

https://d2l.ai/chapter_computer-vision/index.html
14. Computer Vision — Dive into Deep Learning 1.0.0 documentation
d2l.ai
14. Computer Vision

Whether it is medical diagnosis, self-driving vehicles, camera monitoring, or smart filters, many applications in the field of computer vision are closely related to our current and future lives. In recent years, deep learning has been the transformative power for advancing the performance of computer vision systems. It can be said that the most advanced computer vision applications are almost inseparable from deep learning. In view of this, this chapter will focus on the field of computer vision, and investigate methods and applications that have recently been influential in academia and industry.
의료 진단, 자율 주행 차량, 카메라 모니터링 또는 스마트 필터 등 컴퓨터 비전 분야의 많은 응용 프로그램은 현재와 미래의 삶과 밀접한 관련이 있습니다. 최근 몇 년 동안 딥 러닝은 컴퓨터 비전 시스템의 성능을 향상시키는 변혁적인 힘이었습니다. 가장 진보된 컴퓨터 비전 응용 프로그램은 딥 러닝과 거의 분리할 수 없다고 말할 수 있습니다. 이를 고려하여 이 장에서는 컴퓨터 비전 분야에 초점을 맞추고 최근 학계와 산업계에 영향을 미치고 있는 방법과 응용을 조사합니다.
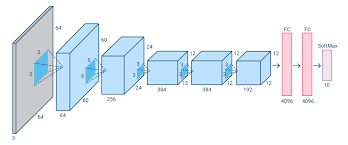
In Section 7 and Section 8, we studied various convolutional neural networks that are commonly used in computer vision, and applied them to simple image classification tasks. At the beginning of this chapter, we will describe two methods that may improve model generalization, namely image augmentation and fine-tuning, and apply them to image classification. Since deep neural networks can effectively represent images in multiple levels, such layerwise representations have been successfully used in various computer vision tasks such as object detection, semantic segmentation, and style transfer. Following the key idea of leveraging layerwise representations in computer vision, we will begin with major components and techniques for object detection. Next, we will show how to use fully convolutional networks for semantic segmentation of images. Then we will explain how to use style transfer techniques to generate images like the cover of this book. In the end, we conclude this chapter by applying the materials of this chapter and several previous chapters on two popular computer vision benchmark datasets.
7절과 8절에서는 컴퓨터 비전에서 흔히 사용되는 다양한 컨볼루션 신경망을 연구하고 이를 간단한 이미지 분류 작업에 적용하였다. 이 장의 시작 부분에서 모델 일반화를 개선할 수 있는 두 가지 방법, 즉 이미지 확대 및 미세 조정을 설명하고 이미지 분류에 적용할 것입니다. 심층 신경망은 여러 수준에서 이미지를 효과적으로 표현할 수 있기 때문에 이러한 레이어별 표현은 개체 감지, 의미론적 분할 및 스타일 전송과 같은 다양한 컴퓨터 비전 작업에서 성공적으로 사용되었습니다. 컴퓨터 비전에서 계층별 표현을 활용하는 핵심 아이디어에 따라 물체 감지를 위한 주요 구성 요소와 기술부터 시작하겠습니다. 다음으로 이미지의 시맨틱 분할을 위해 완전 컨벌루션 네트워크를 사용하는 방법을 보여줍니다. 그런 다음 스타일 변환 기술을 사용하여 이 책의 표지와 같은 이미지를 생성하는 방법을 설명합니다. 마지막으로 이 장의 자료와 두 가지 인기 있는 컴퓨터 비전 벤치마크 데이터 세트에 대한 이전 장의 여러 장을 적용하여 이 장을 마무리합니다.
'Dive into Deep Learning > D2L Computer Vision' 카테고리의 다른 글
| D2L - 14.10. Transposed Convolution (1) | 2023.08.21 |
|---|---|
| D2L - 14.9. Semantic Segmentation and the Dataset (0) | 2023.08.20 |
| D2L - 14.8. Region-based CNNs (R-CNNs) (0) | 2023.08.20 |
| D2L - 14.7. Single Shot Multibox Detection (0) | 2023.08.19 |
| D2L - 14.6. The Object Detection Dataset (0) | 2023.08.19 |
| D2L - 14.5. Multiscale Object Detection (0) | 2023.08.19 |
| D2L - 14.4. Anchor Boxes (0) | 2023.08.19 |
| D2L - 14.3. Object Detection and Bounding Boxes (0) | 2023.08.19 |
| D2L - 14.2. Fine-Tuning (0) | 2023.08.19 |
| D2L - 14.1. Image Augmentation (0) | 2023.08.19 |