프트는 일관된 답변을 공식화하기 위해 검색된 컨텍스트에서 관련 사실을 추출하려고 시도합니다. 관련 답변이 없으면 프롬프트에 "모르겠습니다"가 표시됩니다.
A realistic sounding answer to the question can be created with the completion endpoint usingtext-davinci-003.
text-davinci-003을 사용하여 completion endpoint로 질문에 대한 현실적인 답을 만들 수 있습니다.
def answer_question(
df,
model="text-davinci-003",
question="Am I allowed to publish model outputs to Twitter, without a human review?",
max_len=1800,
size="ada",
debug=False,
max_tokens=150,
stop_sequence=None
):
"""
Answer a question based on the most similar context from the dataframe texts
"""
context = create_context(
question,
df,
max_len=max_len,
size=size,
)
# If debug, print the raw model response
if debug:
print("Context:\n" + context)
print("\n\n")
try:
# Create a completions using the question and context
response = openai.Completion.create(
prompt=f"Answer the question based on the context below, and if the question can't be answered based on the context, say \"I don't know\"\n\nContext: {context}\n\n---\n\nQuestion: {question}\nAnswer:",
temperature=0,
max_tokens=max_tokens,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=stop_sequence,
model=model,
)
return response["choices"][0]["text"].strip()
except Exception as e:
print(e)
return ""
It is done! A working Q/A system that has the knowledge embedded from the OpenAI website is now ready. A few quick tests can be done to see the quality of the output:
완료되었습니다! OpenAI 웹사이트에서 내장된 지식이 있는 작동하는 Q/A 시스템이 이제 준비되었습니다. 출력 품질을 확인하기 위해 몇 가지 빠른 테스트를 수행할 수 있습니다.
answer_question(df, question="What day is it?", debug=False)
answer_question(df, question="What is our newest embeddings model?")
answer_question(df, question="What is ChatGPT?")
The responses will look something like the following:
Response는 다음과 같은 방식으로 나올 겁니다.
"I don't know."
'The newest embeddings model is text-embedding-ada-002.'
'ChatGPT is a model trained to interact in a conversational way. It is able to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests.'
If the system is not able to answer a question that is expected, it is worth searching through the raw text files to see if the information that is expected to be known actually ended up being embedded or not. The crawling process that was done initially was setup to skip sites outside the original domain that was provided, so it might not have that knowledge if there was a subdomain setup.
시스템이 예상되는 질문에 대답할 수 없는 경우 원시 텍스트 파일을 검색하여 알려질 것으로 예상되는 정보가 실제로 포함되었는지 여부를 확인하는 것이 좋습니다. 초기에 진행한 크롤링 과정은 원래 제공된 도메인 외 사이트는 건너뛰도록 설정되어 있어서 서브도메인 설정이 있었다면 해당 정보가 없을 수도 있습니다.
Currently, the dataframe is being passed in each time to answer a question. For more production workflows, avector database solutionshould be used instead of storing the embeddings in a CSV file, but the current approach is a great option for prototyping.
현재 데이터 프레임은 질문에 답하기 위해 매번 전달되고 있습니다. 더 많은 프로덕션 워크플로우의 경우 임베딩을 CSV 파일에 저장하는 대신 벡터 데이터베이스 솔루션을 사용해야 하지만 현재 접근 방식은 프로토타이핑을 위한 훌륭한 옵션입니다.
This guide includes an overview on error codes you might see from both theAPIand ourofficial Python library. Each error code mentioned in the overview has a dedicated section with further guidance.
이 가이드에는 API와 공식 Python 라이브러리 모두에서 볼 수 있는 오류 코드에 대한 개요가 포함되어 있습니다. 개요에 언급된 각 오류 코드에는 추가 지침이 있는 전용 섹션이 있습니다.
API errors
CODE OVERVIEW
401 - Invalid Authentication
Cause:Invalid Authentication Solution:Ensure the correctAPI keyand requesting organization are being used.
401 - Incorrect API key provided
Cause:The requesting API key is not correct. Solution:Ensure the API key used is correct, clear your browser cache, orgenerate a new one.
401 - You must be a member of an organization to use the API
Cause:Your account is not part of an organization. Solution:Contact us to get added to a new organization or ask your organization manager toinvite you to an organization.
429 - Rate limit reached for requests
Cause:You are sending requests too quickly. Solution:Pace your requests. Read theRate limit guide.
429 - You exceeded your current quota, please check your plan and billing details
429 - The engine is currently overloaded, please try again later
Cause:Our servers are experiencing high traffic. Solution:Please retry your requests after a brief wait.
500 - The server had an error while processing your request
Cause:Issue on our servers. Solution:Retry your request after a brief wait and contact us if the issue persists. Check thestatus page.
401 - Invalid Authentication
This error message indicates that your authentication credentials are invalid. This could happen for several reasons, such as:
이 오류 메시지는 인증 자격 증명이 유효하지 않음을 나타냅니다. 이는 다음과 같은 여러 가지 이유로 발생할 수 있습니다.
You are using a revoked API key.
취소된 API 키를 사용하고 있습니다.
You are using a different API key than the one assigned to the requesting organization.
요청 조직에 할당된 것과 다른 API 키를 사용하고 있습니다.
You are using an API key that does not have the required permissions for the endpoint you are calling.
호출 중인 엔드포인트에 필요한 권한이 없는 API 키를 사용하고 있습니다.
To resolve this error, please follow these steps:
이 오류를 해결하려면 다음 단계를 따르십시오.
Check that you are using the correct API key and organization ID in your request header. You can find your API key and organization ID inyour account settings.
요청 헤더에서 올바른 API 키와 조직 ID를 사용하고 있는지 확인하세요. 계정 설정에서 API 키와 조직 ID를 찾을 수 있습니다.
If you are unsure whether your API key is valid, you cangenerate a new one. Make sure to replace your old API key with the new one in your requests and follow ourbest practices guide.
API 키가 유효한지 확실하지 않은 경우 새 키를 생성할 수 있습니다. 요청 시 이전 API 키를 새 키로 교체하고 권장사항 가이드를 따르세요.
401 - Incorrect API key provided
This error message indicates that the API key you are using in your request is not correct. This could happen for several reasons, such as:
이 오류 메시지는 요청에 사용 중인 API 키가 올바르지 않음을 나타냅니다. 이는 다음과 같은 여러 가지 이유로 발생할 수 있습니다.
There is a typo or an extra space in your API key.
API 키에 오타나 추가 공백이 있습니다.
You are using an API key that belongs to a different organization.
다른 조직에 속한 API 키를 사용하고 있습니다.
You are using an API key that has been deleted or deactivated.
삭제 또는 비활성화된 API 키를 사용하고 있습니다.
An old, revoked API key might be cached locally.
해지된 이전 API 키는 로컬에 캐시될 수 있습니다.
To resolve this error, please follow these steps:
이 오류를 해결하려면 다음 단계를 따르십시오.
Try clearing your browser's cache and cookies, then try again.
브라우저의 캐시와 쿠키를 삭제한 후 다시 시도하세요.
Check that you are using the correct API key in your request header.
요청 헤더에서 올바른 API 키를 사용하고 있는지 확인하십시오.
If you are unsure whether your API key is correct, you cangenerate a new one. Make sure to replace your old API key in your codebase and follow ourbest practices guide.
API 키가 올바른지 확실하지 않은 경우 새 키를 생성할 수 있습니다. 코드베이스에서 이전 API 키를 교체하고 모범 사례 가이드를 따르십시오.
401 - You must be a member of an organization to use the API
This error message indicates that your account is not part of an organization. This could happen for several reasons, such as:
이 오류 메시지는 귀하의 계정이 조직의 일부가 아님을 나타냅니다. 이는 다음과 같은 여러 가지 이유로 발생할 수 있습니다.
You have left or been removed from your previous organization.
이전 조직에서 탈퇴했거나 제거되었습니다.
Your organization has been deleted.
조직이 삭제되었습니다.
To resolve this error, please follow these steps:
이 오류를 해결하려면 다음 단계를 따르십시오.
If you have left or been removed from your previous organization, you can either request a new organization or get invited to an existing one.
이전 조직에서 탈퇴했거나 제거된 경우 새 조직을 요청하거나 기존 조직에 초대받을 수 있습니다.
To request a new organization, reach out to us via help.openai.com
새 조직을 요청하려면 help.openai.com을 통해 문의하십시오.
Existing organization owners can invite you to join their organization via theMembers Panel.
기존 조직 소유자는 구성원 패널을 통해 귀하를 조직에 가입하도록 초대할 수 있습니다.
429 - Rate limit reached for requests
This error message indicates that you have hit your assigned rate limit for the API. This means that you have submitted too many tokens or requests in a short period of time and have exceeded the number of requests allowed. This could happen for several reasons, such as:
이 오류 메시지는 API에 할당된 Rate Limit에 도달했음을 나타냅니다. 이는 단기간에 너무 많은 토큰 또는 요청을 제출했고 허용된 요청 수를 초과했음을 의미합니다. 이는 다음과 같은 여러 가지 이유로 발생할 수 있습니다.
You are using a loop or a script that makes frequent or concurrent requests.
자주 또는 동시에 요청하는 루프 또는 스크립트를 사용하고 있습니다.
You are sharing your API key with other users or applications.
다른 사용자 또는 애플리케이션과 API 키를 공유하고 있습니다.
You are using a free plan that has a low rate limit.
Rate Limit이 낮은 무료 플랜을 사용하고 있습니다.
To resolve this error, please follow these steps:
이 오류를 해결하려면 다음 단계를 따르십시오.
Pace your requests and avoid making unnecessary or redundant calls.
요청 속도를 조절하고 불필요하거나 중복된 호출을 피하십시오.
If you are using a loop or a script, make sure to implement a backoff mechanism or a retry logic that respects the rate limit and the response headers. You can read more about our rate limiting policy and best practices in ourrate limit guide.
루프 또는 스크립트를 사용하는 경우 rate limit 및 응답 헤더를 준수하는 backoff메커니즘 또는 재시도 논리를 구현해야 합니다. rate limit guide에서 rate limit 정책 및 모범 사례에 대해 자세히 알아볼 수 있습니다.
If you are sharing your organization with other users, note that limits are applied per organization and not per user. It is worth checking on the usage of the rest of your team as this will contribute to the limit.
조직을 다른 사용자와 공유하는 경우 제한은 사용자가 아닌 조직별로 적용됩니다. 한도에 영향을 미치므로 나머지 팀의 사용량을 확인하는 것이 좋습니다.
If you are using a free or low-tier plan, consider upgrading to a pay-as-you-go plan that offers a higher rate limit. You can compare the restrictions of each plan in ourrate limit guide.
무료 또는 낮은 계층 요금제를 사용하는 경우 더 높은 rate limit을 제공하는 종량제 요금제로 업그레이드하는 것이 좋습니다. 요금 제한 가이드에서 각 플랜의 제한 사항을 비교할 수 있습니다.
try:
#Make your OpenAI API request here
response = openai.Completion.create(prompt="Hello world",
model="text-davinci-003")
except openai.error.APIError as e:
#Handle API error here, e.g. retry or log
print(f"OpenAI API returned an API Error: {e}")
pass
except openai.error.APIConnectionError as e:
#Handle connection error here
print(f"Failed to connect to OpenAI API: {e}")
pass
except openai.error.RateLimitError as e:
#Handle rate limit error (we recommend using exponential backoff)
print(f"OpenAI API request exceeded rate limit: {e}")
pass
429 - You exceeded your current quota, please check your plan and billing details
This error message indicates that you have hit your maximum monthly spend for the API. You can view your maximum monthly limit, under ‘hard limit’ in your [account billing settings](/account/billing/limits). This means that you have consumed all the credits allocated to your plan and have reached the limit of your current billing cycle. This could happen for several reasons, such as:
이 오류 메시지는 API에 대한 최대 월별 지출에 도달했음을 나타냅니다. [계정 결제 설정](/account/billing/limits)의 '하드 한도'에서 최대 월 한도를 확인할 수 있습니다. 이는 계획에 할당된 모든 크레딧을 사용했으며 현재 청구 주기의 한도에 도달했음을 의미합니다. 이는 다음과 같은 여러 가지 이유로 발생할 수 있습니다.
You are using a high-volume or complex service that consumes a lot of credits or tokens.
크레딧이나 토큰을 많이 소모하는 대용량 또는 복잡한 서비스를 사용하고 있습니다.
Your limit is set too low for your organization’s usage.
한도가 조직의 사용량에 비해 너무 낮게 설정되었습니다.
To resolve this error, please follow these steps:
이 오류를 해결하려면 다음 단계를 따르십시오.
Check your current quota in youraccount settings. You can see how many tokens your requests have consumed in theusage sectionof your account.
계정 설정에서 현재 할당량을 확인하세요. 계정의 사용량 섹션에서 요청이 소비한 토큰 수를 확인할 수 있습니다.
If you are using a free plan, consider upgrading to a pay-as-you-go plan that offers a higher quota.
무료 요금제를 사용 중인 경우 더 높은 할당량을 제공하는 종량제 요금제로 업그레이드하는 것이 좋습니다.
If you need a quota increase, you canapply for oneand provide relevant details on expected usage. We will review your request and get back to you in ~7-10 business days.
할당량 증가가 필요한 경우 신청하고 예상 사용량에 대한 관련 세부 정보를 제공할 수 있습니다. 귀하의 요청을 검토한 후 영업일 기준 ~7~10일 이내에 연락드리겠습니다.
429 - The engine is currently overloaded, please try again later
This error message indicates that our servers are experiencing high traffic and are unable to process your request at the moment. This could happen for several reasons, such as:
이 오류 메시지는 당사 서버의 트래픽이 많아 현재 귀하의 요청을 처리할 수 없음을 나타냅니다. 이는 다음과 같은 여러 가지 이유로 발생할 수 있습니다.
There is a sudden spike or surge in demand for our services.
서비스에 대한 수요가 갑자기 급증하거나 급증합니다.
There is scheduled or unscheduled maintenance or update on our servers.
서버에 예정되거나 예정되지 않은 유지 관리 또는 업데이트가 있습니다.
There is an unexpected or unavoidable outage or incident on our servers.
당사 서버에 예상치 못한 또는 피할 수 없는 중단 또는 사고가 발생했습니다.
To resolve this error, please follow these steps:
이 오류를 해결하려면 다음 단계를 따르십시오.
Retry your request after a brief wait. We recommend using an exponential backoff strategy or a retry logic that respects the response headers and the rate limit. You can read more about our rate limitbest practices.
잠시 기다린 후 요청을 다시 시도하십시오. exponential backoff 전략 또는 응답 헤더 및 Rate limit을 준수하는 재시도 논리를 사용하는 것이 좋습니다. Rate limit 모범 사례에 대해 자세히 알아볼 수 있습니다.
Check ourstatus pagefor any updates or announcements regarding our services and servers.
서비스 및 서버에 관한 업데이트 또는 공지 사항은 상태 페이지를 확인하십시오.
If you are still getting this error after a reasonable amount of time, please contact us for further assistance. We apologize for any inconvenience and appreciate your patience and understanding.
상당한 시간이 지난 후에도 이 오류가 계속 발생하면 당사에 문의하여 추가 지원을 받으십시오. 불편을 끼쳐 드려 죄송하며 양해해 주셔서 감사합니다.
Python library error types
TYPE OVERVIEW
APIError
Cause:Issue on our side. Solution:Retry your request after a brief wait and contact us if the issue persists.
Timeout
Cause:Request timed out. Solution:Retry your request after a brief wait and contact us if the issue persists.
RateLimitError
Cause:You have hit your assigned rate limit. Solution:Pace your requests. Read more in ourRate limit guide.
APIConnectionError
Cause:Issue connecting to our services. Solution:Check your network settings, proxy configuration, SSL certificates, or firewall rules.
InvalidRequestError
Cause:Your request was malformed or missing some required parameters, such as a token or an input. Solution:The error message should advise you on the specific error made. Check thedocumentationfor the specific API method you are calling and make sure you are sending valid and complete parameters. You may also need to check the encoding, format, or size of your request data.
AuthenticationError
Cause:Your API key or token was invalid, expired, or revoked. Solution:Check your API key or token and make sure it is correct and active. You may need to generate a new one from your account dashboard.
ServiceUnavailableError
Cause:Issue on our servers. Solution:Retry your request after a brief wait and contact us if the issue persists. Check thestatus page.
APIError
An `APIError` indicates that something went wrong on our side when processing your request. This could be due to a temporary error, a bug, or a system outage.
'APIError'는 요청을 처리할 때 OpenAI 측에서 문제가 발생했음을 나타냅니다. 이는 일시적인 오류, 버그 또는 시스템 중단 때문일 수 있습니다.
We apologize for any inconvenience and we are working hard to resolve any issues as soon as possible. You cancheck our system status pagefor more information.
불편을 끼쳐 드려 죄송하며 가능한 한 빨리 문제를 해결하기 위해 노력하고 있습니다. 자세한 내용은 시스템 상태 페이지에서 확인할 수 있습니다.
If you encounter anAPIError, please try the following steps:
APIError가 발생하면 다음 단계를 시도해 보세요.
Wait a few seconds and retry your request. Sometimes, the issue may be resolved quickly and your request may succeed on the second attempt.
몇 초간 기다린 후 요청을 다시 시도하십시오. 경우에 따라 문제가 빠르게 해결되고 두 번째 시도에서 요청이 성공할 수 있습니다.
Check our status page for any ongoing incidents or maintenance that may affect our services. If there is an active incident, please follow the updates and wait until it is resolved before retrying your request.
당사 서비스에 영향을 미칠 수 있는 진행 중인 사건이나 유지 보수에 대해서는 상태 페이지를 확인하십시오. active incident가 있는 경우 업데이트를 따르고 요청을 다시 시도하기 전에 문제가 해결될 때까지 기다리십시오.
If the issue persists, check out our Persistent errors next steps section.
문제가 지속되면 지속적인 오류 다음 단계 섹션을 확인하세요.
Our support team will investigate the issue and get back to you as soon as possible. Note that our support queue times may be long due to high demand. You can alsopost in our Community Forumbut be sure to omit any sensitive information.
지원팀에서 문제를 조사하고 최대한 빨리 답변을 드릴 것입니다. 수요가 많기 때문에 지원 대기 시간이 길어질 수 있습니다. 커뮤니티 포럼에 게시할 수도 있지만 민감한 정보는 생략해야 합니다.
Timeout
A `Timeout` error indicates that your request took too long to complete and our server closed the connection. This could be due to a network issue, a heavy load on our services, or a complex request that requires more processing time.
'시간 초과' 오류는 요청을 완료하는 데 시간이 너무 오래 걸려 서버가 연결을 종료했음을 나타냅니다. 이는 네트워크 문제, 서비스에 대한 과부하 또는 더 많은 처리 시간이 필요한 복잡한 요청 때문일 수 있습니다.
If you encounter aTimeouterror, please try the following steps:
시간 초과 오류가 발생하면 다음 단계를 시도하십시오.
Wait a few seconds and retry your request. Sometimes, the network congestion or the load on our services may be reduced and your request may succeed on the second attempt.
몇 초간 기다린 후 요청을 다시 시도하십시오. 경우에 따라 네트워크 정체 또는 당사 서비스의 부하가 줄어들 수 있으며 두 번째 시도에서 요청이 성공할 수 있습니다.
Check your network settings and make sure you have a stable and fast internet connection. You may need to switch to a different network, use a wired connection, or reduce the number of devices or applications using your bandwidth.
네트워크 설정을 확인하고 안정적이고 빠른 인터넷 연결이 있는지 확인하십시오. 다른 네트워크로 전환하거나 유선 연결을 사용하거나 대역폭을 사용하는 장치 또는 응용 프로그램 수를 줄여야 할 수 있습니다.
If the issue persists, check out our persistent errors next steps section.
문제가 지속되면 지속적인 오류 다음 단계 섹션을 확인하세요.
RateLimitError
A `RateLimitError` indicates that you have hit your assigned rate limit. This means that you have sent too many tokens or requests in a given period of time, and our services have temporarily blocked you from sending more.
'RateLimitError'는 할당된 rate limit에 도달했음을 나타냅니다. 이는 귀하가 주어진 기간 동안 너무 많은 토큰 또는 요청을 보냈고 당사 서비스가 일시적으로 귀하의 추가 전송을 차단했음을 의미합니다.
We impose rate limits to ensure fair and efficient use of our resources and to prevent abuse or overload of our services.
If you encounter aRateLimitError, please try the following steps:
당사는 자원의 공정하고 효율적인 사용을 보장하고 서비스의 남용 또는 과부하를 방지하기 위해 Rate limit을 부과합니다.
RateLimitError가 발생하면 다음 단계를 시도하십시오.
Send fewer tokens or requests or slow down. You may need to reduce the frequency or volume of your requests, batch your tokens, or implement exponential backoff. You can read ourRate limit guidefor more details.
더 적은 수의 토큰 또는 요청을 보내거나 속도를 늦추십시오. 요청의 빈도나 양을 줄이거나 토큰을 일괄 처리하거나 exponential backoff를 구현해야 할 수 있습니다. 자세한 내용은 Rate limit guide를 참조하세요.
Wait until your rate limit resets (one minute) and retry your request. The error message should give you a sense of your usage rate and permitted usage.
Rate Limit이 재설정될 때까지(1분) 기다렸다가 요청을 다시 시도하십시오. 오류 메시지는 사용률과 허용된 사용에 대한 정보를 제공해야 합니다.
You can also check your API usage statistics from your account dashboard.
계정 대시보드에서 API 사용 통계를 확인할 수도 있습니다.
APIConnectionError
An `APIConnectionError` indicates that your request could not reach our servers or establish a secure connection. This could be due to a network issue, a proxy configuration, an SSL certificate, or a firewall rule.
APIConnectionError'는 요청이 OpenAI 서버에 도달하지 못하거나 보안 연결을 설정할 수 없음을 나타냅니다. 이는 네트워크 문제, 프록시 구성, SSL 인증서 또는 방화벽 규칙 때문일 수 있습니다.
If you encounter anAPIConnectionError, please try the following steps:
APIConnectionError가 발생하면 다음 단계를 시도해 보세요.
Check your network settings and make sure you have a stable and fast internet connection. You may need to switch to a different network, use a wired connection, or reduce the number of devices or applications using your bandwidth.
네트워크 설정을 확인하고 안정적이고 빠른 인터넷 연결이 있는지 확인하십시오. 다른 네트워크로 전환하거나 유선 연결을 사용하거나 대역폭을 사용하는 장치 또는 응용 프로그램 수를 줄여야 할 수 있습니다.
Check your proxy configuration and make sure it is compatible with our services. You may need to update your proxy settings, use a different proxy, or bypass the proxy altogether.
프록시 구성을 확인하고 당사 서비스와 호환되는지 확인하십시오. 프록시 설정을 업데이트하거나 다른 프록시를 사용하거나 프록시를 모두 우회해야 할 수 있습니다.
Check your SSL certificates and make sure they are valid and up-to-date. You may need to install or renew your certificates, use a different certificate authority, or disable SSL verification.
SSL 인증서를 확인하고 유효하고 최신인지 확인하십시오. 인증서를 설치 또는 갱신하거나 다른 인증 기관을 사용하거나 SSL 확인을 비활성화해야 할 수 있습니다.
Check your firewall rules and make sure they are not blocking or filtering our services. You may need to modify your firewall settings.
방화벽 규칙을 확인하고 당사 서비스를 차단하거나 필터링하지 않는지 확인하십시오. 방화벽 설정을 수정해야 할 수도 있습니다.
If appropriate, check that your container has the correct permissions to send and receive traffic.
해당하는 경우 컨테이너에 트래픽을 보내고 받을 수 있는 올바른 권한이 있는지 확인하십시오.
If the issue persists, check out our persistent errors next steps section.
문제가 지속되면 지속적인 오류 다음 단계 섹션을 확인하세요.
InvalidRequestError
AnInvalidRequestErrorindicates that your request was malformed or missing some required parameters, such as a token or an input. This could be due to a typo, a formatting error, or a logic error in your code.
InvalidRequestError는 요청 형식이 잘못되었거나 토큰 또는 입력과 같은 일부 필수 매개변수가 누락되었음을 나타냅니다. 이는 코드의 오타, 형식 오류 또는 논리 오류 때문일 수 있습니다.
If you encounter anInvalidRequestError, please try the following steps:
InvalidRequestError가 발생하면 다음 단계를 시도하십시오.
Read the error message carefully and identify the specific error made. The error message should advise you on what parameter was invalid or missing, and what value or format was expected.
오류 메시지를 주의 깊게 읽고 발생한 특정 오류를 식별하십시오. 오류 메시지는 어떤 매개변수가 잘못되었거나 누락되었는지, 어떤 값이나 형식이 예상되었는지 알려줍니다.
Check theAPI Referencefor the specific API method you were calling and make sure you are sending valid and complete parameters. You may need to review the parameter names, types, values, and formats, and ensure they match the documentation.
호출한 특정 API 메서드에 대한 API 참조를 확인하고 유효하고 완전한 매개변수를 보내고 있는지 확인하십시오. 매개변수 이름, 유형, 값 및 형식을 검토하고 문서와 일치하는지 확인해야 할 수 있습니다.
Check the encoding, format, or size of your request data and make sure they are compatible with our services. You may need to encode your data in UTF-8, format your data in JSON, or compress your data if it is too large.
요청 데이터의 인코딩, 형식 또는 크기를 확인하고 당사 서비스와 호환되는지 확인하십시오. 데이터를 UTF-8로 인코딩하거나 데이터를 JSON 형식으로 지정하거나 데이터가 너무 큰 경우 데이터를 압축해야 할 수 있습니다.
Test your request using a tool like Postman or curl and make sure it works as expected. You may need to debug your code and fix any errors or inconsistencies in your request logic.
Postman 또는 curl과 같은 도구를 사용하여 요청을 테스트하고 예상대로 작동하는지 확인하십시오. 코드를 디버깅하고 요청 논리의 오류나 불일치를 수정해야 할 수 있습니다.
If the issue persists, check out our persistent errors next steps section.
문제가 지속되면 지속적인 오류 다음 단계 섹션을 확인하세요.
AuthenticationError
An `AuthenticationError` indicates that your API key or token was invalid, expired, or revoked. This could be due to a typo, a formatting error, or a security breach.
'AuthenticationError'는 API 키 또는 토큰이 유효하지 않거나 만료되었거나 취소되었음을 나타냅니다. 이는 오타, 형식 오류 또는 보안 위반 때문일 수 있습니다.
If you encounter anAuthenticationError, please try the following steps:
인증 오류가 발생하면 다음 단계를 시도하십시오.
Check your API key or token and make sure it is correct and active. You may need to generate a new key from the API Key dashboard, ensure there are no extra spaces or characters, or use a different key or token if you have multiple ones.
API 키 또는 토큰을 확인하고 올바르고 활성화되어 있는지 확인하십시오. API 키 대시보드에서 새 키를 생성하거나, 추가 공백이나 문자가 없는지 확인하거나, 키나 토큰이 여러 개인 경우 다른 키나 토큰을 사용해야 할 수 있습니다.
Ensure that you have followed the correct formatting.
올바른 형식을 따랐는지 확인하십시오.
ServiceUnavailableError
A `ServiceUnavailableError` indicates that our servers are temporarily unable to handle your request. This could be due to a planned or unplanned maintenance, a system upgrade, or a server failure. These errors can also be returned during periods of high traffic.
'ServiceUnavailableError'는 서버가 일시적으로 귀하의 요청을 처리할 수 없음을 나타냅니다. 이는 계획되거나 계획되지 않은 유지 관리, 시스템 업그레이드 또는 서버 오류 때문일 수 있습니다. 이러한 오류는 트래픽이 많은 기간에도 반환될 수 있습니다.
We apologize for any inconvenience and we are working hard to restore our services as soon as possible.
If you encounter aServiceUnavailableError, please try the following steps:
불편을 끼쳐 드려 죄송하며 최대한 빨리 서비스를 복구하기 위해 노력하고 있습니다.
Wait a few minutes and retry your request. Sometimes, the issue may be resolved quickly and your request may succeed on the next attempt.
몇 분 정도 기다린 후 요청을 다시 시도하십시오. 경우에 따라 문제가 빠르게 해결되고 다음 시도에서 요청이 성공할 수 있습니다.
Check ourstatus pagefor any ongoing incidents or maintenance that may affect our services. If there is an active incident, please follow the updates and wait until it is resolved before retrying your request.
당사 서비스에 영향을 미칠 수 있는 진행 중인 사건이나 유지 보수에 대해서는 상태 페이지를 확인하십시오. 활성 사고가 있는 경우 업데이트를 따르고 요청을 다시 시도하기 전에 문제가 해결될 때까지 기다리십시오.
If the issue persists, check out our persistent errors next steps section.
Any other relevant details that may help us diagnose the issue
Our support team will investigate the issue and get back to you as soon as possible. Note that our support queue times may be long due to high demand. You can alsopost in our Community Forumbut be sure to omit any sensitive information.
지원팀에서 문제를 조사하고 최대한 빨리 답변을 드릴 것입니다. 수요가 많기 때문에 지원 대기 시간이 길어질 수 있습니다. 커뮤니티 포럼에 게시할 수도 있지만 민감한 정보는 생략해야 합니다.
Handling errors
We advise you to programmatically handle errors returned by the API. To do so, you may want to use a code snippet like below:
API에서 반환된 오류를 프로그래밍 방식으로 처리하는 것이 좋습니다. 이렇게 하려면 아래와 같은 코드 스니펫을 사용할 수 있습니다.
A rate limit is a restriction that an API imposes on the number of times a user or client can access the server within a specified period of time.
Rate limit은 API가 사용자 또는 클라이언트가 특정 시간동안 서버에 접속할 수 있는 횟수에 부과하는 제한 입니다.
Why do we have rate limits?
Rate limits are a common practice for APIs, and they're put in place for a few different reasons:
Rate limit은 API에 대한 일반적인 관행입니다. 이 제한이 있는 이유는 몇가지 이유가 있습니다.
They help protect against abuse or misuse of the API.For example, a malicious actor could flood the API with requests in an attempt to overload it or cause disruptions in service. By setting rate limits, OpenAI can prevent this kind of activity.
API의 남용 또는 오용을 방지하는 데 도움이 됩니다. 예를 들어 악의적인 행위자는 API에 과부하를 일으키거나 서비스를 중단시키려는 시도로 API에 요청을 플러딩할 수 있습니다. Rate Limit을 설정함으로써 OpenAI는 이러한 종류의 공격을 방지할 수 있습니다.
Rate limits help ensure that everyone has fair access to the API.If one person or organization makes an excessive number of requests, it could bog down the API for everyone else. By throttling the number of requests that a single user can make, OpenAI ensures that the most number of people have an opportunity to use the API without experiencing slowdowns.
Rate Limit은 모든 사람이 API에 공정하게 액세스할 수 있도록 도와줍니다. 한 개인이나 조직이 과도한 수의 요청을 하면 다른 모든 사람의 API가 중단될 수 있습니다. 단일 사용자가 만들 수 있는 요청 수를 제한함으로써 OpenAI는 대부분의 사람들이 속도 저하 없이 API를 사용할 기회를 갖도록 보장합니다.
Rate limits can help OpenAI manage the aggregate load on its infrastructure.If requests to the API increase dramatically, it could tax the servers and cause performance issues. By setting rate limits, OpenAI can help maintain a smooth and consistent experience for all users.
Rate limit은 OpenAI가 인프라의 총 로드를 관리하는 데 도움이 될 수 있습니다. API에 대한 요청이 급격히 증가하면 서버에 부담을 주고 성능 문제를 일으킬 수 있습니다. Rate limit을 설정함으로써 OpenAI는 모든 사용자에게 원활하고 일관된 경험을 유지하는 데 도움을 줄 수 있습니다.
Please work through this document in its entirety to better understand how OpenAI’s rate limit system works. We include code examples and possible solutions to handle common issues. It is recommended to follow this guidance before filling out theRate Limit Increase Request formwith details regarding how to fill it out in the last section.
OpenAI의 Rate limit 시스템이 작동하는 방식을 더 잘 이해하려면 이 문서 전체를 살펴보십시오. 일반적인 문제를 처리할 수 있는 코드 예제와 가능한 솔루션이 포함되어 있습니다. 요금 한도 인상 요청 양식을 작성하기 전에 마지막 섹션에서 작성 방법에 대한 세부 정보를 작성하기 전에 이 지침을 따르는 것이 좋습니다.
What are the rate limits for our API?
We enforce rate limits at theorganization level, not user level, based on the specific endpoint used as well as the type of account you have. Rate limits are measured in two ways:RPM(requests per minute) andTPM(tokens per minute). The table below highlights the default rate limits for our API but these limits can be increased depending on your use case after filling out the Rate Limit increase request form.
OpenAI는 사용된 특정 엔드포인트와 보유한 계정 유형을 기반으로 사용자 수준이 아닌 조직 수준에서 속도 제한을 적용합니다. Rate Limit은 RPM(분당 요청) 및 TPM(분당 토큰)의 두 가지 방식으로 측정됩니다. 아래 표에는 API에 대한 기본 Rate Limit이 강조되어 있지만 이러한 제한은 Rate Limit 증가 요청 양식을 작성한 후 사용 사례에 따라 증가할 수 있습니다.
TheTPM(tokens per minute) unit is different depending on the model:
TPM 은 모델에 따라 다릅니다.
실제로 이것은 davinci 모델에 비해 ada 모델에 분당 약 200배 더 많은 토큰을 보낼 수 있음을 의미합니다.
It is important to note that the rate limit can be hit by either option depending on what occurs first. For example, you might send 20 requests with only 100 tokens to the Codex endpoint and that would fill your limit, even if you did not send 40k tokens within those 20 requests.
Rate limit은 먼저 발생하는 항목에 따라 두 옵션 중 하나에 의해 적중될 수 있다는 점에 유의하는 것이 중요합니다. 예를 들어 Codex 엔드포인트에 100개의 토큰만 있는 20개의 요청을 보낼 수 있으며 20개의 요청 내에서 40,000개의 토큰을 보내지 않았더라도 제한을 채울 수 있습니다.
How do rate limits work?
Rate limit이 분당 요청 60개이고 분당 150,000 davinci 토큰인 경우 requests/min 한도에 도달하거나 토큰이 부족하여 제한을 받게 됩니다. 둘 중 어느 하나에 도달하면 이러한 상황이 발생합니다. 예를 들어 분당 최대 요청 수가 60이면 초당 1개의 요청을 보낼 수 있어야 합니다. 800ms마다 1개의 요청을 보내는 경우 Rate Limit에 도달하면 프로그램을 200ms만 휴면 상태로 만들면 하나 더 요청을 보낼 수 있습니다. 그렇지 않으면 후속 요청이 실패합니다. 기본적으로 분당 3,000개의 요청을 사용하면 고객은 20ms마다 또는 0.02초마다 효과적으로 1개의 요청을 보낼 수 있습니다.
What happens if I hit a rate limit error?
Rate limit errors look like this: Rate limit 에러 메세지는 아래 처럼 나옵니다.
Rate limit reached for default-text-davinci-002 in organization org-{id} on requests per min. Limit: 20.000000 / min. Current: 24.000000 / min.
If you hit a rate limit, it means you've made too many requests in a short period of time, and the API is refusing to fulfill further requests until a specified amount of time has passed.
Rate Limit에 도달하면 짧은 시간에 너무 많은 요청을 했고 지정된 시간이 지날 때까지 API가 추가 요청 이행을 거부하고 있음을 의미합니다.
Rate limits vsmax_tokens
Eachmodel we offerhas a limited number of tokens that can be passed in as input when making a request. You cannot increase the maximum number of tokens a model takes in. For example, if you are usingtext-ada-001, the maximum number of tokens you can send to this model is 2,048 tokens per request.
OpenAI가 제공하는 각 모델에는 request시 input으로 전달할 수 있는 토큰 수가 제한 돼 있습니다. 모델이 받을 수 있는 최대 토큰 수는 늘릴 수 없습니다. 예를 들어 text-ada-001을 사용하는 경우 이 모델에 보낼 수 있는 최대 토큰 수는 요청당 2048개의 토큰 입니다.
Error Mitigation
What are some steps I can take to mitigate this?
The OpenAI Cookbook has apython notebookthat explains details on how to avoid rate limit errors.
OpenAI Cookbook에는 Rate Limit 오류를 방지하는 방법에 대한 세부 정보를 설명하는 Python 노트북이 있습니다.
You should also exercise caution when providing programmatic access, bulk processing features, and automated social media posting - consider only enabling these for trusted customers.
또한 프로그래밍 방식 액세스, 대량 처리 기능 및 자동화된 소셜 미디어 게시를 제공할 때 주의해야 합니다. 신뢰할 수 있는 고객에 대해서만 이러한 기능을 활성화하는 것이 좋습니다.
To protect against automated and high-volume misuse, set a usage limit for individual users within a specified time frame (daily, weekly, or monthly). Consider implementing a hard cap or a manual review process for users who exceed the limit.
자동화된 대량 오용으로부터 보호하려면 지정된 기간(일별, 주별 또는 월별) 내에서 개별 사용자에 대한 사용 제한을 설정하십시오. 한도를 초과하는 사용자에 대해 하드 캡 또는 수동 검토 프로세스를 구현하는 것을 고려하십시오.
Retrying with exponential backoff
One easy way to avoid rate limit errors is to automatically retry requests with a random exponential backoff. Retrying with exponential backoff means performing a short sleep when a rate limit error is hit, then retrying the unsuccessful request. If the request is still unsuccessful, the sleep length is increased and the process is repeated. This continues until the request is successful or until a maximum number of retries is reached. This approach has many benefits:
Rate Limit 오류를 방지하는 한 가지 쉬운 방법은 andom exponential backoff로 요청을 자동으로 재시도하는 것입니다. exponential backoff로 재시도한다는 것은 Rate Limit 오류에 도달했을 때 short sleep 모드를 수행한 다음 실패한 요청을 다시 시도하는 것을 의미합니다. 요청이 여전히 실패하면 sleep 시간이 증가하고 프로세스가 반복됩니다. 이것은 요청이 성공하거나 최대 재시도 횟수에 도달할 때까지 계속됩니다. 이 접근 방식에는 다음과 같은 많은 이점이 있습니다.
Automatic retries means you can recover from rate limit errors without crashes or missing data
자동 재시도는 충돌이나 데이터 손실 없이 rate limit 오류에서 복구할 수 있음을 의미합니다.
Exponential backoff means that your first retries can be tried quickly, while still benefiting from longer delays if your first few retries fail
Exponential backoff는 첫 번째 재시도를 빠르게 시도할 수 있음을 의미하며 처음 몇 번의 재시도가 실패할 경우 더 긴 지연으로부터 이점을 누릴 수 있습니다.
Adding random jitter to the delay helps retries from all hitting at the same time.
지연에 andom jitter를 추가하면 동시에 모든 hitting에서 재시도하는 데 도움이 됩니다.
Note that unsuccessful requests contribute to your per-minute limit, so continuously resending a request won’t work.
실패한 요청은 분당 한도에 영향을 미치므로 계속해서 요청을 다시 보내면 작동하지 않습니다.
Below are a few example solutionsfor Pythonthat use exponential backoff.
다음은 exponential backoff를 사용하는 Python에 대한 몇 가지 예제 솔루션입니다.
Example #1: Using the Tenacity library
Tenacity is an Apache 2.0 licensed general-purpose retrying library, written in Python, to simplify the task of adding retry behavior to just about anything. To add exponential backoff to your requests, you can use thetenacity.retrydecorator. The below example uses thetenacity.wait_random_exponentialfunction to add random exponential backoff to a request.
Tenacity는 Python으로 작성된 Apache 2.0 라이센스 범용 재시도 라이브러리로 거의 모든 항목에 재시도 동작을 추가하는 작업을 단순화합니다. 요청에 exponential backoff를 추가하려면 tenacity.retry 데코레이터를 사용할 수 있습니다. 아래 예에서는 tenacity.wait_random_exponential 함수를 사용하여 무작위 exponential backoff를 요청에 추가합니다.
import openai
from tenacity import (
retry,
stop_after_attempt,
wait_random_exponential,
) # for exponential backoff
@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6))
def completion_with_backoff(**kwargs):
return openai.Completion.create(**kwargs)
completion_with_backoff(model="text-davinci-003", prompt="Once upon a time,")
Note that the Tenacity library is a third-party tool, and OpenAI makes no guarantees about its reliability or security.
import backoff
import openai
@backoff.on_exception(backoff.expo, openai.error.RateLimitError)
def completions_with_backoff(**kwargs):
return openai.Completion.create(**kwargs)
completions_with_backoff(model="text-davinci-003", prompt="Once upon a time,")
Like Tenacity, the backoff library is a third-party tool, and OpenAI makes no guarantees about its reliability or security.
Tenacity와 마찬가지로 백오프 라이브러리는 타사 도구이며 OpenAI는 안정성이나 보안에 대해 보장하지 않습니다.
Example 3: Manual backoff implementation
If you don't want to use third-party libraries, you can implement your own backoff logic following this example:
타사 라이브러리를 사용하지 않으려면 다음 예제에 따라 자체 백오프 논리를 구현할 수 있습니다.
# imports
import random
import time
import openai
# define a retry decorator
def retry_with_exponential_backoff(
func,
initial_delay: float = 1,
exponential_base: float = 2,
jitter: bool = True,
max_retries: int = 10,
errors: tuple = (openai.error.RateLimitError,),
):
"""Retry a function with exponential backoff."""
def wrapper(*args, **kwargs):
# Initialize variables
num_retries = 0
delay = initial_delay
# Loop until a successful response or max_retries is hit or an exception is raised
while True:
try:
return func(*args, **kwargs)
# Retry on specific errors
except errors as e:
# Increment retries
num_retries += 1
# Check if max retries has been reached
if num_retries > max_retries:
raise Exception(
f"Maximum number of retries ({max_retries}) exceeded."
)
# Increment the delay
delay *= exponential_base * (1 + jitter * random.random())
# Sleep for the delay
time.sleep(delay)
# Raise exceptions for any errors not specified
except Exception as e:
raise e
return wrapper
@retry_with_exponential_backoff
def completions_with_backoff(**kwargs):
return openai.Completion.create(**kwargs)
다시 말하지만 OpenAI는 이 솔루션의 보안이나 효율성을 보장하지 않지만 자체 솔루션을 위한 좋은 출발점이 될 수 있습니다.
Batching requests
The OpenAI API has separate limits for requests per minute and tokens per minute.
OpenAI API에는 분당 요청 및 분당 토큰에 대한 별도의 제한이 있습니다.
If you're hitting the limit on requests per minute, but have available capacity on tokens per minute, you can increase your throughput by batching multiple tasks into each request. This will allow you to process more tokens per minute, especially with our smaller models.
분당 요청 제한에 도달했지만 분당 토큰에 사용 가능한 용량이 있는 경우 여러 작업을 각 요청에 일괄 처리하여 처리량을 늘릴 수 있습니다. 이렇게 하면 특히 더 작은 모델을 사용하여 분당 더 많은 토큰을 처리할 수 있습니다.
Sending in a batch of prompts works exactly the same as a normal API call, except you pass in a list of strings to the prompt parameter instead of a single string.
단일 문자열 대신 프롬프트 매개변수에 문자열 목록을 전달한다는 점을 제외하면 프롬프트 일괄 전송은 일반 API 호출과 정확히 동일하게 작동합니다.
Example without batching
import openai
num_stories = 10
prompt = "Once upon a time,"
# serial example, with one story completion per request
for _ in range(num_stories):
response = openai.Completion.create(
model="curie",
prompt=prompt,
max_tokens=20,
)
# print story
print(prompt + response.choices[0].text)
Example with batching
import openai # for making OpenAI API requests
num_stories = 10
prompts = ["Once upon a time,"] * num_stories
# batched example, with 10 story completions per request
response = openai.Completion.create(
model="curie",
prompt=prompts,
max_tokens=20,
)
# match completions to prompts by index
stories = [""] * len(prompts)
for choice in response.choices:
stories[choice.index] = prompts[choice.index] + choice.text
# print stories
for story in stories:
print(story)
Warning: the response object may not return completions in the order of the prompts, so always remember to match responses back to prompts using the index field.
경고: 응답 개체는 프롬프트 순서대로 완료를 반환하지 않을 수 있으므로 항상 인덱스 필드를 사용하여 응답을 프롬프트에 다시 일치시켜야 합니다.
Request Increase
When should I consider applying for a rate limit increase?
Our default rate limits help us maximize stability and prevent abuse of our API. We increase limits to enable high-traffic applications, so the best time to apply for a rate limit increase is when you feel that you have the necessary traffic data to support a strong case for increasing the rate limit. Large rate limit increase requests without supporting data are not likely to be approved. If you're gearing up for a product launch, please obtain the relevant data through a phased release over 10 days.
Keep in mind that rate limit increases can sometimes take 7-10 days so it makes sense to try and plan ahead and submit early if there is data to support you will reach your rate limit given your current growth numbers.
기본 rate limit은 안정성을 극대화하고 API 남용을 방지하는 데 도움이 됩니다. 우리는 트래픽이 많은 애플리케이션을 활성화하기 위해 제한을 늘립니다. 따라서 rate limits 증가를 신청할 가장 좋은 시기는 속도 제한 증가에 대한 강력한 사례를 지원하는 데 필요한 트래픽 데이터가 있다고 생각할 때입니다. 지원 데이터가 없는 대규모 rate limits 증가 요청은 승인되지 않을 가능성이 높습니다. 제품 출시를 준비하고 있다면 10일에 걸친 단계별 릴리스를 통해 관련 데이터를 얻으십시오.
Will my rate limit increase request be rejected?
A rate limit increase request is most often rejected because it lacks the data needed to justify the increase. We have provided numerical examples below that show how to best support a rate limit increase request and try our best to approve all requests that align with our safety policy and show supporting data. We are committed to enabling developers to scale and be successful with our API.
rate limit 증가 요청은 증가를 정당화하는 데 필요한 데이터가 부족하기 때문에 거부되는 경우가 가장 많습니다. 속도 제한 증가 요청을 가장 잘 지원하는 방법을 보여주고 안전 정책에 부합하는 모든 요청을 승인하고 지원 데이터를 표시하기 위해 최선을 다하는 방법을 아래에 숫자로 나타낸 예를 제공했습니다. 우리는 개발자가 API를 사용하여 확장하고 성공할 수 있도록 최선을 다하고 있습니다.
I’ve implemented exponential backoff for my text/code APIs, but I’m still hitting this error. How do I increase my rate limit?
Currently, we don’t support increasing ourfree beta endpoints, such as the editendpoint. We alsodon’t increase ChatGPTrate limits but you can join the waitlist forChatGPT Professional access.
현재 edit endpoint 같은 free beta endpoints 에 대해서는 제한량 증가를 지원하지 않습니다. 또한 ChatGPT Rate Limit을 늘리지 않지만 ChatGPT Professional 액세스 대기자 명단에 가입할 수 있습니다.
We understand the frustration that limited rate limits can cause, and we would love to raise the defaults for everyone. However, due to shared capacity constraints, we can only approve rate limit increases for paid customers who have demonstrated a need through ourRate Limit Increase Request form. To help us evaluate your needs properly, we ask that you please provide statistics on your current usage or projections based on historic user activity in the 'Share evidence of need' section of the form. If this information is not available, we recommend a phased release approach. Start by releasing the service to a subset of users at your current rate limits, gather usage data for 10 business days, and then submit a formal rate limit increase request based on that data for our review and approval.
We will review your request and if it is approved, we will notify you of the approval within a period of 7-10 business days.
Here are some examples of how you might fill out this form:
limited rate limits이 야기할 수 있는 불만을 이해하고 있으며 모든 사람을 위해 기본값을 높이고 싶습니다. 그러나 공유 용량 제약으로 인해 rate limit 증가 요청 양식을 통해 필요성을 입증한 유료 고객에 대해서만 rate limit 증가를 승인할 수 있습니다. 귀하의 필요를 적절하게 평가할 수 있도록 양식의 '필요에 대한 증거 공유' 섹션에서 이전 사용자 활동을 기반으로 현재 사용량 또는 예상에 대한 통계를 제공해 주시기 바랍니다. 이 정보를 사용할 수 없는 경우 단계적 릴리스 접근 방식을 권장합니다. 현재 rate limit으로 사용자 하위 집합에 서비스를 릴리스하고 영업일 기준 10일 동안 사용 데이터를 수집한 다음 검토 및 승인을 위해 해당 데이터를 기반으로 공식적인 rate limit 증가 요청을 제출합니다.
DALL-E API examples
Language model examples
Code model examples
Please note that these examples are just general use case scenarios, the actual usage rate will vary depending on the specific implementation and usage.
이러한 예는 일반적인 사용 사례 시나리오일 뿐이며 실제 사용률은 특정 구현 및 사용에 따라 달라집니다.
The speech to text API provides two endpoints,transcriptionsandtranslations, based on our state-of-the-art open source large-v2Whisper model. They can be used to:
음성을 텍스트로 바꿔 주는 API는 두개의 endpoint를 제공합니다. 필사와 번역입니다. 이것은 최신 오픈 소스인 large-v2 Whisper 모델을 기반으로 합니다.
Transcribe audio into whatever language the audio is in.
어떤 언어의 오디오든 그것을 글로 옮겨 씁니다.
Translate and transcribe the audio into english.
오디오를 영어로 번역해서 옮겨 씁니다.
File uploads are currently limited to 25 MB and the following input file types are supported:mp3,mp4,mpeg,mpga,m4a,wav, andwebm.
오디오 파일 업로드는 현재까지 25MB로 제한 됩니다. 그리고 다음과 같은 파일 형식을 따라야 합니다.
mp3,mp4,mpeg,mpga,m4a,wav, andwebm.
Quickstart
Transcriptions
The transcriptions API takes as input the audio file you want to transcribe and the desired output file format for the transcription of the audio. We currently support multiple input and output file formats.
Transcriptions API 작업은 transcribe하고 싶은 오디오 피일과 원하는 output file 형식을 같이 입력하시면 됩니다. OpenAI는 현재 여러 입력, 출력 파일 형식을 지원하고 있습니다.
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
audio_file= open("/path/to/file/audio.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
By default, the response type will be json with the raw text included.
기본으로 response 형식은 raw text가 포함된 json 형식입니다.
{ "text": "Imagine the wildest idea that you've ever had, and you're curious about how it might scale to something that's a 100, a 1,000 times bigger. .... }
To set additional parameters in a request, you can add more--formlines with the relevant options. For example, if you want to set the output format as text, you would add the following line:
Request에 추가적인 파라미터를 세팅하기 위해 관련 옵션과 함께 --form 라인을 추가하시면 됩니다. 예를 들어 여러분이 output 형식을 text로 세팅하고 싶으면 아래와 같이 하면 됩니다.
The translations API takes as input the audio file in any of the supported languages and transcribes, if necessary, the audio into english. This differs from our /Transcriptions endpoint since the output is not in the original input language and is instead translated to english text.
번역 API 작업은 지원되는 언어들중 사용자가 제공하는 어떤 것을 입력값으로 받게 됩니다. 그리고 transcribe를 하고 필요하면 오디오를 영어로 번역합니다. /Transcriptions endpoint와 다른점은 output이 입력된 원래 언어와 다른 언어가 된다는 것입니다. 그리고 그 언어를 영어 text번역 합니다.
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
audio_file= open("/path/to/file/german.mp3", "rb")
transcript = openai.Audio.translate("whisper-1", audio_file)
In this case, the inputted audio was german and the outputted text looks like:
이 경우 입력된 오디오는독일어이고 출력된 텍스트는 아래와 같게 됩니다.
Hello, my name is Wolfgang and I come from Germany. Where are you heading today?
We only support translation into english at this time.
While the underlying model was trained on 98 languages, we only list the languages that exceeded <50%word error rate(WER) which is an industry standard benchmark for speech to text model accuracy. The model will return results for languages not listed above but the quality will be low.
기본 모델은 98개 언어로 훈련이 되어 있습니다. OpenAI는 speech to text 모델의 정확도에 대한 업계 표준 벤치마크인 word error rate (WER) 이 50% 미만인 언어만 리스트 합니다.
Longer inputs
By default, the Whisper API only supports files that are less than 25 MB. If you have an audio file that is longer than that, you will need to break it up into chunks of 25 MB's or less or used a compressed audio format. To get the best performance, we suggest that you avoid breaking the audio up mid-sentence as this may cause some context to be lost.
기본적으로 Whisper API는 25MB 이하의 파일들만 지원합니다. 그보다 크기가 큰 오디오 파일은 25MB 이하로 나누거나 압축된 오디오 형식을 사용해야 합니다. 파일을 나눌 때 최고의 성능을 얻으려면 일부 context가 손실되는 것을 방비하기 위해 문장 중간을 끊지 않는 것이 좋습니다.
from pydub import AudioSegment
song = AudioSegment.from_mp3("good_morning.mp3")
# PyDub handles time in milliseconds
ten_minutes = 10 * 60 * 1000
first_10_minutes = song[:ten_minutes]
first_10_minutes.export("good_morning_10.mp3", format="mp3")
OpenAI makes no guarantees about the usability or security of 3rd party software like PyDub.
OpenAI는 PyDub와 같은 타사 소프트웨어의 usability나 security에 대한 어떠한 보장도 하지 않습니다.
Prompting
In the same way that you can use apromptto influence the output of our language models, you can also use one to improve the quality of the transcripts generated by the Whisper API. The model will try to match the style of the prompt, so it will be more likely to use capitalization and punctuation if the prompt does too. Here are some examples of how prompting can help in different scenarios:
Prompt를 사용하여 우리의 language 모델의 output에 영향을 미칠 수 있는 것과 마찬가지로 Whisper API에 의해 생성된 transcript의 질을 향상시키기 위해 이 prompt를 사용할 수 있습니다. 이 Whisper API 모델은 프롬프트의 스타일을 match 시키려고 시도합니다. 그러니까 프롬프트가 하는 것과 마찬가지로 capitalization 과 punctuation 을 사용할 가능성이 높습니다. 여기 다양한 시나리오에서 프롬프트가 어떻게 도움이 되는지에 대한 몇가지 예를 보여 드립니다.
1. Prompts can be very helpful for correcting specific words or acronyms that the model often misrecognizes in the audio. For example, the following prompt improves the transcription of the words DALL·E and GPT-3, which were previously written as "GDP 3" and "DALI".
프롬프트는 모델이 오디오에서 종종 잘 못 인식하는 특정 단어나 약어를 수정하는데 매우 유용할 수 있습니다. 예를 들어 다음 프롬프트는 이전에 GDP 3 나 DALI 로 기록 되었던 DALL-E 및 GPT-3 라는 단어의 표기를 개선합니다.
The transcript is about OpenAI which makes technology like DALL·E, GPT-3, and ChatGPT with the hope of one day building an AGI system that benefits all of humanity
2. To preserve the context of a file that was split into segments, you can prompt the model with the transcript of the preceding segment. This will make the transcript more accurate, as the model will use the relevant information from the previous audio. The model will only consider the final 224 tokens of the prompt and ignore anything earlier.
segment들로 나누어진 파일의 context를 유지하기 위해 여러분은 이전 세그먼트의 기록으로 모델에 메시지를 표시할 수 있습니다. 이렇게 하면 모델이 이전 오디오의 관련 정보를 사용하므로 transcript 가 더욱 정확해 집니다. 모델은 프롬프트의 마지막 224개 토큰만 고려하고 이전의 것들은 무시합니다.
3. Sometimes the model might skip punctuation in the transcript. You can avoid this by using a simple prompt that includes punctuation:
때떄로 이 모델은 transcript의 punctuation을 skip 할 수 있습니다. 이것은 punctuation을 포함하는 간단한 프롬프트를 사용함으로서 해결 할 수 있습니다.
Hello, welcome to my lecture.
4. The model may also leave out common filler words in the audio. If you want to keep the filler words in your transcript, you can use a prompt that contains them:
이 모델은 오디오에서 일반적인 filler words를 생략할 수 있습니다. transcript에 이러한 filler word들을 유지하려면 filler word를 포함하는 프롬프트를 사용하면 됩니다.
Umm, let me think like, hmm... Okay, here's what I'm, like, thinking."
filler word : 말 사이에 의미없이 하는 말. Um.. uhh... like... 같은 말
5. Some languages can be written in different ways, such as simplified or traditional Chinese. The model might not always use the writing style that you want for your transcript by default. You can improve this by using a prompt in your preferred writing style.
어떤 언어들은 다른 방법으로 표기가 됩니다. 예를 들어 중국어에는 간체와 번체가 있죠. 이 모델은 기본적으로 transcript에 대해 원하는 쓰기 스타일을 항상 사용하지 않을 수 있습니다. 원하는 쓰기 스타일이 있다면 프롬프트를 사용하여 원하는 결과를 얻도록 유도할 수 있습니다.
이 가이드는 채팅 기반 언어 모델에 대한 API 호출을 만드는 방법을 설명하고 좋은 결과를 얻기 위한 팁을 공유합니다.
여러분은 또한 OpenAI Playground에서 채로운 채팅 형식을 실험해 볼 수도 있습니다.
Introduction
Chat models take a series of messages as input, and return a model-generated message as output.
채팅 모델은 일련의 메세지를 입력값으로 받고 모델이 생성한 메세지를 output 으로 반환합니다.
Although the chat format is designed to make multi-turn conversations easy, it’s just as useful for single-turn tasks without any conversations (such as those previously served by instruction following models liketext-davinci-003).
채팅 형식은 multi-turn 대화를 쉽게 할 수 있도록 디자인 되었지만 대화가 없는 Single-turn 작업에도 유용하게 사용할 수 있습니다. (예: text-davinci-003 같이 instruction 에 따르는 모델이 제공한 것 같은 서비스)
An example API call looks as follows: 예제 API 호출은 아래와 같습니다.
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
openai를 import 한 다음 openai.ChatCompletion.create() API 를 사용하면 됩니다.
The main input is the messages parameter. Messages must be an array of message objects, where each object has a role (either “system”, “user”, or “assistant”) and content (the content of the message). Conversations can be as short as 1 message or fill many pages.
주요 입력값들은 메세지의 파라미터 들입니다. 메세지들은 반드시 메세지 객체의 배열 형식이어야 합니다. 각 객체들에는 Role (역할) 이 주어집니다. (System, User, 혹은 Assistant 가 해당 메세지 객체의 Role이 됩니다.) 그리고 내용이 있습니다. (그 내용은 메세지가 됩니다.) 대화는 1개의 메세지로 된 짧은 형식이 될 수도 있고 여러 페이지에 걸친 많은 양이 될 수도 있습니다.
Typically, a conversation is formatted with a system message first, followed by alternating user and assistant messages.
일반적으로 대화는 먼저 System 메세지로 틀을 잡고 다음에 User와 Assistant 메세지가 번갈이 표시되게 됩니다.
The system message helps set the behavior of the assistant. In the example above, the assistant was instructed with “You are a helpful assistant.”
System 메세지는 Assistant의 행동을 설정하는데 도움이 됩니다. 위에 메세지에서 System 메세지는 Assistant에게 "당신은 도움을 주는 도우미 입니다" 라고 설정을 해 줬습니다.
The user messages help instruct the assistant. They can be generated by the end users of an application, or set by a developer as an instruction.
User 메세지는 Assistant에게 instruct (지시) 하도록 도와 줍니다. 이 메세지는 해당 어플리케이션의 사용자가 생성하게 됩니다. 혹은 개발자가 instruction으로서 생성하게 될 수도 있습니다.
The assistant messages help store prior responses. They can also be written by a developer to help give examples of desired behavior.
Assistant 메세지는 prior responses를 저장하는데 도움을 줍니다. 이 메세지도 개발자가 작성할 수 있습니다. gpt-3.5-turbo 모델이 어떤 식으로 응대할지에 대한 예를 제공합니다. (캐주얼하게 작성을 하면 ChatAPI 모델은 그것에 맞게 캐주얼한 형식으로 답변을 제공하고 formal 하게 제시하면 그 모델은 그에 맞게 formal 한 형식으로 답변을 제공할 것입니다.)
Including the conversation history helps when user instructions refer to prior messages. In the example above, the user’s final question of “Where was it played?” only makes sense in the context of the prior messages about the World Series of 2020. Because the models have no memory of past requests, all relevant information must be supplied via the conversation. If a conversation cannot fit within the model’s token limit, it will need to be shortened in some way.
이미 오고간 대화들을 제공하면 user 가 instruction을 제공하기 이전의 메세지로서 참조가 됩니다. 즉 그 대화의 분위기나 형식에 맞는 응답을 받게 될 것입니다. 위의 에에서 user의 마지막 질문은 "Where was it played?" 입니다.
이전의 대화들이 있어야지만이 이 질문이 무엇을 의미하는지 알 수 있습니다. 이전의 대화들이 2020년 월드 시리즈에 대한 내용들이었기 때문에 이 질문의 의미는 2020년 월드 시리즈는 어디에서 개최 됐느냐는 질문으로 모델을 알아 듣게 됩니다.
이 모델은 과거 request들에 대한 기억이 없기 때문에 이런 식으로 관련 정보를 제공합니다.
Request에는 모델별로 사용할 수 있는 Token 수가 정해져 있습니다. Request가 이 Token 수를 초과하지 않도록 작성해야 합니다.
Response format
이 API의 response는 아래와 같은 형식입니다.
{
'id': 'chatcmpl-6p9XYPYSTTRi0xEviKjjilqrWU2Ve',
'object': 'chat.completion',
'created': 1677649420,
'model': 'gpt-3.5-turbo',
'usage': {'prompt_tokens': 56, 'completion_tokens': 31, 'total_tokens': 87},
'choices': [
{
'message': {
'role': 'assistant',
'content': 'The 2020 World Series was played in Arlington, Texas at the Globe Life Field, which was the new home stadium for the Texas Rangers.'},
'finish_reason': 'stop',
'index': 0
}
]
}
파이썬에서 assistant의 응답은 다음과 같은 방법으로 추출 될 수 있습니다.
response[‘choices’][0][‘message’][‘content’]
Managing tokens
Language models read text in chunks called tokens. In English, a token can be as short as one character or as long as one word (e.g.,aorapple), and in some languages tokens can be even shorter than one character or even longer than one word.
Language 모델은 토큰이라는 chunk로 텍스트를 읽습니다. 영어에서 토큰은 글자 하나인 경우도 있고 단어 하나인 경우도 있습니다. (예. a 혹은 apple). 영어 이외의 다른 언어에서는 토큰이 글자 하나보다 짧거나 단어 하나보다 길 수도 있습니다.
For example, the string“ChatGPT is great!”is encoded into six tokens:[“Chat”, “G”, “PT”, “ is”, “ great”, “!”].
예를 들어 ChatGPT is great! 이라는 문장은 다음과 같이 6개의 토큰으로 구성됩니다. [“Chat”, “G”, “PT”, “ is”, “ great”, “!”]
The total number of tokens in an API call affects: How much your API call costs, as you pay per token How long your API call takes, as writing more tokens takes more time Whether your API call works at all, as total tokens must be below the model’s maximum limit (4096 tokens forgpt-3.5-turbo-0301)
APPI 호출의 총 토큰수는 다음과 같은 사항들에 영향을 미칩니다. : 해당 API 호출에 얼마가 과금이 될지 여부. 대개 1000개의 토큰당 요금이 과금이 되기 때문에 토큰이 아주 길면 그만큼 과금이 더 될 수 있습니다. 이는 토큰이 많을 수록 API 호출을 처리하는데 시간이 더 걸리기 때문이죠. request의 전체 토큰 수는 제한량을 넘을 수 없습니다. (gpt-3.5-turbo-0301 의 경우 4096 개의 토큰이 제한량입니다.)
Both input and output tokens count toward these quantities. For example, if your API call used 10 tokens in the message input and you received 20 tokens in the message output, you would be billed for 30 tokens.
입력 및 출력 토큰 모두 해당 호출의 토큰수에 포함됩니다. 예를 들어 API 호출에서 입력값으로 10개의 토큰을 사용했고 output으로 20개의 토큰을 받을 경우 30개의 토큰에 대해 과금 됩니다.
To see how many tokens are used by an API call, check theusagefield in the API response (e.g.,response[‘usage’][‘total_tokens’]).
API 호출에서 사용되는 토큰의 수를 확인 하려면 API response 중 usage 필드를 확인하시면 됩니다. (e.g., response[‘usage’][‘total_tokens’]).
To see how many tokens are in a text string without making an API call, use OpenAI’stiktokenPython library. Example code can be found in the OpenAI Cookbook’s guide onhow to count tokens with tiktoken.
Each message passed to the API consumes the number of tokens in the content, role, and other fields, plus a few extra for behind-the-scenes formatting. This may change slightly in the future.
API에 전달된 각각의 메세지는 content, role 그리고 다른 필드들에서 토큰이 소비 됩니다. 그리고 이런 필드들 이외에도 서식관련 해서 공간을 사용해야 하기 때문에 토큰이 소비 되는 부분도 있습니다. 자세한 사항들은 차후에 변경될 수도 있습니다.
If a conversation has too many tokens to fit within a model’s maximum limit (e.g., more than 4096 tokens forgpt-3.5-turbo), you will have to truncate, omit, or otherwise shrink your text until it fits. Beware that if a message is removed from the messages input, the model will lose all knowledge of it.
대화에 토큰이 너무 많이 모델의 허용 한도 이내에서 작성할 수 없을 경우 (예: gpt-3.5-turbo의 경우 4096개가 제한량임) 그 한도수 이내가 될 때까지 자르거나 생략하거나 축소해야 합니다. message 입력값에서 message 부분이 제한량 초과로 날아가 버리면 모델은 이에 대한 모든 knowledge들을 잃게 됩니다.
Note too that very long conversations are more likely to receive incomplete replies. For example, agpt-3.5-turboconversation that is 4090 tokens long will have its reply cut off after just 6 tokens.
매우 긴 대화는 불완전한 답변을 받을 가능성이 더 높습니다. 이점에 유의하세요. 예를 들어 gpt-3.5-turbo 의 대화에 4090개의 토큰이 입력값에서 사용됐다면 출력값으로는 6개의 토큰만 받고 그 나무지는 잘려 나갑니다.
Instructing chat models
Best practices for instructing models may change from model version to version. The advice that follows applies to gpt-3.5-turbo-0301 and may not apply to future models.
모델에 instructing 하는 가장 좋은 방법은 모델의 버전마다 다를 수 있습니다. 다음에 나오는 내용은 gpt-3.5-turbo-0301 버전에 적용됩니다. 그 이후의 모델에는 적용될 수도 있고 적용되지 않을 수도 있습니다.
Many conversations begin with a system message to gently instruct the assistant. For example, here is one of the system messages used for ChatGPT:
assistant에게 젠틀하게 지시하는 system 메세지로 많은 대화들을 시작하세요. 예를 들어 ChatGPT에서 사용되는 시스템 메세지 중 하나를 아래에 보여드리겠습니다.
You are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible. Knowledge cutoff: {knowledge_cutoff} Current date: {current_date}
In general,gpt-3.5-turbo-0301does not pay strong attention to the system message, and therefore important instructions are often better placed in a user message.
일반적으로 gpt-3.5-turbo-0301은 System 메세지의 크게 주의를 기울이지 않으므로 핵심 instruction은 User 메세지에 주로 배치 됩니다.
If the model isn’t generating the output you want, feel free to iterate and experiment with potential improvements. You can try approaches like:
모델의 output 이 원하는 대로 안 나오면 잠재적인 개선을 이끌수 있는 반복과 실험을 하는데 주저하지 마세요. 예를 들어 아래와 같이 접근 할 수 있습니다.
Make your instruction more explicit
명료하게 지시를 하세요.
Specify the format you want the answer in
응답을 받고자 하는 형식을 특정해 주세요.
Ask the model to think step by step or debate pros and cons before settling on an answer
모델이 최종 답을 결정하기 전에 단계별로 생각하거나 장단넘에 대해 debate을 해 보라고 요청하세요.
Beyond the system message, the temperature and max tokens aretwo of many optionsdevelopers have to influence the output of the chat models. For temperature, higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. In the case of max tokens, if you want to limit a response to a certain length, max tokens can be set to an arbitrary number. This may cause issues for example if you set the max tokens value to 5 since the output will be cut-off and the result will not make sense to users.
System 메세지 이외에도 temperature와 max token은 채팅 모델의 output에 영향을 주는 많은 옵션 중 두가지 옵션 입니다.
Temperature의 경우 0.8 이상의 값은 output을 더 random 하게 만듭니다. 그보다 값이 낮으면 예를 들어 0.2 뭐 이렇게 되면 더 focused 하고 deterministic 한 답변을 내 놓습니다. max token의 경우 여러분이 답변을 특정 길이로 제한하고 싶을 때 이 max token을 임의의 숫자로 세팅할 수 있습니다. 이것을 사용할 때는 주의하셔야 합니다. 예를 들어 최대 토큰 값을 5처럼 아주 낮게 설정하면 output이 잘리고 사용자에게 의미가 없을 수 있기 때문에 문제가 발생할 수 있습니다.
Chat vs Completions
Becausegpt-3.5-turboperforms at a similar capability totext-davinci-003but at 10% the price per token, we recommendgpt-3.5-turbofor most use cases.
gpt-3.5-turbo는 text-davinci-003과 비슷한 성능을 보이지만 토큰당 가격은 10% 밖에 하지 않습니다. 그렇기 때문에 우리는 대부분의 사용 사례에 gpt-3.5-turbo를 사용할 것을 권장합니다.
For many developers, the transition is as simple as rewriting and retesting a prompt.
많은 개발자들에게 transition은 프롬프트를 rewriting 하고 retesting 하는 것 만큼 아주 간단합니다.
For example, if you translated English to French with the following completions prompt:
예를 들어 여러분이 영어를 불어로 아래와 같이 completions prompt로 번역한다면,
Translate the following English text to French: “{text}”
이 채팅 모델로는 아래와 같이 할 수 있습니다.
[
{“role”: “system”, “content”: “You are a helpful assistant that translates English to French.”},
{“role”: “user”, “content”: ‘Translate the following English text to French: “{text}”’}
]
혹은 이렇게 user 메세지만 주어도 됩니다.
[
{“role”: “user”, “content”: ‘Translate the following English text to French: “{text}”’}
]
FAQ
Is fine-tuning available forgpt-3.5-turbo?
gpt-3.5-turbo에서도 fine-tuning이 가능한가요?
No. As of Mar 1, 2023, you can only fine-tune base GPT-3 models. See thefine-tuning guidefor more details on how to use fine-tuned models.
아니오. 2023년 3월 1일 현재 GPT-3 모델 기반에서만 fine-tune을 할 수 있습니다. fine-tuned 모델을 어떻게 사용할지에 대한 자세한 사항은 fine-tuning guide 를 참조하세요.
Do you store the data that is passed into the API?
OpenAI는 API로 전달된 데이터를 저장해서 갖고 있습니까?
As of March 1st, 2023, we retain your API data for 30 days but no longer use your data sent via the API to improve our models. Learn more in ourdata usage policy.
2023년 3월 1일 현재 OpenAI는 여러분의 API 데이터를 30일간 유지하고 있습니다. 하지만 여러분이 API를 통해 보낸 데이터들은 오리의 모델을 개선하는데 사용하지는 않습니다. 더 자세한 사항은 data usage policy 를 참조하세요.
Adding a moderation layer
조정 레이어 추가하기
If you want to add a moderation layer to the outputs of the Chat API, you can follow ourmoderation guideto prevent content that violates OpenAI’s usage policies from being shown.
Chat API의 output에 moderation 레이어를 추가할 수 있습니다. moderation 레이어를 추가하려는 경우 OpenAI의 사용 정책을 위반하는 내용이 표시되지 않도록 moderatin guide를 따라 주세요.