6월 AWS Deepracer Virtual Race에 참가하기 위해 자율주행을 위한 인공지능 모델을 훈련 시키면서 생겼던 질문을 AWS Deepracer Forum에 몇번 올렸었다.
https://forums.aws.amazon.com/forum.jspa?forumID=318
도움이 되는 답변들이 있어서 여기에 정리해 둔다.
https://forums.aws.amazon.com/thread.jspa?threadID=304352&tstart=0
첫번째 질문은 Action Space와 Hyperparameter에 대한 것이었다.
| What is good Action Space and Hyperparameter for Kumo Torakku track?
Posted by: Changsoo Posted on: Jun 6, 2019 5:13 AM |
|
|
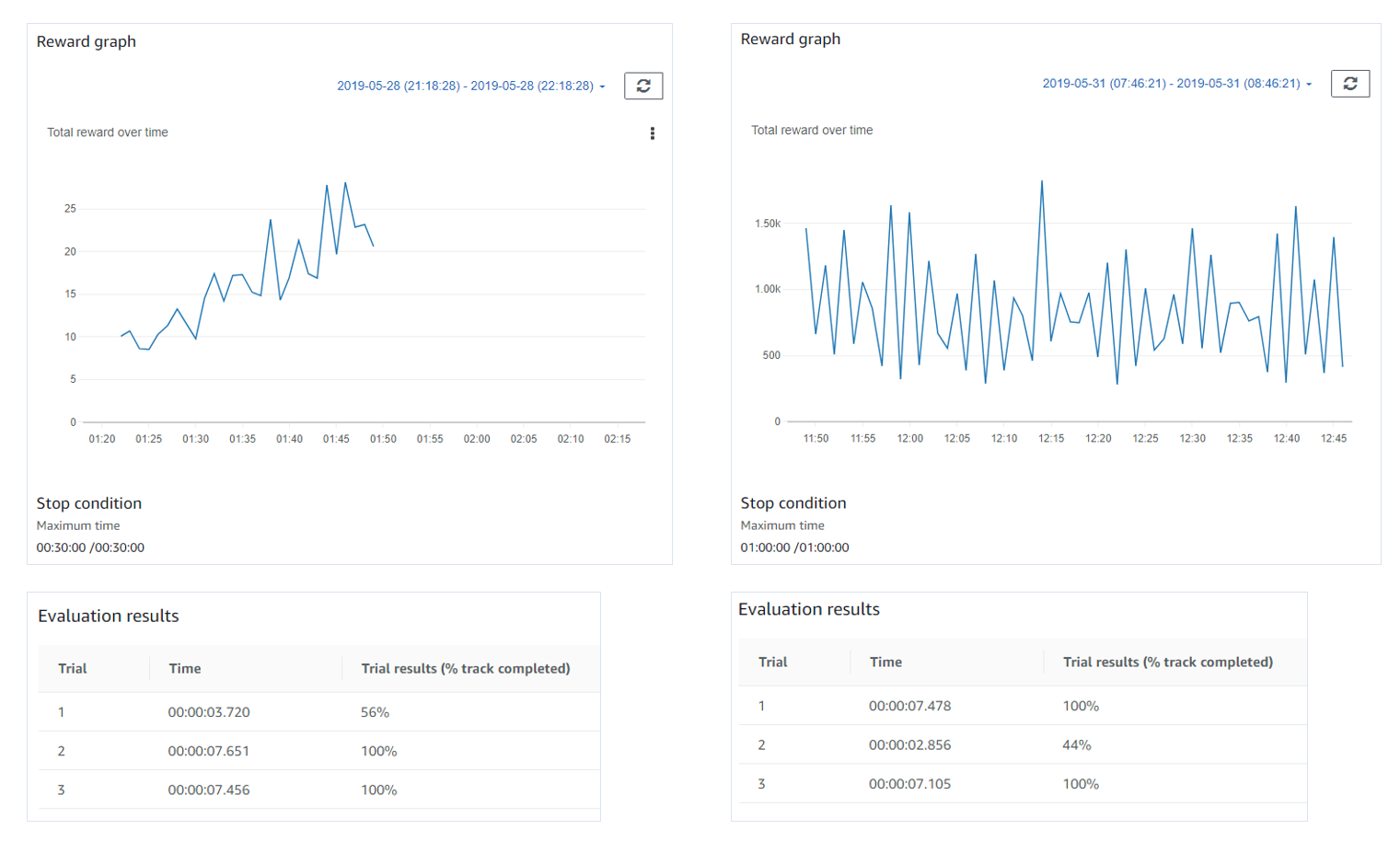
I've created a model for Kumo Torakku track and got 26 seconds lap time.
Actually the model was cloned from others. (Straight Track -> Oval Track -> London Loop).
Repetition of training does not reduce lap time.
I used hyperparameter as default and changed the Maximum speed to 5 in Action Space.
(Others are as default. Steering 30, Steering angle granularity 5, Speed granularity 2)
Since I'm familiar with coding, I tried multiple things with reward_function.
i.e. distance from center, all wheels on track, steering threshold, speed penalty etc.
As I said, there is no improvement at all with this configuration for Kumo Torakku.
So I will create new Model.
Anybody recommend any Action Space configuration for Kumo Torakku to get better results please?
Maximum steering angle :
Steering angle granualrity :
Maximum speed :
Speed granuality :
I have read documents for Hyperparameters but no idea what those are. ;(
Anybody can recommend good Hyperparameters configuration for Kumo Torakku please?
아래는 이 질문에 대한 답변들....
| Re: What is good Action Space and Hyperparameter for Kumo Torakku track?
Posted by: DeClercq-AWS Posted on: Jun 10, 2019 11:12 PM in response to: Changsoo |
Hyperparameters directly impact how the model is updated, they control the settings of the optimization algorithm that is used to "solve" for the model that gives the maximum expected cumulative return. Changing hyperparameters can improve the convergence of the model, or worsen it. For example, if you increase the learning rate, the weights in your neural network will update with larger increments. The model may improve (train) faster but the risk is that you miss the optimal solution, or the model never converges as updates are too large. Finding good hyperparameters often required trying a number of different combinations and then evaluating the performance of the model vs time spent training or some other metric. For example, I am busy training a 3m/s model (with 2 speed granularity) using a learning race of 0.001 and a low number of epochs. I can see during training at around 90 minutes my model is starting to do a lap now and then. If the learning rate was smaller, it would probably take longer for my model to complete a lap.
Hyperparameters는 모델이 업데이트되는 방식에 직접적으로 영향을 주며, 최적화 알고리즘의 세팅을 컨트롤 합니다. 이는 기대되는 누적된 return의 최대치를 주도록 모델에 대한 'solve'에 사용됩니다. Hyperparameters를 변경하면 모델의 수렴성이 향상되거나 악화 될 수 있습니다. 예를 들어, learning rate를 높이면 신경망의 weights가 더 큰 폭으로 증가하게 됩니다. 모델이 더 빠르게 향상 될 수는 있지만 최적의 솔루션이 누락되거나 업데이트가 너무 많아서 모델이 수렴하지 않을 위험이 있습니다. 훌륭한 Hyperparameters를 찾는 일은 종종 여러 가지 조합을 시도한 다음 모델의 퍼포먼스, 트레이닝 시간이나 다른 메트릭 등을 비교하면서 평가합니다. 예를 들어, 나는 0.001의 learning race와 낮은 epochs 수를 사용하여 3m / s 모델 (2 speed granularity)을 훈련 중입니다. 나는 약 90 분 후에 현재의 lap에 도달 하는 것을 경헙했습니다. 만약 learning rate가 더 낮 으면 내 모델이 lap에 도달할 때까지 더 오래 걸릴 것입니다.
Note that at 3m/s my model will not be as fast as a converged 5m/s (or faster) model, but those will take a long time to converge. We increased the training speed in the console to a max of 8 m/s. Training at speeds faster than 8m/s tends to send the model spinning off the track.
3m / s에서 내 모델은 converged 된 5m / s (또는 더 빠른) 모델만큼 빠르지는 않을 것이지만, 5m/s (or faster) model은 converged 하는데 오랜 시간이 걸릴 것입니다. 우리는 콘솔의 교육 속도를 최대 8 m / s로 높였습니다. 8m / s보다 빠른 속도로 훈련하면 트랙에서 모델이 회전하는 경향이 있습니다.
Kind regards
De Clercq
| Re: What is good Action Space and Hyperparameter for Kumo Torakku track?
Posted by: DeClercq-AWS Posted on: Jun 11, 2019 10:46 AM in response to: Changsoo |
Hi Changsoo
I did the following tests overnight to show impact of hyperparameters
나는 지난 밤에 hyperparameters의 영향을 보기 위해 다음과 같은 테스트들을 진행했습니다.
Trained 4 models on the Kumo Torakku training, each for 180 minutes, using my own reward function that does some center line following, scales reward for driving fast etc.
Kumo Torakku 트랙에서 4개의 모델을 훈련 시켰습니다. 각각의 훈련 시간은 180분 입니다. reward function은 제것을 사용했습니다. 여기에느느 중앙선 따르기, 빠르게 드라이브하기 등에 reward를 주는 로직등이 있습니다.
I alternated
Model 1: 3 m/s 2 speed granularity with learning rate = 0.001 and epochs = 3
Model 2: 3 m/s 2 speed granularity with default hyperparameters
Model 3: 5 m/s 2 speed granularity with learning rate = 0.001 and epochs = 3
Model 4: 5 m/s 2 speed granularity with default hyperparameters
Doing 5 lap evaluation on Kumo Torakku training, showing lap completion percentages
Kumo Torakku 트랙에서 5 lap evaluation을 진행했으며 lap completion percentages는 다음과 같습니다.
Model 1: 100% 100% 100% 100% 100%
Model 2: 46% 67% 61% 100% 62%
Model 3: 70% 58% 100% 100% 100%
Model 4: 63% 88% 100% 36% 27%
This shows you the impact of playing with the hyperparameters.
이 예에서 당신은 hyperparameters가 주는 영향을 보실 수 있을 겁니다.
Kind regards
De Clercq
| Re: What is good Action Space and Hyperparameter for Kumo Torakku track?
Posted by: Amazon Customer Posted on: Jun 14, 2019 10:48 AM in response to: Changsoo |
I copied all these waypoints out from the kumo log if it helps anyone.
https://gist.github.com/joezen777/98daa6496acf6a6df3269f253f9388f9
Draw Kumo Map
Draw Kumo Map. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
| Re: What is good Action Space and Hyperparameter for Kumo Torakku track?
Posted by: DeClercq-AWS Posted on: Jun 14, 2019 4:21 PM in response to: Amazon Customer |
Hi
To get the waypoints you can download the track's .npy file and use the code in the log-analysis workbook to extract them
Log-analysis is here
https://github.com/aws-samples/aws-deepracer-workshops/tree/master/log-analysis
Track npys are here
https://github.com/aws-samples/aws-deepracer-workshops/tree/master/log-analysis/tracks
See breadcentric's blog on how to use log-analysis (link is in the Pit Stop page)
https://aws.amazon.com/deepracer/racing-tips/
Kind regards
De Clercq
| Re: What is good Action Space and Hyperparameter for Kumo Torakku track?
Posted by: cladeira Posted on: Jun 23, 2019 1:52 PM in response to: DeClercq-AWS |
Hi @DeClercq-AWS,
I'm using your script, but i have a couple of questions:
1- Are Yaw and Steering on Degrees or Radians? It seems to be in Radians.
2- How can we include other parameters?
3- It seems Track Width is not returning the right value. How can we confirm?
4- Is Progress defined from 0-1 or 0-100? It seems it's based on 0-1, but the documentation says 0-100.
Thanks,
cladeira
두번째 질문은 reward_function으로 속도를 높이는 데 대한 질문이었다.
| updated reward function to speed up but not working as expected.
Posted by: Changsoo Posted on: Jul 2, 2019 11:24 AM |
Hi
I updated reward_function to speed up using params but not working as expected.
The reward_function is this
=====================================
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
reward=1e-3
# Read input parameters
track_width = params
distance_from_center = params
steering = params
speed = params
all_wheels_on_track = params
steps = params
progress = params
# Total num of steps we want the car to finish the lap, it will vary depends on the track length
TOTAL_NUM_STEPS = 300
if distance_from_center >=0.0 and distance_from_center <= 0.03:
reward = 1.0
if not all_wheels_on_track:
reward = reward -1
else:
reward = reward + progress
# add speed penalty
if speed < 1.0:
reward *=0.80
else:
reward += speed
# Give additional reward if the car pass every 100 steps faster than expected
if (steps % 50) == 0 and progress > (steps / TOTAL_NUM_STEPS) :
reward += 10.0
return float(reward)
==================================================
There was no lines with bold in previous model.
I trained for 5 hours but the result is slower than before.
with Previous model, I could get 21~24 seconds to run the Empire City track but with the new model after training for 5 hour, I am getting 24~27 seconds.
Other Action space and hyperparameters are same.
Anybody knows why the result is slower than before?
| Re: updated reward function to speed up but not working as expected.
Posted by: ETAGGEL Posted on: Jul 3, 2019 1:51 AM in response to: Changsoo |
Hi,
You could insert some debug code to ensure it is getting applied, e.g. print("Fast reward bonus given").
디버그를 위한 코드를 넣어서 해당 부분이 제대로 적용되는지를 살펴 보실 수 있습니다. e.g. print("Fast reward bonus given").
However, looking at your code, I think the issue is that progress is a value from 0-100, where as your steps / TOTAL_NUM_STEPS gives a fraction 0-1. So progress will nearly always be greater than that, and so your bonus is probably being given regardless of actual performance.
코드를 살펴보면 progress는 0-100 사이의 값이며, steps / TOTAL_NUM_STEPS는 0에서 1 사이의 fraction이 됩니다. progress는 항상 steps / TOTAL_NUM_STEPS 보다 더 높을 것이므로 실제 퍼포먼스에 상관없이 reward가 주어지는 것 같습니다.
I'm also not sure that a bonus of 10 every 50 steps would be enough to encourage the model to favour those actions. It would also depend on your discount rate, e.g. if you're using the default discount rate of 0.9 then that only equates to 10 steps look ahead, so your bonus would be invisible to most policy training updates.
50 단계마다 10 씩 보너스가 주어지면 모델이 그 행동을 선호하도록 장려하기에 충분하지 않을 것입니다. 이것은 당신의 discount rate에 따라 그 영향이 달라 질 수 있습니다. e.g. 디폴트 discount rate인 0.9를 사용하는 경우 10 steps를 앞당겨 look ahead 하므로 보너스는 대부분의 정책 교육 업데이트에서 볼 수 없습니다.
Finally, you need to be careful of overfitting your model to the track. When that happens, lap times can get worse as the model learns the safer actions/track position to ensure more stability. So that might explain why your model got slower, even if your reward wasn't correctly being applied.
마지막으로 해당 트랙에 모델을 너무 많이 맞추는 것에 조심해야 합니다. 이러한 상황이 발생하면 모델이 안정성을 위해 좀 더 안전한 액션과 트랙 위치를 배우게 되어 랩 타임은 오히려 악화 될 수 있습니다. 따라서 보상이 올바르게 적용되지 않은 경우에도 모델이 왜 느려 졌는지 설명 할 수 있습니다.
Lyndon
aws-samples/aws-deepracer-workshops
DeepRacer workshop content. Contribute to aws-samples/aws-deepracer-workshops development by creating an account on GitHub.
github.com
'IoT > AWS DeepRacer' 카테고리의 다른 글
| Robolink Zumi 도착 (0) | 2019.08.28 |
|---|---|
| AWS Deepracer 이렇게만 하면 상위권 간다. (0) | 2019.08.06 |
| AWS Deepracer Virtual Circuit The Empire City 2019/7 (0) | 2019.08.04 |
| AWS DeepRacer League - New York을 다녀와서 (0) | 2019.07.24 |
| Using Jupyter Notebook for analysing DeepRacer's logs (0) | 2019.07.23 |
| AWS Deepracer Virtual Race 최초 참가 경험 정리 (0) | 2019.07.07 |
| MEGAZONE CLOUD AWS DeepRacer League in Korea (0) | 2019.06.25 |
| 테슬라 주가와 2011년 넷플릭스 주가 비교 (0) | 2019.06.05 |
| AWS DeepRacer League and 2nd Virtual Race open (1) | 2019.06.04 |
| AWS Deepracer - Oval and London loop track model 훈련 결과 (0) | 2019.06.03 |