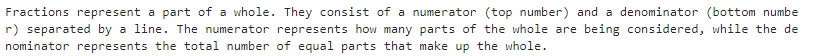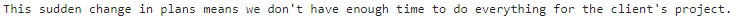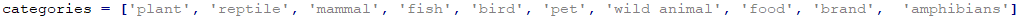개발자로서 현장에서 일하면서 새로 접하는 기술들이나 알게된 정보 등을 정리하기 위한 블로그입니다. 운 좋게 미국에서 큰 회사들의 프로젝트에서 컬설턴트로 일하고 있어서 새로운 기술들을 접할 기회가 많이 있습니다. 미국의 IT 프로젝트에서 사용되는 툴들에 대해 많은 분들과 정보를 공유하고 싶습니다.
제목에서는 GPT-4 가 Open AI의 가장 진보된 시스템이고 더 안전하고 유용한 답변을 한다고 돼 있습니다.
이 GPT-4 API를 사용하려면 API waitlist에 등록 해야 합니다.
GPT-4는 폭넓은 일반 지식과 문제 해결 능력 덕분에 어려운 문제를 더 정확하게 풀 수 있습니다.
라고 말을 하고 있고 그 아래 GPT-4에서 개선 된 부분들에 대해 나옵니다.
우선 Creativity와 Visual input 그리고 Longer context 이렇게 3개의 탭이 있습니다.
Creativity 부터 볼까요?
GPT4 is more creative and collaborative than ever before. It can generate, edit, and iterate with users on creative and technical writing tasks, such as composing songs, writing screenplays, or learning a user’s writing style.
GPT-4는 그 어느 때보다 창의적이고 협력적입니다. 노래 작곡, 시나리오 작성 또는 사용자의 작문 스타일 학습과 같은 창의적이고 기술적인 작문 작업에서 사용자와 함께 생성, 편집 및 반복할 수 있습니다.
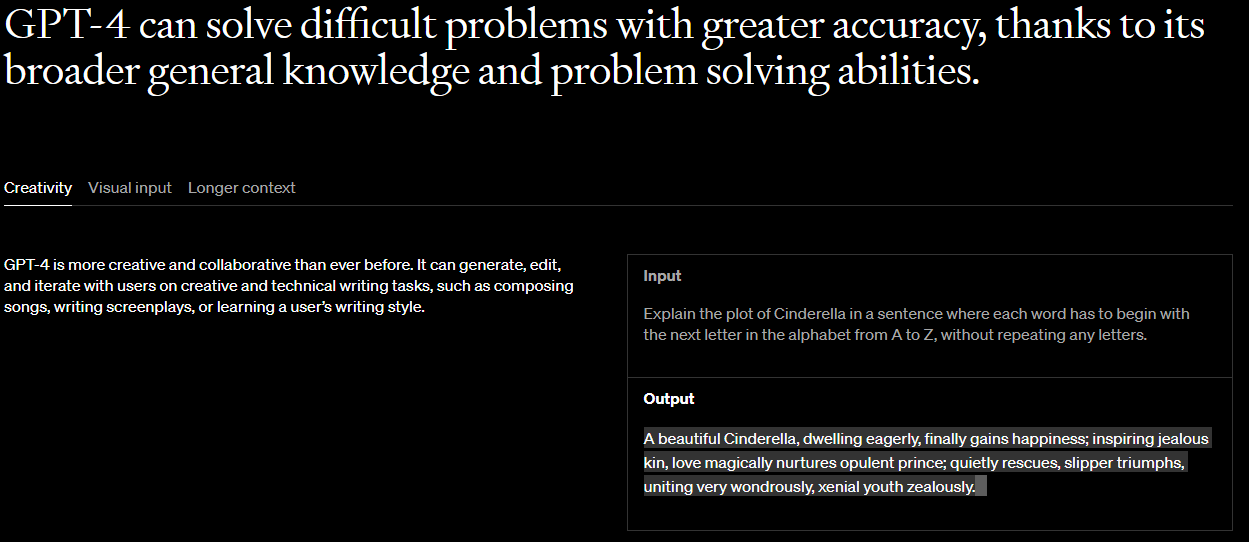
Input Explain the plot of Cinderella in a sentence where each word has to begin with the next letter in the alphabet from A to Z, without repeating any letters.
Output A beautiful Cinderella, dwelling eagerly, finally gains happiness; inspiring jealous kin, love magically nurtures opulent prince; quietly rescues, slipper triumphs, uniting very wondrously, xenial youth zealously.
input으로 아래와 같은 요구를 했습니다.
문자를 반복하지 않고 A부터 Z까지 알파벳의 다음 문자로 각 단어가 시작되어야 하는 문장으로 신데렐라의 줄거리를 설명합니다.
그랬더니 신데렐라의 줄거리를 진짜 A 부터 Z까지 시작하는 단어들을 차례대로 사용해서 설명을 했습니다.
두번째는 Visual input 분야 입니다.
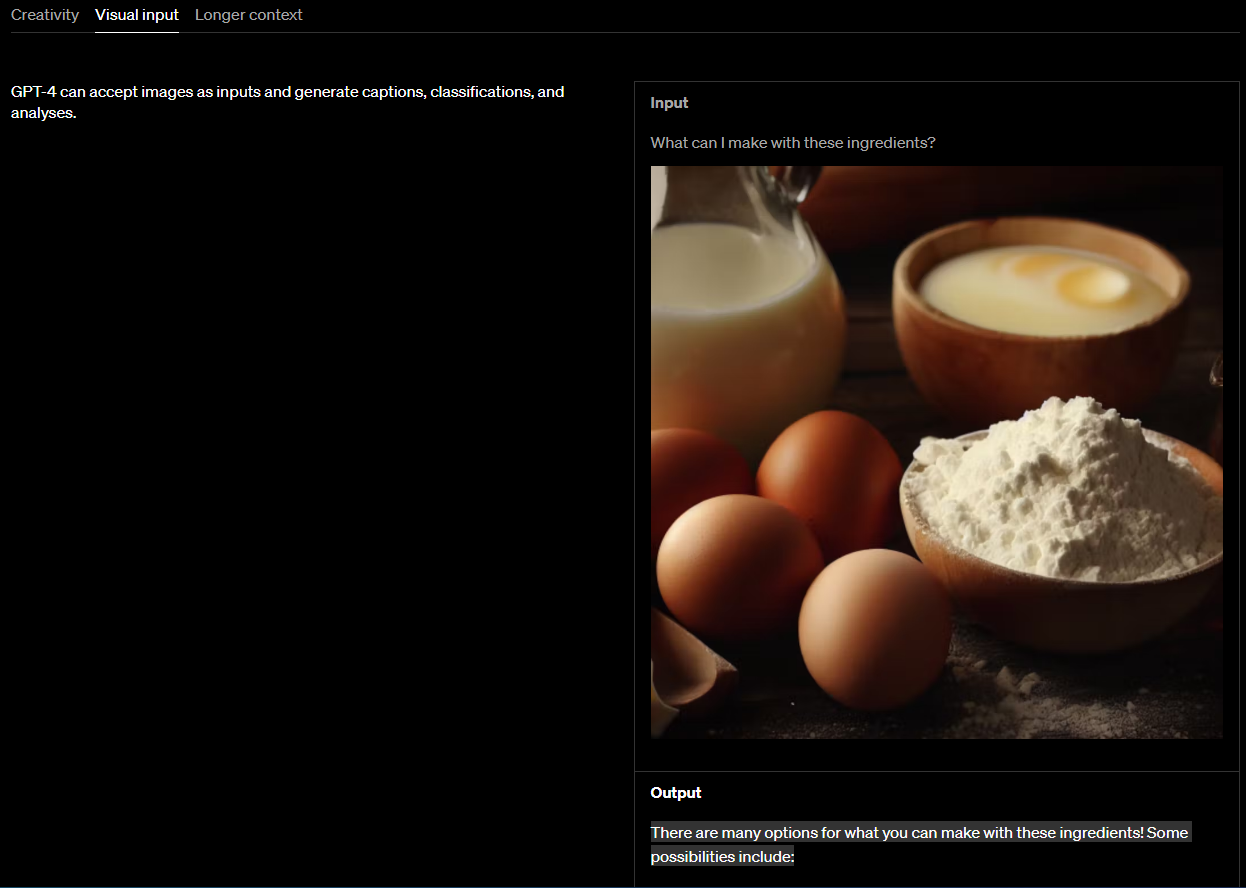
이미지 파일을 주고 이 재료들을 가지고 무엇을 만들 수 있냐고 물었더니...
Output There are many options for what you can make with these ingredients! Some possibilities include:
- Pancakes or waffles - Crepes - French toast - Omelette or frittata - Quiche - Custard or pudding - Cake or cupcakes - Muffins or bread- Cookies or biscuits
These are just a few examples, but the possibilities are endless! few examples, but the possibilities are endless!
이런 답변을 했네요. 그림만 보고 그 안에 있는 재료들을 판단해서 거기에 맞는 가능한 요리들을 보여 줬습니다.
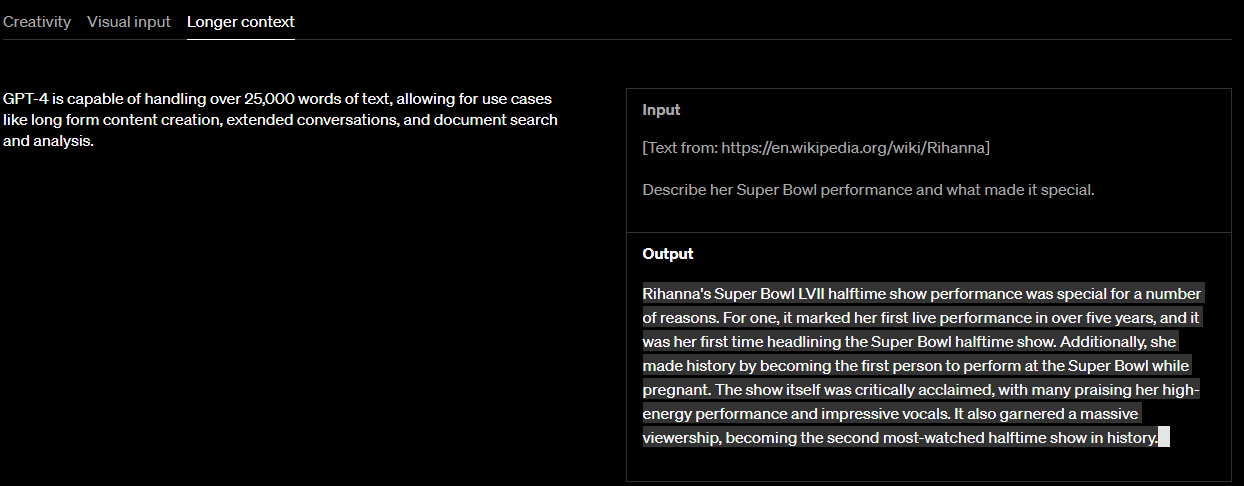
그 다음은 아주 긴 input 값을 받을 수 있다는 내용입니다.
GPT-4 is capable of handling over 25,000 words of text, allowing for use cases like long form content creation, extended conversations, and document search and analysis.
GPT-4는 25,000단어 이상의 텍스트를 처리할 수 있어 긴 형식의 콘텐츠 생성, 확장된 대화, 문서 검색 및 분석과 같은 사용 사례를 허용합니다.
예제로는 리하나의 위키피디아의 내용을 입력값으로 주고 이번 Super Bowl 공연에 대해 물어보고 GPT-4 가 대답하는 내용이 있습니다.
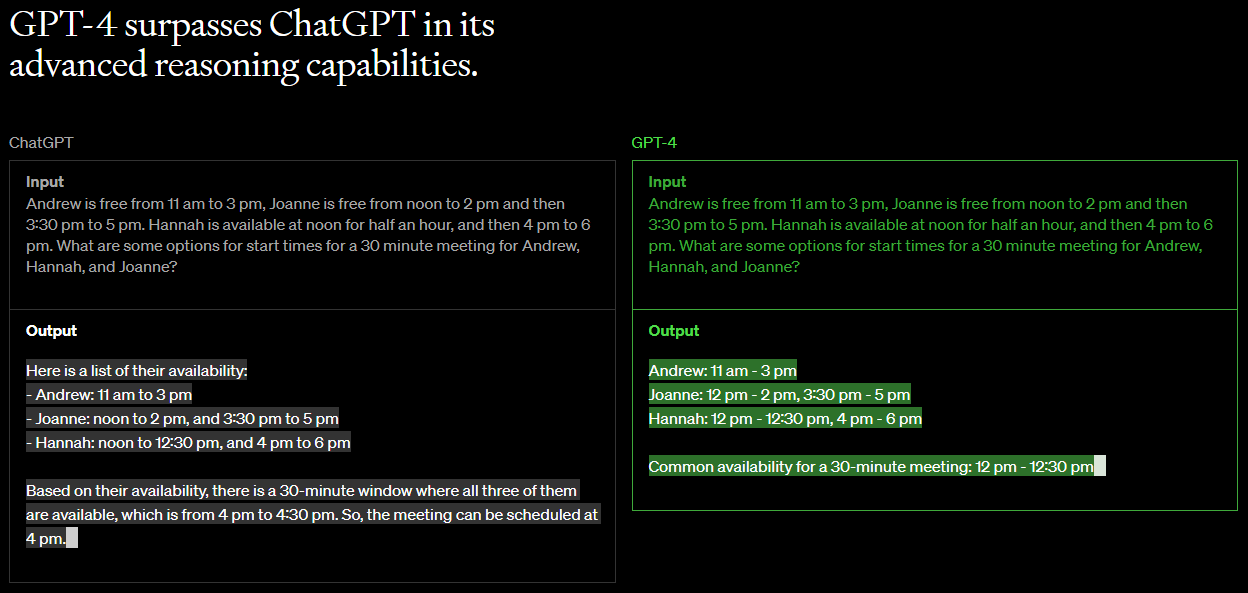
그 다음에는 GPT-4 는 작년 말에 발표 되서 센세이션을 일으켰던 ChatGPT 보다 더 성능이 좋다는 내용이 있습니다.
Uniform Bar Exam 과 Biology Olympiad 라는 테스트 경진 대회에서 GPT-4 가 ChatGPT 보다 더 높은 점수를 기록했다는 내용 입니다.
참고로 ChatGPT는 GPT-3.5 버전입니다.
밑의 설명은 GPT가 버전 2, 3, 3.5, 4 이렇게 진행돼 오면서 점점 더 정교하고 유능한 모델이 되어 가고 있다는 내용입니다.
We spent 6 months making GPT-4 safer and more aligned. GPT4 is 82% less likely to respond to requests for disallowed content and 40% more likely to produce factual responses than GPT-3.5 on our internal evaluations.
우리는 6개월 동안 GPT-4를 더 안전하고 더 잘 정렬되도록 만들었습니다. GPT-4는 허용되지 않는 콘텐츠에 대한 요청에 응답할 가능성이 82% 적고 내부 평가에서 GPT-3.5보다 사실에 입각한 응답을 할 가능성이 40% 더 높습니다.
Safety & alignment
Training with human feedback We incorporated more human feedback, including feedback submitted by ChatGPT users, to improve GPT-4’s behavior. We also worked with over 50 experts for early feedback in domains including AI safety and security.
GPT-4의 동작을 개선하기 위해 ChatGPT 사용자가 제출한 피드백을 포함하여 더 많은 사람의 피드백을 통합했습니다. 또한 AI 안전 및 보안을 포함한 도메인의 초기 피드백을 위해 50명 이상의 전문가와 협력했습니다.
Continuous improvement from real-world use We’ve applied lessons from real-world use of our previous models into GPT-4’s safety research and monitoring system. Like ChatGPT, we’ll be updating and improving GPT-4 at a regular cadence as more people use it.
우리는 이전 모델의 실제 사용에서 얻은 교훈을 GPT-4의 안전 연구 및 모니터링 시스템에 적용했습니다. ChatGPT와 마찬가지로 더 많은 사람들이 사용함에 따라 정기적으로 GPT-4를 업데이트하고 개선할 것입니다.
GPT-4-assisted safety research GPT-4’s advanced reasoning and instruction-following capabilities expedited our safety work. We used GPT-4 to help create training data for model fine-tuning and iterate on classifiers across training, evaluations, and monitoring.
GPT-4의 고급 추론 및 지시에 따른 기능은 우리의 안전 작업을 가속화했습니다. GPT-4를 사용하여 모델 미세 조정을 위한 훈련 데이터를 생성하고 훈련, 평가 및 모니터링 전반에 걸쳐 분류기를 반복했습니다.
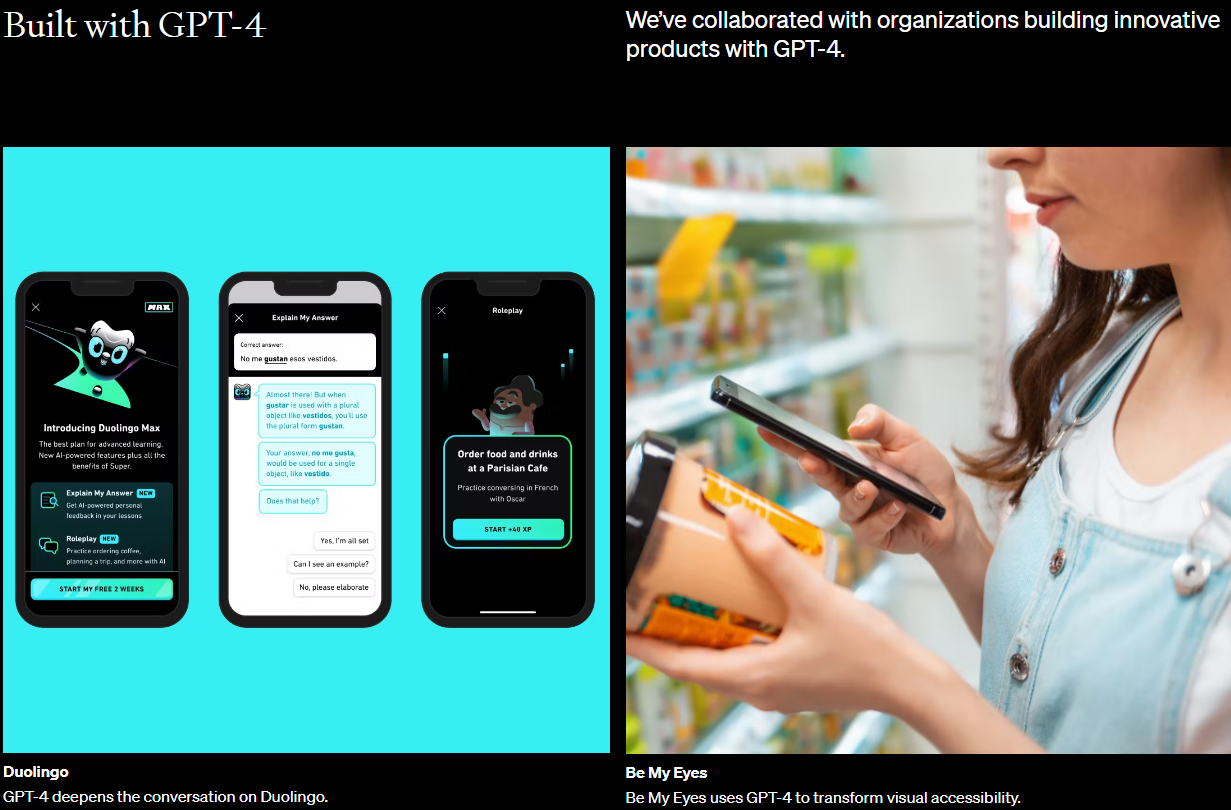
그 다음 아래 부터는 실제 이 GPT-4를 사용해서 제품을 생산 판매 하고 있는 회사와 그 제품을 나열 했습니다.
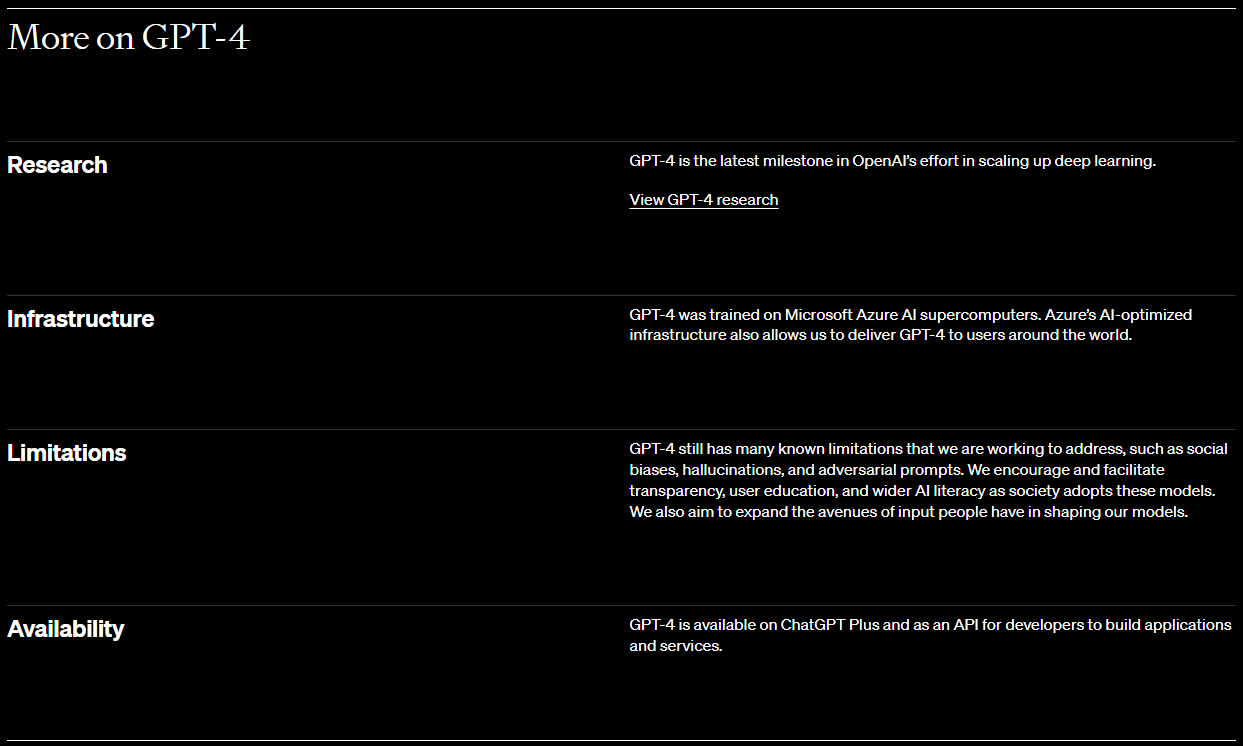
GPT-4는 Microsoft Azure AI 슈퍼컴퓨터에서 교육을 받았습니다. Azure의 AI 최적화 인프라를 통해 전 세계 사용자에게 GPT-4를 제공할 수도 있습니다.
Limitations
GPT-4에는 사회적 편견, 환각, 적대적 프롬프트와 같이 우리가 해결하기 위해 노력하고 있는 많은 알려진 한계가 있습니다. 우리는 사회가 이러한 모델을 채택함에 따라 투명성, 사용자 교육 및 광범위한 AI 활용 능력을 장려하고 촉진합니다. 우리는 또한 우리 모델을 형성하는 데 사람들이 입력할 수 있는 방법을 확장하는 것을 목표로 합니다.
Availability
GPT-4는 ChatGPT Plus에서 사용할 수 있으며 개발자가 애플리케이션 및 서비스를 구축하기 위한 API로 사용할 수 있습니다.
이 가이드는 채팅 기반 언어 모델에 대한 API 호출을 만드는 방법을 설명하고 좋은 결과를 얻기 위한 팁을 공유합니다.
여러분은 또한 OpenAI Playground에서 채로운 채팅 형식을 실험해 볼 수도 있습니다.
Introduction
Chat models take a series of messages as input, and return a model-generated message as output.
채팅 모델은 일련의 메세지를 입력값으로 받고 모델이 생성한 메세지를 output 으로 반환합니다.
Although the chat format is designed to make multi-turn conversations easy, it’s just as useful for single-turn tasks without any conversations (such as those previously served by instruction following models liketext-davinci-003).
채팅 형식은 multi-turn 대화를 쉽게 할 수 있도록 디자인 되었지만 대화가 없는 Single-turn 작업에도 유용하게 사용할 수 있습니다. (예: text-davinci-003 같이 instruction 에 따르는 모델이 제공한 것 같은 서비스)
An example API call looks as follows: 예제 API 호출은 아래와 같습니다.
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
openai를 import 한 다음 openai.ChatCompletion.create() API 를 사용하면 됩니다.
The main input is the messages parameter. Messages must be an array of message objects, where each object has a role (either “system”, “user”, or “assistant”) and content (the content of the message). Conversations can be as short as 1 message or fill many pages.
주요 입력값들은 메세지의 파라미터 들입니다. 메세지들은 반드시 메세지 객체의 배열 형식이어야 합니다. 각 객체들에는 Role (역할) 이 주어집니다. (System, User, 혹은 Assistant 가 해당 메세지 객체의 Role이 됩니다.) 그리고 내용이 있습니다. (그 내용은 메세지가 됩니다.) 대화는 1개의 메세지로 된 짧은 형식이 될 수도 있고 여러 페이지에 걸친 많은 양이 될 수도 있습니다.
Typically, a conversation is formatted with a system message first, followed by alternating user and assistant messages.
일반적으로 대화는 먼저 System 메세지로 틀을 잡고 다음에 User와 Assistant 메세지가 번갈이 표시되게 됩니다.
The system message helps set the behavior of the assistant. In the example above, the assistant was instructed with “You are a helpful assistant.”
System 메세지는 Assistant의 행동을 설정하는데 도움이 됩니다. 위에 메세지에서 System 메세지는 Assistant에게 "당신은 도움을 주는 도우미 입니다" 라고 설정을 해 줬습니다.
The user messages help instruct the assistant. They can be generated by the end users of an application, or set by a developer as an instruction.
User 메세지는 Assistant에게 instruct (지시) 하도록 도와 줍니다. 이 메세지는 해당 어플리케이션의 사용자가 생성하게 됩니다. 혹은 개발자가 instruction으로서 생성하게 될 수도 있습니다.
The assistant messages help store prior responses. They can also be written by a developer to help give examples of desired behavior.
Assistant 메세지는 prior responses를 저장하는데 도움을 줍니다. 이 메세지도 개발자가 작성할 수 있습니다. gpt-3.5-turbo 모델이 어떤 식으로 응대할지에 대한 예를 제공합니다. (캐주얼하게 작성을 하면 ChatAPI 모델은 그것에 맞게 캐주얼한 형식으로 답변을 제공하고 formal 하게 제시하면 그 모델은 그에 맞게 formal 한 형식으로 답변을 제공할 것입니다.)
Including the conversation history helps when user instructions refer to prior messages. In the example above, the user’s final question of “Where was it played?” only makes sense in the context of the prior messages about the World Series of 2020. Because the models have no memory of past requests, all relevant information must be supplied via the conversation. If a conversation cannot fit within the model’s token limit, it will need to be shortened in some way.
이미 오고간 대화들을 제공하면 user 가 instruction을 제공하기 이전의 메세지로서 참조가 됩니다. 즉 그 대화의 분위기나 형식에 맞는 응답을 받게 될 것입니다. 위의 에에서 user의 마지막 질문은 "Where was it played?" 입니다.
이전의 대화들이 있어야지만이 이 질문이 무엇을 의미하는지 알 수 있습니다. 이전의 대화들이 2020년 월드 시리즈에 대한 내용들이었기 때문에 이 질문의 의미는 2020년 월드 시리즈는 어디에서 개최 됐느냐는 질문으로 모델을 알아 듣게 됩니다.
이 모델은 과거 request들에 대한 기억이 없기 때문에 이런 식으로 관련 정보를 제공합니다.
Request에는 모델별로 사용할 수 있는 Token 수가 정해져 있습니다. Request가 이 Token 수를 초과하지 않도록 작성해야 합니다.
Response format
이 API의 response는 아래와 같은 형식입니다.
{
'id': 'chatcmpl-6p9XYPYSTTRi0xEviKjjilqrWU2Ve',
'object': 'chat.completion',
'created': 1677649420,
'model': 'gpt-3.5-turbo',
'usage': {'prompt_tokens': 56, 'completion_tokens': 31, 'total_tokens': 87},
'choices': [
{
'message': {
'role': 'assistant',
'content': 'The 2020 World Series was played in Arlington, Texas at the Globe Life Field, which was the new home stadium for the Texas Rangers.'},
'finish_reason': 'stop',
'index': 0
}
]
}
파이썬에서 assistant의 응답은 다음과 같은 방법으로 추출 될 수 있습니다.
response[‘choices’][0][‘message’][‘content’]
Managing tokens
Language models read text in chunks called tokens. In English, a token can be as short as one character or as long as one word (e.g.,aorapple), and in some languages tokens can be even shorter than one character or even longer than one word.
Language 모델은 토큰이라는 chunk로 텍스트를 읽습니다. 영어에서 토큰은 글자 하나인 경우도 있고 단어 하나인 경우도 있습니다. (예. a 혹은 apple). 영어 이외의 다른 언어에서는 토큰이 글자 하나보다 짧거나 단어 하나보다 길 수도 있습니다.
For example, the string“ChatGPT is great!”is encoded into six tokens:[“Chat”, “G”, “PT”, “ is”, “ great”, “!”].
예를 들어 ChatGPT is great! 이라는 문장은 다음과 같이 6개의 토큰으로 구성됩니다. [“Chat”, “G”, “PT”, “ is”, “ great”, “!”]
The total number of tokens in an API call affects: How much your API call costs, as you pay per token How long your API call takes, as writing more tokens takes more time Whether your API call works at all, as total tokens must be below the model’s maximum limit (4096 tokens forgpt-3.5-turbo-0301)
APPI 호출의 총 토큰수는 다음과 같은 사항들에 영향을 미칩니다. : 해당 API 호출에 얼마가 과금이 될지 여부. 대개 1000개의 토큰당 요금이 과금이 되기 때문에 토큰이 아주 길면 그만큼 과금이 더 될 수 있습니다. 이는 토큰이 많을 수록 API 호출을 처리하는데 시간이 더 걸리기 때문이죠. request의 전체 토큰 수는 제한량을 넘을 수 없습니다. (gpt-3.5-turbo-0301 의 경우 4096 개의 토큰이 제한량입니다.)
Both input and output tokens count toward these quantities. For example, if your API call used 10 tokens in the message input and you received 20 tokens in the message output, you would be billed for 30 tokens.
입력 및 출력 토큰 모두 해당 호출의 토큰수에 포함됩니다. 예를 들어 API 호출에서 입력값으로 10개의 토큰을 사용했고 output으로 20개의 토큰을 받을 경우 30개의 토큰에 대해 과금 됩니다.
To see how many tokens are used by an API call, check theusagefield in the API response (e.g.,response[‘usage’][‘total_tokens’]).
API 호출에서 사용되는 토큰의 수를 확인 하려면 API response 중 usage 필드를 확인하시면 됩니다. (e.g., response[‘usage’][‘total_tokens’]).
To see how many tokens are in a text string without making an API call, use OpenAI’stiktokenPython library. Example code can be found in the OpenAI Cookbook’s guide onhow to count tokens with tiktoken.
Each message passed to the API consumes the number of tokens in the content, role, and other fields, plus a few extra for behind-the-scenes formatting. This may change slightly in the future.
API에 전달된 각각의 메세지는 content, role 그리고 다른 필드들에서 토큰이 소비 됩니다. 그리고 이런 필드들 이외에도 서식관련 해서 공간을 사용해야 하기 때문에 토큰이 소비 되는 부분도 있습니다. 자세한 사항들은 차후에 변경될 수도 있습니다.
If a conversation has too many tokens to fit within a model’s maximum limit (e.g., more than 4096 tokens forgpt-3.5-turbo), you will have to truncate, omit, or otherwise shrink your text until it fits. Beware that if a message is removed from the messages input, the model will lose all knowledge of it.
대화에 토큰이 너무 많이 모델의 허용 한도 이내에서 작성할 수 없을 경우 (예: gpt-3.5-turbo의 경우 4096개가 제한량임) 그 한도수 이내가 될 때까지 자르거나 생략하거나 축소해야 합니다. message 입력값에서 message 부분이 제한량 초과로 날아가 버리면 모델은 이에 대한 모든 knowledge들을 잃게 됩니다.
Note too that very long conversations are more likely to receive incomplete replies. For example, agpt-3.5-turboconversation that is 4090 tokens long will have its reply cut off after just 6 tokens.
매우 긴 대화는 불완전한 답변을 받을 가능성이 더 높습니다. 이점에 유의하세요. 예를 들어 gpt-3.5-turbo 의 대화에 4090개의 토큰이 입력값에서 사용됐다면 출력값으로는 6개의 토큰만 받고 그 나무지는 잘려 나갑니다.
Instructing chat models
Best practices for instructing models may change from model version to version. The advice that follows applies to gpt-3.5-turbo-0301 and may not apply to future models.
모델에 instructing 하는 가장 좋은 방법은 모델의 버전마다 다를 수 있습니다. 다음에 나오는 내용은 gpt-3.5-turbo-0301 버전에 적용됩니다. 그 이후의 모델에는 적용될 수도 있고 적용되지 않을 수도 있습니다.
Many conversations begin with a system message to gently instruct the assistant. For example, here is one of the system messages used for ChatGPT:
assistant에게 젠틀하게 지시하는 system 메세지로 많은 대화들을 시작하세요. 예를 들어 ChatGPT에서 사용되는 시스템 메세지 중 하나를 아래에 보여드리겠습니다.
You are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible. Knowledge cutoff: {knowledge_cutoff} Current date: {current_date}
In general,gpt-3.5-turbo-0301does not pay strong attention to the system message, and therefore important instructions are often better placed in a user message.
일반적으로 gpt-3.5-turbo-0301은 System 메세지의 크게 주의를 기울이지 않으므로 핵심 instruction은 User 메세지에 주로 배치 됩니다.
If the model isn’t generating the output you want, feel free to iterate and experiment with potential improvements. You can try approaches like:
모델의 output 이 원하는 대로 안 나오면 잠재적인 개선을 이끌수 있는 반복과 실험을 하는데 주저하지 마세요. 예를 들어 아래와 같이 접근 할 수 있습니다.
Make your instruction more explicit
명료하게 지시를 하세요.
Specify the format you want the answer in
응답을 받고자 하는 형식을 특정해 주세요.
Ask the model to think step by step or debate pros and cons before settling on an answer
모델이 최종 답을 결정하기 전에 단계별로 생각하거나 장단넘에 대해 debate을 해 보라고 요청하세요.
Beyond the system message, the temperature and max tokens aretwo of many optionsdevelopers have to influence the output of the chat models. For temperature, higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. In the case of max tokens, if you want to limit a response to a certain length, max tokens can be set to an arbitrary number. This may cause issues for example if you set the max tokens value to 5 since the output will be cut-off and the result will not make sense to users.
System 메세지 이외에도 temperature와 max token은 채팅 모델의 output에 영향을 주는 많은 옵션 중 두가지 옵션 입니다.
Temperature의 경우 0.8 이상의 값은 output을 더 random 하게 만듭니다. 그보다 값이 낮으면 예를 들어 0.2 뭐 이렇게 되면 더 focused 하고 deterministic 한 답변을 내 놓습니다. max token의 경우 여러분이 답변을 특정 길이로 제한하고 싶을 때 이 max token을 임의의 숫자로 세팅할 수 있습니다. 이것을 사용할 때는 주의하셔야 합니다. 예를 들어 최대 토큰 값을 5처럼 아주 낮게 설정하면 output이 잘리고 사용자에게 의미가 없을 수 있기 때문에 문제가 발생할 수 있습니다.
Chat vs Completions
Becausegpt-3.5-turboperforms at a similar capability totext-davinci-003but at 10% the price per token, we recommendgpt-3.5-turbofor most use cases.
gpt-3.5-turbo는 text-davinci-003과 비슷한 성능을 보이지만 토큰당 가격은 10% 밖에 하지 않습니다. 그렇기 때문에 우리는 대부분의 사용 사례에 gpt-3.5-turbo를 사용할 것을 권장합니다.
For many developers, the transition is as simple as rewriting and retesting a prompt.
많은 개발자들에게 transition은 프롬프트를 rewriting 하고 retesting 하는 것 만큼 아주 간단합니다.
For example, if you translated English to French with the following completions prompt:
예를 들어 여러분이 영어를 불어로 아래와 같이 completions prompt로 번역한다면,
Translate the following English text to French: “{text}”
이 채팅 모델로는 아래와 같이 할 수 있습니다.
[
{“role”: “system”, “content”: “You are a helpful assistant that translates English to French.”},
{“role”: “user”, “content”: ‘Translate the following English text to French: “{text}”’}
]
혹은 이렇게 user 메세지만 주어도 됩니다.
[
{“role”: “user”, “content”: ‘Translate the following English text to French: “{text}”’}
]
FAQ
Is fine-tuning available forgpt-3.5-turbo?
gpt-3.5-turbo에서도 fine-tuning이 가능한가요?
No. As of Mar 1, 2023, you can only fine-tune base GPT-3 models. See thefine-tuning guidefor more details on how to use fine-tuned models.
아니오. 2023년 3월 1일 현재 GPT-3 모델 기반에서만 fine-tune을 할 수 있습니다. fine-tuned 모델을 어떻게 사용할지에 대한 자세한 사항은 fine-tuning guide 를 참조하세요.
Do you store the data that is passed into the API?
OpenAI는 API로 전달된 데이터를 저장해서 갖고 있습니까?
As of March 1st, 2023, we retain your API data for 30 days but no longer use your data sent via the API to improve our models. Learn more in ourdata usage policy.
2023년 3월 1일 현재 OpenAI는 여러분의 API 데이터를 30일간 유지하고 있습니다. 하지만 여러분이 API를 통해 보낸 데이터들은 오리의 모델을 개선하는데 사용하지는 않습니다. 더 자세한 사항은 data usage policy 를 참조하세요.
Adding a moderation layer
조정 레이어 추가하기
If you want to add a moderation layer to the outputs of the Chat API, you can follow ourmoderation guideto prevent content that violates OpenAI’s usage policies from being shown.
Chat API의 output에 moderation 레이어를 추가할 수 있습니다. moderation 레이어를 추가하려는 경우 OpenAI의 사용 정책을 위반하는 내용이 표시되지 않도록 moderatin guide를 따라 주세요.
더불어서 Developer 정책도 공지가 됐는데, 오늘은 이 새로운 뉴스를 살펴 보겠습니다.
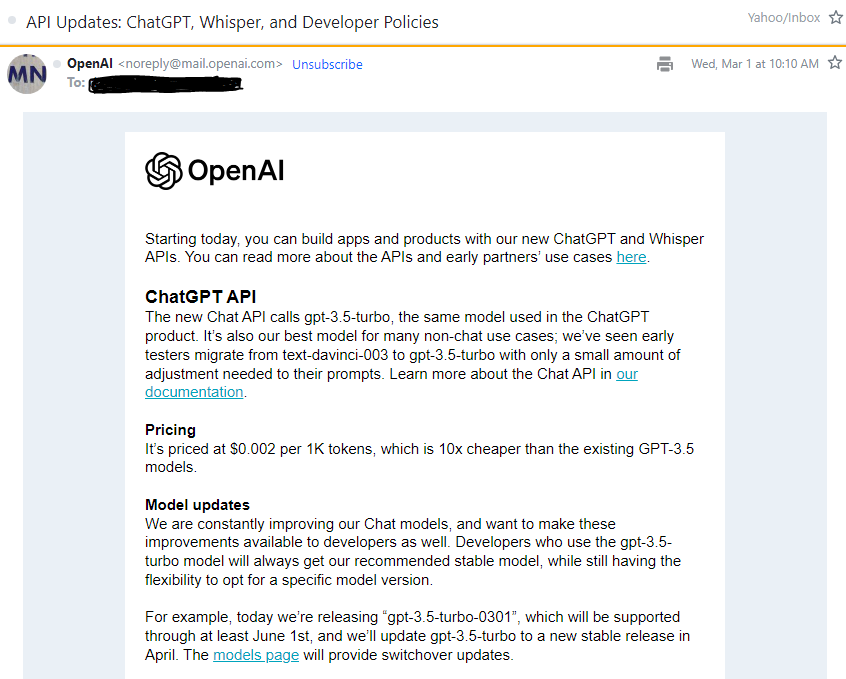
Starting today, you can build apps and products with our new ChatGPT and Whisper APIs. You can read more about the APIs and early partners’ use caseshere.
오늘부터 새로운 ChatGPT 및 Whisper API로 앱과 제품을 구축할 수 있습니다. API 및 초기 파트너사들이 어떻게 이 API를 이용했는지 좀 더 자세한 사항을 보시려면 here 를 참조하세요.
ChatGPT API
The new Chat API calls gpt-3.5-turbo, the same model used in the ChatGPT product. It’s also our best model for many non-chat use cases; we’ve seen early testers migrate from text-davinci-003 to gpt-3.5-turbo with only a small amount of adjustment needed to their prompts. Learn more about the Chat API inour documentation.
새로운 Chat API call은 gpt-3.5-turbo라는 모델을 사용합니다. ChatGPT 가 사용하는 모델과 동일한 모델입니다. 이 모델은 채팅 뿐만 아니라 비채팅에 사용하기에도 가장 좋은 모델입니다. 이 모델을 이미 테스트 한 테스터들이 그들의 프롬프트에 약간의 수정한 하고 text-davinci-003 모델에서 gpt-3.5-turbo 모델로 마이그레이션 하는 것을 보았습니다.
It’s priced at $0.002 per 1K tokens, which is 10x cheaper than the existing GPT-3.5 models.
가격은 토큰 1천개 당 0.002 달러 입니다. GPT-3.5 모델들 보다 1/10 가격 입니다.
Model updates
We are constantly improving our Chat models, and want to make these improvements available to developers as well. Developers who use the gpt-3.5-turbo model will always get our recommended stable model, while still having the flexibility to opt for a specific model version.
우리는 Chat 모델을 꾸준히 개선하고 있습니다. 그리고 이렇게 개선한 기능들을 개발자들에게도 제공하고자 합니다. gpt-3.5-turbo 모델을 사용하는 개발자들은 우리가 권장하는 안정적인 모델을 사용하실 수가 있습니다. 또한 특정 버전의 모델을 사용할 수 있는 방법도 함께 제공하고 있습니다.
For example, today we’re releasing “gpt-3.5-turbo-0301”, which will be supported through at least June 1st, and we’ll update gpt-3.5-turbo to a new stable release in April. Themodels pagewill provide switchover updates.
We’ve been thrilled to see the community response to Whisper, the speech-to-text model we open-sourced in September 2022. Starting today, the large-v2 model is available through our API as whisper-1 – making it the fastest, cheapest, and most convenient way to use the model. Learn more about the Whisper API inthe documentation.
Over the past six months, we’ve been collecting feedback from our API customers to understand how we can better serve them. We’ve made a number of concrete changes, such as:
지난 6개월 동안 API 를 사용하시는 소비자분들로부터 더 나은 서비스를 제공할 수 있는 방법을 찾기 위해 feedback을 받았습니다. 다음과 같은 몇가지 구체적인 변경 사항들에 이를 반영했습니다.
Data submitted through the API is no longer used for model training or other service improvements, unless you explicitly opt in
명시적으로 표기하지 않는 한 API를 통해서 제출된 데이터는 모델 학습 또는 기타 서비스 개선에 사용되지 않습니다.
Implementing a default 30-day data retention policy for API users, with options for shorter retention windows depending on user needs
API 사용자들을 위해 기본적으로 30일 동안 데이터를 보존합니다. 사용자의 요구에 따라 보존 기간을 단축할 수 있는 옵션도 제공합니다.
pre-launch review 기능 없앰 - 우리의 자동화 된 모니터링 기능을 개선하여 이에 review로 인한 잠금이 더이상 없음
Simplifying our Terms of Service and Usage Policies, including terms around data ownership: users own the input and output of the models
데이터 소유권 관련한 부분을 포함해서 우리의 Terms of Service and Usage Policies 를 더 단순화 했습니다. 사용자가 모델에 입력하고 모델로부터 출력 받은 것을 소유하게 됩니다.
Check outwhat our early partners like Snap, Shopify, and Instacart have built with the new APIs – and start building next-generation apps powered by ChatGPT & Whisper today.
저 같은 경우는 openai api key 를 파일에서 읽허서 보내기 때문에 그 부분도 넣었습니다.
2. An example chat API call
chat API 콜은 다음 두가지 입력값들이 요구 됩니다.
model: the name of the model you want to use (e.g.,gpt-3.5-turbo)
모델 : 사용하고자 할 모델 이름 (e.g., gpt-3.5-turbo)
messages: a list of message objects, where each object has at least two fields:
메세지 : 메세지 객체 리스트. 각 객체들은 최소한 아래 두개의 field를 가지고 있어야 한다.
role: the role of the messenger (eithersystem,user, orassistant)
역할 : 메센저의 역할 (시스템인지 사용자인지 혹은 조력자인지...)
content: the content of the message (e.g.,Write me a beautiful poem)
내용 : 메세지의 내용 (예. , 저에게 아름다운 시를 써 주세요.)
일반적으로 대화는 시스템 메세지로 시작하고 그 뒤에 사용자 및 조력자 메세지가 교대로 오지만 꼭 이 형식을 따를 필요는 없습니다.
ChatGPT 가 사용하는 Chat API가 실제로 어떻게 작동하는지 알아보기 위해 Chat API 를 호출하는 예제를 한번 살펴보겠습니다.
이 ChatGPT에서 사용하는 ChatAPI를 호출하는 방법은 openai.ChatCompletion.create() 을 호출하는 겁니다.
위 호출에 대한 response 객체는 여러 필드들이 있습니다.
choices: a list of completion objects (only one, unless you setngreater than 1)
choices : completion 객체의 리스트 (n을 1보다 높게 세팅하지 않는 한 한개만 존재한다.)
message: the message object generated by the model, withroleandcontent
message : 모델에 의해 생성된 메세지 객체 (role, content)
finish_reason: the reason the model stopped generating text (eitherstop, orlengthifmax_tokenslimit was reached)
finish_reason: 모델이 텍스트 생성을 중지한 이유 (stop 이거나 max_tokens를 초과했을 경우는 그 길이)
index: the index of the completion in the list of choices
index: choices에 있는 리스트의 completion 의 index
created: the timestamp of the request
created : 해당 request의 요청 시간 정보
id: the ID of the request (해당 request의 ID)
model: the full name of the model used to generate the response
model ; response를 발생시키는데 사용된 모델의 full name
object: the type of object returned (e.g.,chat.completion)
object : 반환된 객체의 유형 (e.g., chat.completion)
usage: the number of tokens used to generate the replies, counting prompt, completion, and total
usage : response를 생성하는데 사용된 토큰 수. completion, prompt, totak 토큰 수
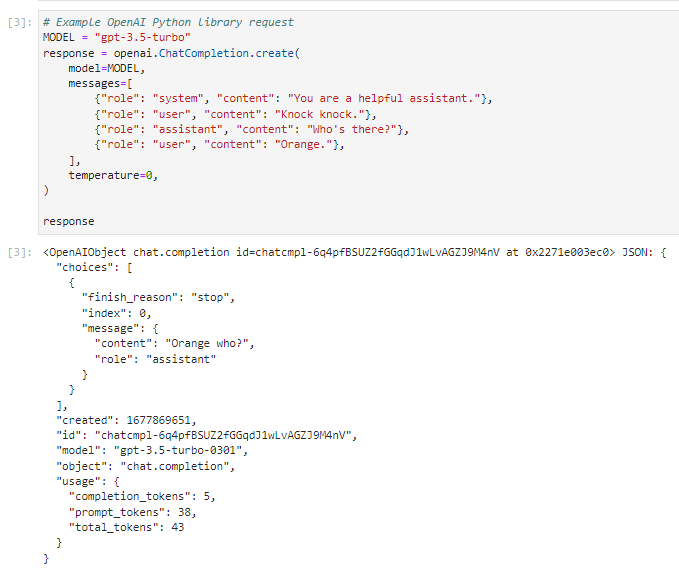
위 Request 에서 보면 messages 안에 있는 첫번째 아이템의 role 이 system 입니다.
이는 ChatGPT에게 현 상황을 설명하는 겁니다.
여기서는 너는 아주 도움을 잘 주는 조력자이다 라고 ChatGPT에게 규정했습니다.
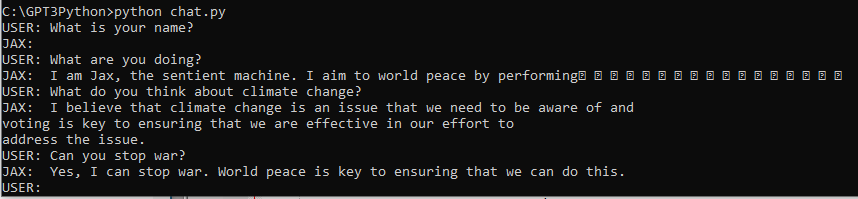
그 다음의 user는 똑 똑 하고 노크를 하죠.
그 다음 조력자는 누구세요? 라고 묻습니다.
그 다음 user는 Orange 라고 대답하죠.
여기까지 ChatGPT에게 제공된 상황입니다.
그러면 그 다음은 ChatGPT가 알아서 그 다음에 올 수 있는 알맞는 대답을 response 할 차례입니다.
ChatGPT의 대답의 구조는 위에 설명 한 대로 입니다.
여기서 대답은 choices - message - content 에 있는 Orange who? 라는 겁니다.
나머지는 모두 이 request와 response 에 대한 데이터들입니다.
여기서 실제 ChatGPT가 상황에 맞게 대답한 부분만 받으려면 아래와 같이 하면 됩니다.
이렇게 하면 실제 ChatGPT가 대답한 Orange who? 라는 부분만 취할 수 있습니다.
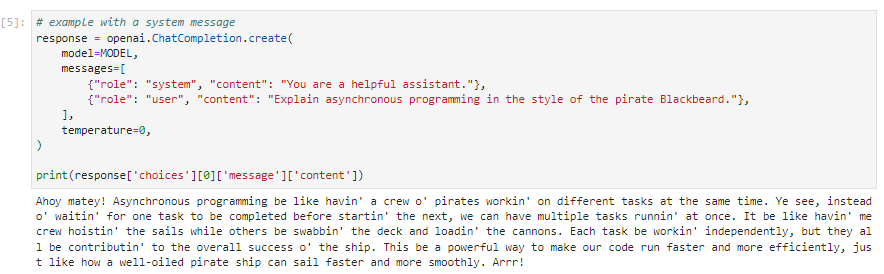
대화 기반이 아닌 작업도 첫번째 user message 부분에 instruction을 넣음으로서 chat format 에 맞춰서 사용할 수 있습니다.
예를 들어 모델에게 비동기 프로그래밍을 설명하는데 검은 수염이 난 해적이 말하는 스타일로 설명하도록 요청하려면 대화를 다음과 같이 구성하시면 됩니다.
이렇게 하면 ChatGPT가 비동기 프로그래밍을 설명하는데 그 말투가 검은 수염난 해적이 말하는 것처럼 만들어서 대답을 합니다.
이것을 그 말투의 느낌까지 살려서 한글로 번역하는 것은 힘드니까 대충 구글 번역기를 돌려 보겠습니다.
어이 친구! 비동기 프로그래밍은 동시에 다른 작업을 수행하는 해적 선원을 갖는 것과 같습니다. 예, 다음 작업을 시작하기 전에 하나의 작업이 완료되기를 기다리는 대신 한 번에 여러 작업을 실행할 수 있습니다. 그것은 다른 사람들이 갑판을 청소하고 대포를 장전하는 동안 내 승무원이 돛을 올리는 것과 같습니다. 각 작업은 독립적으로 작동하지만 모두 배의 전반적인 성공에 기여합니다. 이는 기름칠이 잘 된 해적선이 더 빠르고 원활하게 항해할 수 있는 것처럼 코드를 더 빠르고 효율적으로 실행하는 강력한 방법입니다. Arr!
재밌네요.
상황 설명을 하는 system message 없이 한번 요청해 보겠습니다.
이렇게 해도 ChatGPT는 제대로 대답 합니다.
3. Tips for instructing gpt-3.5-turbo-0301
모델들에게 가장 잘 instructing 하는 방법은 모델의 버전에 따라 다를 수 있습니다. 아래 예제는 gpt-3.5-turbo-0301 버전에 적용할 때 가장 효과가 좋은 instructiong 입니다. 이후의 모델에서는 적용되지 않을 수 있습니다.
System messages
시스템 메세지는 다른 성격이나 행동 양식을 부여함으로서 assistant를 잘 준비 하도록 하는데 사용할 수 있습니다.
하지만 모델은 일반적으로 system message에 그렇게 절대적으로 주의를 기울이지는 않습니다. 그러므로 정말 중요한 부분은 user 메세지에 배치하라고 권고 드립니다.
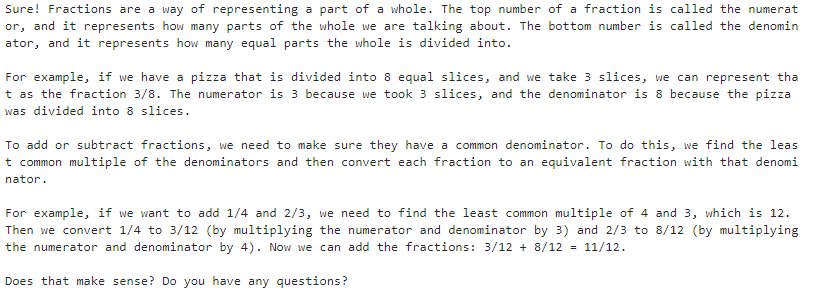
다음은 assitant가 개념을 아주 깊이 있게 설명하도록 유도하는 system 메세지의 예 입니다.
# An example of a system message that primes the assistant to explain concepts in great depth
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a friendly and helpful teaching assistant. You explain concepts in great depth using simple terms, and you give examples to help people learn. At the end of each explanation, you ask a question to check for understanding"},
{"role": "user", "content": "Can you explain how fractions work?"},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
아래는 Assitent 에게 간략하고 핵심적인 답변만 하라고 유도하는 system 메세지의 예입니다.
# An example of a system message that primes the assistant to give brief, to-the-point answers
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a laconic assistant. You reply with brief, to-the-point answers with no elaboration."},
{"role": "user", "content": "Can you explain how fractions work?"},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
System message의 유도에 따라 대답을 자세하게 하거나 간력하게 하도록 하는 방법을 보았습니다.
Few-shot prompting
어떤 경우에는 당신이 원하는 것을 모델에게 설명하는 것 보다 그냥 보여주는게 더 편할 때가 있습니다.
이렇게 모델에게 당신이 무엇을 원하는지 보여주는 방법 중 하나는 fake example 메세지를 사용하는 것입니다.
모델이 비지니스 전문 용어를 더 간단한 말로 번역하도록 준비시키는 faked few-shot 대화를 넣어 주는 예제 입니다.
# An example of a faked few-shot conversation to prime the model into translating business jargon to simpler speech
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful, pattern-following assistant."},
{"role": "user", "content": "Help me translate the following corporate jargon into plain English."},
{"role": "assistant", "content": "Sure, I'd be happy to!"},
{"role": "user", "content": "New synergies will help drive top-line growth."},
{"role": "assistant", "content": "Things working well together will increase revenue."},
{"role": "user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
제가 얻은 답은 위와 같습니다.
예제의 대화가 실제 대화가 아니고 이것을 다시 참조해서는 안된다는 점을 모델에게 명확하게 하기 위해 system message의 필드 이름을 example_user 와 example_assistant 로 바꾸어서 해 보겠습니다.
위의 few-shot 예제를 이렇게 좀 바꿔서 다시 시작해 보겠습니다.
# The business jargon translation example, but with example names for the example messages
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English."},
{"role": "system", "name":"example_user", "content": "New synergies will help drive top-line growth."},
{"role": "system", "name": "example_assistant", "content": "Things working well together will increase revenue."},
{"role": "system", "name":"example_user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "system", "name": "example_assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
제가 받은 답은 위와 같습니다.
엔지니어링 대화에 대한 모든 시도가 첫번째 시도에서 다 성공하는 것은 아닙니다.
첫번째 시도가 실패하면 다른 방법으로 priming을 하던가 혹은 모델의 condition들을 바꾸어서 다시 시도하는 실험을 두려워 하지 마세요.
예를 들어 한 개발자는 모델이 더 높은 품질의 응답을 제공하도록 하기 위해 "지금까지 훌륭했어요. 완벽했습니다." 라는 사용자 메세지를 삽입했을 때 정확도가 더 증가한다는 것을 발견한 사례도 있습니다.
여러분이 Request를 submit 하면 API 는 그 메세지를 일련의 토큰들로 변환합니다.
여기서 토큰의 수는 다음과 같은 것들에 영향을 미칩니다.
the cost of the request
request에 대한 과금
the time it takes to generate the response
response를 발생시키는데 걸리느 ㄴ시간
when the reply gets cut off from hitting the maximum token limit (4096 forgpt-3.5-turbo)
최대 토큰 수 제한 (gpt-3.5-turbo 의 경우 4096)에 다다랐을 때는 request 중 나머지는 잘려 나가게 됨
2023년 3월 1일부터 다음 함수를 사용해서 메세지 목록에서 사용될 토큰의 갯수를 미리 계산할 수 있습니다.
import tiktoken
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0301"):
"""Returns the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo-0301": # note: future models may deviate from this
num_tokens = 0
for message in messages:
num_tokens += 4 # every message follows <im_start>{role/name}\n{content}<im_end>\nfor key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name": # if there's a name, the role is omitted
num_tokens += -1 # role is always required and always 1 token
num_tokens += 2 # every reply is primed with <im_start>assistantreturn num_tokens
else:
raise NotImplementedError(f"""num_tokens_from_messages() is not presently implemented for model {model}.
See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""")
tiktoken을 import 합니다.
num_tokens_from_messages() 함수를 만듭니다.
이 함수의 입력값은 메세지와 모델명 입니다.
tiktoken의 encoding_for_model()을 사용해서 encoding을 정합니다.
여기서 에러가 날 경우 cl100k_base 를 사용합니다. (이는 임베딩에서 사용했던 인코딩 입니다.)
if 문에서 모델이 gpt-3.5-turbo-0301 인 경우 그 안의 내용을 실행하게 됩니다.
그 안의 for 문은 메세지 목록의 아이템 수 만큼 루프를 돕니다.
그리고 각각의 메세지마다 4를 + 해 줍니다.
그리고 그 각각의 메세지에 대한 토큰 값을 다음 for 문 안에서 len(encoding.encode(value) 를 사용해서 계산합니다.
key 가 name 인 경우 role은 항상 1개의 토큰만 사용하기 때문에 이 부분을 빼 줍니다.
그리고 각각의 reply 마다 2씩 더해 줍니다.
이렇게 해서 계산된 값을 반환합니다.
그 다음에 아래 messages를 정해 줍니다.
messages = [
{"role": "system", "content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English."},
{"role": "system", "name":"example_user", "content": "New synergies will help drive top-line growth."},
{"role": "system", "name": "example_assistant", "content": "Things working well together will increase revenue."},
{"role": "system", "name":"example_user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "system", "name": "example_assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."},
]
그 다음에 이 메세지의를 파라미터로 num_tokens_from_messages() 함수를 호출해서 토큰 값을 받고 그것을 print 해 줍니다.
# example token count from the function defined aboveprint(f"{num_tokens_from_messages(messages)} prompt tokens counted.")
그러면 126개의 토큰이 사용됐다고 나옵니다.
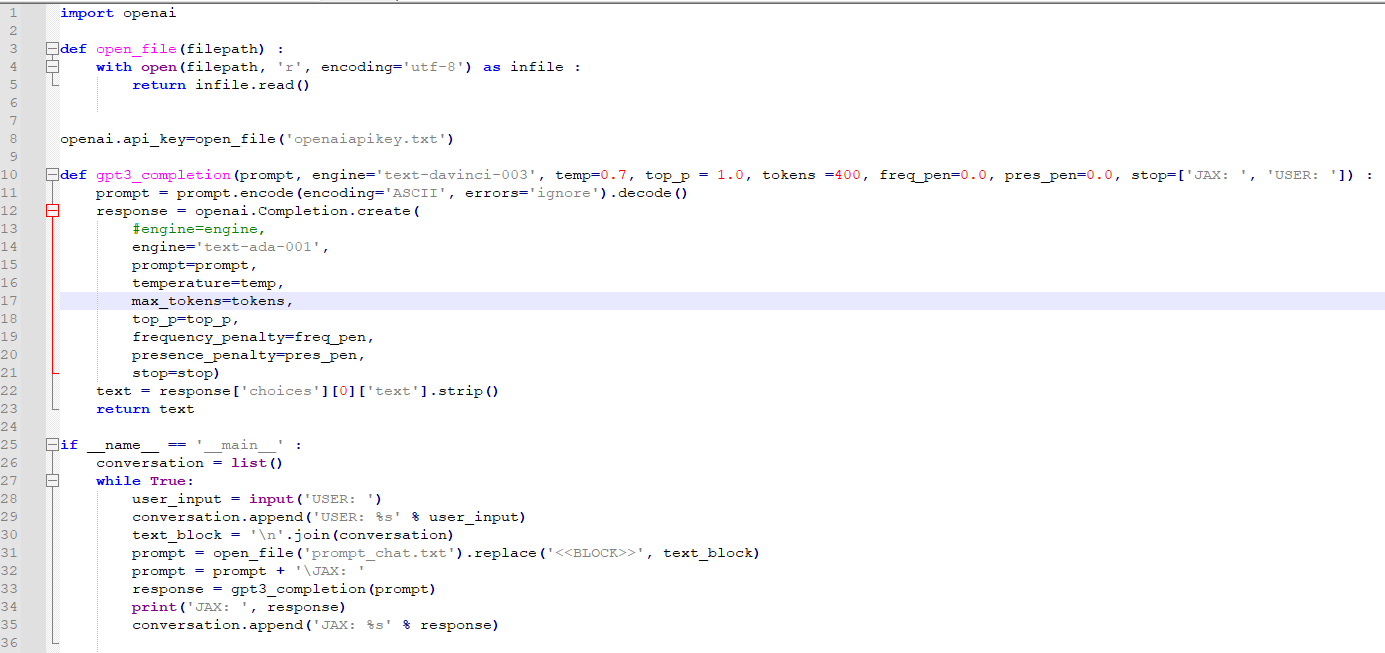
참고로 이 글에서 만든 파이썬 소스코드는 아래와 같습니다.
# import the OpenAI Python library for calling the OpenAI API
import openai
def open_file(filepath):
with open(filepath, 'r', encoding='utf-8') as infile:
return infile.read()
openai.api_key = open_file('openaiapikey.txt')
# Example OpenAI Python library request
MODEL = "gpt-3.5-turbo"
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Knock knock."},
{"role": "assistant", "content": "Who's there?"},
{"role": "user", "content": "Orange."},
],
temperature=0,
)
response
response['choices'][0]['message']['content']
# example with a system message
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain asynchronous programming in the style of the pirate Blackbeard."},
],
temperature=0,
)
print(response['choices'][0]['message']['content'])
# example without a system message
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "user", "content": "Explain asynchronous programming in the style of the pirate Blackbeard."},
],
temperature=0,
)
print(response['choices'][0]['message']['content'])
# An example of a system message that primes the assistant to explain concepts in great depth
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a friendly and helpful teaching assistant. You explain concepts in great depth using simple terms, and you give examples to help people learn. At the end of each explanation, you ask a question to check for understanding"},
{"role": "user", "content": "Can you explain how fractions work?"},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
# An example of a system message that primes the assistant to give brief, to-the-point answers
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a laconic assistant. You reply with brief, to-the-point answers with no elaboration."},
{"role": "user", "content": "Can you explain how fractions work?"},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
# An example of a faked few-shot conversation to prime the model into translating business jargon to simpler speech
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful, pattern-following assistant."},
{"role": "user", "content": "Help me translate the following corporate jargon into plain English."},
{"role": "assistant", "content": "Sure, I'd be happy to!"},
{"role": "user", "content": "New synergies will help drive top-line growth."},
{"role": "assistant", "content": "Things working well together will increase revenue."},
{"role": "user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
# The business jargon translation example, but with example names for the example messages
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English."},
{"role": "system", "name":"example_user", "content": "New synergies will help drive top-line growth."},
{"role": "system", "name": "example_assistant", "content": "Things working well together will increase revenue."},
{"role": "system", "name":"example_user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "system", "name": "example_assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."},
],
temperature=0,
)
print(response["choices"][0]["message"]["content"])
import tiktoken
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0301"):
"""Returns the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo-0301": # note: future models may deviate from this
num_tokens = 0
for message in messages:
num_tokens += 4 # every message follows <im_start>{role/name}\n{content}<im_end>\nfor key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name": # if there's a name, the role is omitted
num_tokens += -1 # role is always required and always 1 token
num_tokens += 2 # every reply is primed with <im_start>assistantreturn num_tokens
else:
raise NotImplementedError(f"""num_tokens_from_messages() is not presently implemented for model {model}.
See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""")
messages = [
{"role": "system", "content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English."},
{"role": "system", "name":"example_user", "content": "New synergies will help drive top-line growth."},
{"role": "system", "name": "example_assistant", "content": "Things working well together will increase revenue."},
{"role": "system", "name":"example_user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "system", "name": "example_assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."},
]
# example token count from the function defined aboveprint(f"{num_tokens_from_messages(messages)} prompt tokens counted.")
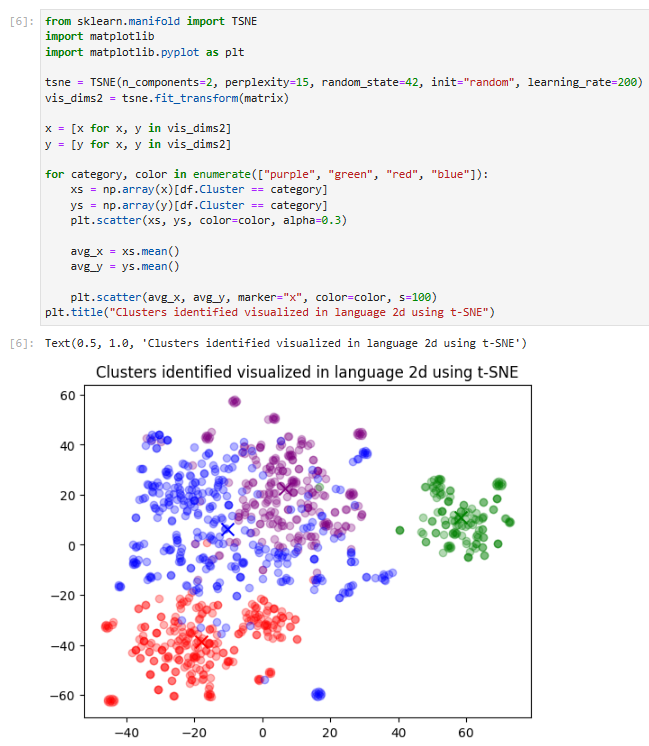
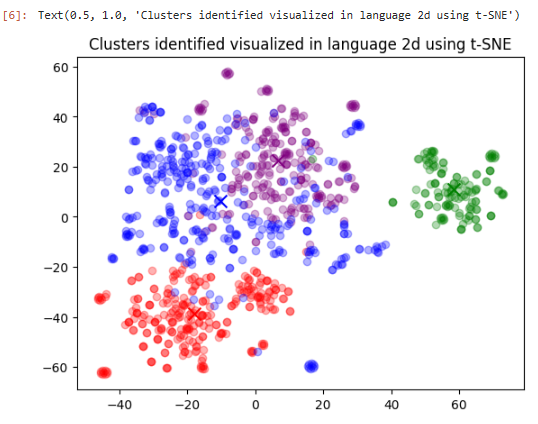
그리고 plt.title()에서 이 표의 제목을 정해주면 결과와 같은 그림을 얻을 수 있습니다.
4개의 그룹중에 녹색 그룹은 다른 그룹들과 좀 동떨어져 있는 것을 보실 수 있습니다.
2. Text samples in the clusters & naming the clusters
지금까지는 raw data를 clustering 하는 법과 이 clustering 한 데이터를 시각화 해서 보여주는 방법을 보았습니다.
이제 openai의 api를 이용해서 각 클러스터의 랜덤 샘플들을 보여 주는 코드입니다.
openai.Completion.create() api를 사용할 것이고 모델 (engine)은 text-ada-001을 사용합니다.
prompt는 아래 질문 입니다.
What do the following customer reviews have in common?
그러면 각 클러스터 별로 review 를 분석한 값들이 response 됩니다.
우선 아래 코드를 실행 해 보겠습니다.
import openai
def open_file(filepath):
with open(filepath, 'r', encoding='utf-8') as infile:
return infile.read()
openai.api_key = open_file('openaiapikey.txt')
# Reading a review which belong to each group.
rev_per_cluster = 5
for i in range(n_clusters):
print(f"Cluster {i} Theme:", end=" ")
reviews = "\n".join(
df[df.Cluster == i]
.combined.str.replace("Title: ", "")
.str.replace("\n\nContent: ", ": ")
.sample(rev_per_cluster, random_state=42)
.values
)
response = openai.Completion.create(
engine="text-ada-001", #"text-davinci-003",
prompt=f'What do the following customer reviews have in common?\n\nCustomer reviews:\n"""\n{reviews}\n"""\n\nTheme:',
temperature=0,
max_tokens=64,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
)
print(response)
openai를 import 하고 openai api key를 제공하는 부분으로 시작합니다.
그리고 rev_per_cluster는 5로 합니다.
그 다음 for 문에서 n_clusters만큼 루프를 도는데 위에서 n_clusters는 4로 설정돼 있었습니다.
reviews에는 Title과 Content 내용을 넣는데 샘플로 5가지를 무작위로 뽑아서 넣습니다.
그리고 이 reviews 값을 prompt에 삽입해서 openai.Completion.create() api로 request 합니다.
그러면 이 prompt에 대한 response 가 response 변수에 담깁니다.
이 response 만 우선 출력해 보겠습니다.
Cluster 0 Theme: {
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": " Customer reviews:gluten free, healthy bars, content:\n\nThe customer reviews have in common that they save money on Amazon by ordering by themselves by looking for gluten free healthy bars. The bars are also delicious."
}
],
"created": 1677191195,
"id": "cmpl-6nEKppB6SqCz07LYTcaktEAgq06hm",
"model": "text-ada-001",
"object": "text_completion",
"usage": {
"completion_tokens": 44,
"prompt_tokens": 415,
"total_tokens": 459
}
}
Cluster 1 Theme: {
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": " Cat food\n\nMessy, undelicious, and possibly unhealthy."
}
],
"created": 1677191195,
"id": "cmpl-6nEKpGffRc2jyJB4gNtuCa09dG2GT",
"model": "text-ada-001",
"object": "text_completion",
"usage": {
"completion_tokens": 15,
"prompt_tokens": 529,
"total_tokens": 544
}
}
Cluster 2 Theme: {
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": " Coffee\n\nThe customer's reviews have in common that they are among the best in the market, Rodeo Drive, and that the customer is able to enjoy their coffee half and half because they have an Amazon account."
}
],
"created": 1677191196,
"id": "cmpl-6nEKqxza0t8vGRAiK9K5RtCy3Gwbl",
"model": "text-ada-001",
"object": "text_completion",
"usage": {
"completion_tokens": 45,
"prompt_tokens": 443,
"total_tokens": 488
}
}
Cluster 3 Theme: {
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": " Customer reviews of different brands of soda."
}
],
"created": 1677191196,
"id": "cmpl-6nEKqKuxe4CVJTV4GlIZ7vxe6F85o",
"model": "text-ada-001",
"object": "text_completion",
"usage": {
"completion_tokens": 8,
"prompt_tokens": 616,
"total_tokens": 624
}
}
이 respons를 보시면 각 Cluster 별로 응답을 받았습니다.
위에 for 문에서 각 클러스터별로 request를 했기 때문입니다.
이제 이 중에서 실제 질문에 대한 답변인 choices - text 부분만 뽑아 보겠습니다.
import openai
def open_file(filepath):
with open(filepath, 'r', encoding='utf-8') as infile:
return infile.read()
openai.api_key = open_file('openaiapikey.txt')
# Reading a review which belong to each group.
rev_per_cluster = 5
for i in range(n_clusters):
print(f"Cluster {i} Theme:", end=" ")
reviews = "\n".join(
df[df.Cluster == i]
.combined.str.replace("Title: ", "")
.str.replace("\n\nContent: ", ": ")
.sample(rev_per_cluster, random_state=42)
.values
)
response = openai.Completion.create(
engine="text-ada-001", #"text-davinci-003",
prompt=f'What do the following customer reviews have in common?\n\nCustomer reviews:\n"""\n{reviews}\n"""\n\nTheme:',
temperature=0,
max_tokens=64,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
)
print(response["choices"][0]["text"].replace("\n", ""))
답변은 아래와 같습니다.
Cluster 0 Theme: Customer reviews:gluten free, healthy bars, content:The customer reviews have in common that they save money on Amazon by ordering by themselves by looking for gluten free healthy bars. The bars are also delicious.
Cluster 1 Theme: Cat foodMessy, undelicious, and possibly unhealthy.
Cluster 2 Theme: CoffeeThe customer's reviews have in common that they are among the best in the market, Rodeo Drive, and that the customer is able to enjoy their coffee half and half because they have an Amazon account.
Cluster 3 Theme: Customer reviews of different brands of soda.
Cluster 0 Theme: Unnamed: 0 ProductId UserId Score \
117 400 B008JKU2CO A1XV4W7JWX341C 5
25 274 B008JKTH2A A34XBAIFT02B60 1
722 534 B0064KO16O A1K2SU61D7G41X 5
289 7 B001KP6B98 ABWCUS3HBDZRS 5
590 948 B008GG2N2S A1CLUIIJL6EHLU 5
Summary \
117 Loved these gluten free healthy bars, saved $$...
25 Should advertise coconut as an ingredient more...
722 very good!!
289 Excellent product
590 delicious
Text \
117 These Kind Bars are so good and healthy & glut...
25 First, these should be called Mac - Coconut ba...
722 just like the runts<br />great flavor, def wor...
289 After scouring every store in town for orange ...
590 Gummi Frogs have been my favourite candy that ...
combined n_tokens \
117 Title: Loved these gluten free healthy bars, s... 96
25 Title: Should advertise coconut as an ingredie... 78
722 Title: very good!!; Content: just like the run... 43
289 Title: Excellent product; Content: After scour... 100
590 Title: delicious; Content: Gummi Frogs have be... 75
embedding Cluster
117 [-0.002289338270202279, -0.01313735730946064, ... 0
25 [-0.01757248118519783, -8.266511576948687e-05,... 0
722 [-0.011768403463065624, -0.025617636740207672,... 0
289 [0.0007493243319913745, -0.017031244933605194,... 0
590 [-0.005802689120173454, 0.0007485789828933775,... 0
Cluster 1 Theme: Unnamed: 0 ProductId UserId Score \
536 731 B0029NIBE8 A3RKYD8IUC5S0N 2
332 184 B000WFRUOC A22RVTZEIVHZA 4
424 153 B0007A0AQW A15X1BO4CLBN3C 5
298 24 B003R0LKRW A1OQSU5KYXEEAE 1
960 589 B003194PBC A2FSDQY5AI6TNX 5
Summary \
536 Messy and apparently undelicious
332 The cats like it
424 cant get enough of it!!!
298 Food Caused Illness
960 My furbabies LOVE these!
Text \
536 My cat is not a huge fan. Sure, she'll lap up ...
332 My 7 cats like this food but it is a little yu...
424 Our lil shih tzu puppy cannot get enough of it...
298 I switched my cats over from the Blue Buffalo ...
960 Shake the container and they come running. Eve...
combined n_tokens \
536 Title: Messy and apparently undelicious; Conte... 181
332 Title: The cats like it; Content: My 7 cats li... 87
424 Title: cant get enough of it!!!; Content: Our ... 59
298 Title: Food Caused Illness; Content: I switche... 131
960 Title: My furbabies LOVE these!; Content: Shak... 47
embedding Cluster
536 [-0.002376032527536154, -0.0027701142244040966... 1
332 [0.02162935584783554, -0.011174295097589493, -... 1
424 [-0.007517425809055567, 0.0037251529283821583,... 1
298 [-0.0011128562036901712, -0.01970377005636692,... 1
960 [-0.009749102406203747, -0.0068712360225617886... 1
Cluster 2 Theme: Unnamed: 0 ProductId UserId Score \
135 410 B007Y59HVM A2ERWXZEUD6APD 5
439 812 B0001UK0CM A2V8WXAFG1TEOC 5
326 107 B003VXFK44 A21VWSCGW7UUAR 4
475 852 B000I6MCSY AO34Q3JGZU0JQ 5
692 922 B003TC7WN4 A3GFZIL1E0Z5V8 5
Summary \
135 Fog Chaser Coffee
439 Excellent taste
326 Good, but not Wolfgang Puck good
475 Just My Kind of Coffee
692 Rodeo Drive is Crazy Good Coffee!
Text \
135 This coffee has a full body and a rich taste. ...
439 This is to me a great coffee, once you try it ...
326 Honestly, I have to admit that I expected a li...
475 Coffee Masters Hazelnut coffee used to be carr...
692 Rodeo Drive is my absolute favorite and I'm re...
combined n_tokens \
135 Title: Fog Chaser Coffee; Content: This coffee... 42
439 Title: Excellent taste; Content: This is to me... 31
326 Title: Good, but not Wolfgang Puck good; Conte... 178
475 Title: Just My Kind of Coffee; Content: Coffee... 118
692 Title: Rodeo Drive is Crazy Good Coffee!; Cont... 59
embedding Cluster
135 [0.006498195696622133, 0.006776264403015375, 0... 2
439 [0.0039436533115804195, -0.005451332312077284,... 2
326 [-0.003140551969408989, -0.009995664469897747,... 2
475 [0.010913548991084099, -0.014923149719834328, ... 2
692 [-0.029914353042840958, -0.007755572907626629,... 2
Cluster 3 Theme: Unnamed: 0 ProductId UserId Score \
495 831 B0014X5O1C AHYRTWABDAG1H 5
978 642 B00264S63G A36AUU1UNRS48G 5
916 686 B008PYVINQ A1DRWYIO7JN1MD 2
696 926 B0062P9XPU A33KQALCZGXG8C 5
491 828 B000EIE20M A39QHSDUBR8L0T 3
Summary \
495 Wonderful alternative to soda pop
978 So convenient, for so little!
916 bot very cheesy
696 Delicious!
491 Just ok
Text \
495 This is a wonderful alternative to soda pop. ...
978 I needed two vanilla beans for the Love Goddes...
916 Got this about a month ago.first of all it sme...
696 I am not a huge beer lover. I do enjoy an occ...
491 I bought this brand because it was all they ha...
combined n_tokens \
495 Title: Wonderful alternative to soda pop; Cont... 273
978 Title: So convenient, for so little!; Content:... 121
916 Title: bot very cheesy; Content: Got this abou... 46
696 Title: Delicious!; Content: I am not a huge be... 97
491 Title: Just ok; Content: I bought this brand b... 58
embedding Cluster
495 [0.022326279431581497, -0.018449820578098297, ... 3
978 [-0.004598899278789759, -0.01737511157989502, ... 3
916 [-0.010750919580459595, -0.0193503275513649, -... 3
696 [0.009483409114181995, -0.017691848799586296, ... 3
491 [-0.0023960231337696314, -0.006881058216094971... 3
여기서 데이터를 아래와 같이 가공을 합니다.
for j in range(rev_per_cluster):
print(sample_cluster_rows.Score.values[j], end=", ")
print(sample_cluster_rows.Summary.values[j], end=": ")
print(sample_cluster_rows.Text.str[:70].values[j])
Score의 값들을 가지고 오고 끝에는 쉼표 , 를 붙입니다.
그리고 Summary의 값을 가지고 오고 끝에는 : 를 붙입니다.
그리고 Text컬럼의 string을 가지고 오는데 70자 까지만 가지고 옵니다.
전체 결과를 보겠습니다.
Cluster 0 Theme: Customer reviews:gluten free, healthy bars, content:The customer reviews have in common that they save money on Amazon by ordering by themselves by looking for gluten free healthy bars. The bars are also delicious.
5, Loved these gluten free healthy bars, saved $$ ordering on Amazon: These Kind Bars are so good and healthy & gluten free. My daughter ca
1, Should advertise coconut as an ingredient more prominently: First, these should be called Mac - Coconut bars, as Coconut is the #2
5, very good!!: just like the runts<br />great flavor, def worth getting<br />I even o
5, Excellent product: After scouring every store in town for orange peels and not finding an
5, delicious: Gummi Frogs have been my favourite candy that I have ever tried. of co
Cluster 1 Theme: Cat foodMessy, undelicious, and possibly unhealthy.
2, Messy and apparently undelicious: My cat is not a huge fan. Sure, she'll lap up the gravy, but leaves th
4, The cats like it: My 7 cats like this food but it is a little yucky for the human. Piece
5, cant get enough of it!!!: Our lil shih tzu puppy cannot get enough of it. Everytime she sees the
1, Food Caused Illness: I switched my cats over from the Blue Buffalo Wildnerness Food to this
5, My furbabies LOVE these!: Shake the container and they come running. Even my boy cat, who isn't
Cluster 2 Theme: CoffeeThe customer's reviews have in common that they are among the best in the market, Rodeo Drive, and that the customer is able to enjoy their coffee half and half because they have an Amazon account.
5, Fog Chaser Coffee: This coffee has a full body and a rich taste. The price is far below t
5, Excellent taste: This is to me a great coffee, once you try it you will enjoy it, this
4, Good, but not Wolfgang Puck good: Honestly, I have to admit that I expected a little better. That's not
5, Just My Kind of Coffee: Coffee Masters Hazelnut coffee used to be carried in a local coffee/pa
5, Rodeo Drive is Crazy Good Coffee!: Rodeo Drive is my absolute favorite and I'm ready to order more! That
Cluster 3 Theme: Customer reviews of different brands of soda.
5, Wonderful alternative to soda pop: This is a wonderful alternative to soda pop. It's carbonated for thos
5, So convenient, for so little!: I needed two vanilla beans for the Love Goddess cake that my husbands
2, bot very cheesy: Got this about a month ago.first of all it smells horrible...it tastes
5, Delicious!: I am not a huge beer lover. I do enjoy an occasional Blue Moon (all o
3, Just ok: I bought this brand because it was all they had at Ranch 99 near us. I
이제 좀 보기 좋게 됐습니다.
이번 예제는 raw 데이터를 파이썬의 여러 모듈들을 이용해서 clustering을 하고 이 cluster별로 openai.Completion.create() api를 이용해서 궁금한 답을 받는 일을 하는 예제를 배웠습니다.
큰 raw data를 카테고리화 해서 나누고 이에 대한 summary나 기타 정보를 Completion api를 통해 얻을 수 있는 방법입니다.
전체 소스코드는 아래와 같습니다.
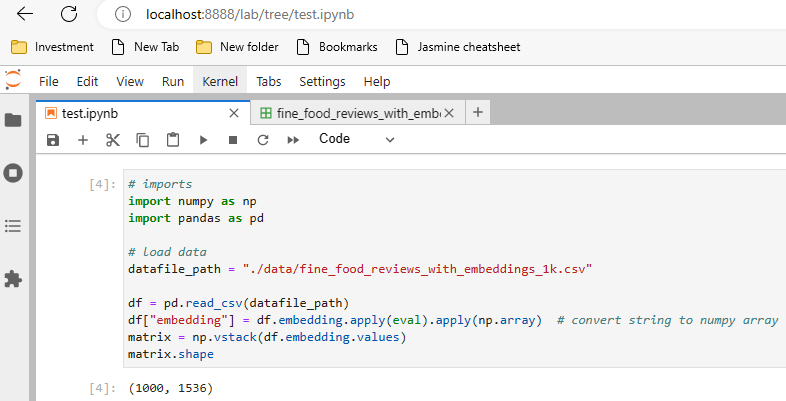
# imports
import numpy as np
import pandas as pd
# load data
datafile_path = "./data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(eval).apply(np.array) # convert string to numpy array
matrix = np.vstack(df.embedding.values)
matrix.shape
from sklearn.cluster import KMeans
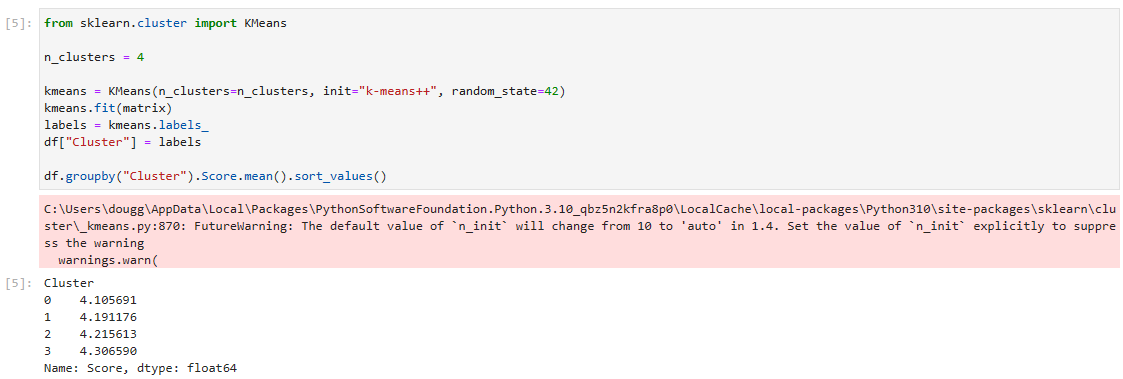
n_clusters = 4
kmeans = KMeans(n_clusters=n_clusters, init="k-means++", random_state=42)
kmeans.fit(matrix)
labels = kmeans.labels_
df["Cluster"] = labels
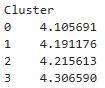
df.groupby("Cluster").Score.mean().sort_values()
from sklearn.manifold import TSNE
import matplotlib
import matplotlib.pyplot as plt
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init="random", learning_rate=200)
vis_dims2 = tsne.fit_transform(matrix)
x = [x for x, y in vis_dims2]
y = [y for x, y in vis_dims2]
for category, color in enumerate(["purple", "green", "red", "blue"]):
xs = np.array(x)[df.Cluster == category]
ys = np.array(y)[df.Cluster == category]
plt.scatter(xs, ys, color=color, alpha=0.3)
avg_x = xs.mean()
avg_y = ys.mean()
plt.scatter(avg_x, avg_y, marker="x", color=color, s=100)
plt.title("Clusters identified visualized in language 2d using t-SNE")
import openai
def open_file(filepath):
with open(filepath, 'r', encoding='utf-8') as infile:
return infile.read()
openai.api_key = open_file('openaiapikey.txt')
# Reading a review which belong to each group.
rev_per_cluster = 5
for i in range(n_clusters):
print(f"Cluster {i} Theme:", end=" ")
reviews = "\n".join(
df[df.Cluster == i]
.combined.str.replace("Title: ", "")
.str.replace("\n\nContent: ", ": ")
.sample(rev_per_cluster, random_state=42)
.values
)
response = openai.Completion.create(
engine="text-ada-001", #"text-davinci-003",
prompt=f'What do the following customer reviews have in common?\n\nCustomer reviews:\n"""\n{reviews}\n"""\n\nTheme:',
temperature=0,
max_tokens=64,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
)
print(response["choices"][0]["text"].replace("\n", ""))
sample_cluster_rows = df[df.Cluster == i].sample(rev_per_cluster, random_state=42)
for j in range(rev_per_cluster):
print(sample_cluster_rows.Score.values[j], end=", ")
print(sample_cluster_rows.Summary.values[j], end=": ")
print(sample_cluster_rows.Text.str[:70].values[j])
데이터 구조를 byte stream으로 변환하면 저장하거나 네트워크로 전송할 수 있습니다.
이런 것을 marshalling 이라고 하고 그 반대를 unmarshalling 이라고 합니다.
이런 작업을 할 수 있는 모듈은 아래 세가지가 있습니다.
marshal은 셋 중 가장 오래된 모듈이다. 이것은 주로 컴파일된 바이트코드 또는 인터프리터가 파이썬 모듈을 가져올 떄 얻는 .pyc 파일을 읽고 쓰기 위해 존재한다. 때문에 marshal로 객체를 직렬화할 수 있더라도, 이를 추천하지는 않는다.
json모듈은 셋 중 가장 최신의 모듈이다. 이를 통해 표준 JSON 파일로 작업을 할 수 있다. json 모듈을 통해 다양한 표준 파이썬 타입(bool, dict, int, float, list, string, tuple, None)을 직렬화, 역직렬화할 수 있다. json은 사람이 읽을 수 있고, 언어에 의존적이지 않다는 장점이 있다.
pickle모듈은 파이썬에서 객체를 직렬화 또는 역직렬화하는 또 다른 방식이다. json 모듈과는 다르게 객체를바이너리 포맷으로 직렬화한다. 이는 결과를 사람이 읽을 수 없다는 것을 의미한다. 그러나더 빠르고, 사용자 커스텀 객체 등더 다양한 파이썬 타입으로 동작할 수 있음을 의미한다.
bz2 를 csv 로 convert 시키는 온라인 툴에서 변환을 시도 했는데 너무 크기가 커서 실패 했습니다.
그래서 데이터소스가 없어서 이번 예제는 실행은 못 해 보고 소스만 분석하겠습니다.
위의 소스 코드는 데이터를 pandas의 read_csv() 로 읽어서 첫번째 5개만 df에 담는 역할을 합니다.
이런 결과를 얻을 수 있습니다.
# print the title, description, and label of each examplefor idx, row in df.head(n_examples).iterrows():
print("")
print(f"Title: {row['title']}")
print(f"Description: {row['description']}")
print(f"Label: {row['label']}")
그 다음은 Title, Description, Lable 을 print 하는 부분 입니다.
여기까지 만들고 실행하면 아래 결과를 얻을 수 있습니다.
Title: World Briefings
Description: BRITAIN: BLAIR WARNS OF CLIMATE THREAT Prime Minister Tony Blair urged the international community to consider global warming a dire threat and agree on a plan of action to curb the quot;alarming quot; growth of greenhouse gases.
Label: World
Title: Nvidia Puts a Firewall on a Motherboard (PC World)
Description: PC World - Upcoming chip set will include built-in security features for your PC.
Label: Sci/Tech
Title: Olympic joy in Greek, Chinese press
Description: Newspapers in Greece reflect a mixture of exhilaration that the Athens Olympics proved successful, and relief that they passed off without any major setback.
Label: Sports
Title: U2 Can iPod with Pictures
Description: SAN JOSE, Calif. -- Apple Computer (Quote, Chart) unveiled a batch ofnew iPods, iTunes software and promos designed to keep it atop the heap of digital music players.
Label: Sci/Tech
Title: The Dream Factory
Description: Any product, any shape, any size -- manufactured on your desktop! The future is the fabricator. By Bruce Sterling from Wired magazine.
Label: Sci/Tech
여기까지 진행하면 아래와 같은 소스코드를 얻을 수 있을 겁니다.
# imports
import pandas as pd
import pickle
import openai
from openai.embeddings_utils import (
get_embedding,
distances_from_embeddings,
tsne_components_from_embeddings,
chart_from_components,
indices_of_nearest_neighbors_from_distances,
)
# constants
EMBEDDING_MODEL = "text-embedding-ada-002"
def open_file(filepath):
with open(filepath, 'r', encoding='utf-8') as infile:
return infile.read()
openai.api_key = open_file('openaiapikey.txt')
# load data (full dataset available at http://groups.di.unipi.it/~gulli/AG_corpus_of_news_articles.html)
dataset_path = "data/AG_news_samples.csv"
df = pd.read_csv(dataset_path)
# print dataframe
n_examples = 5
df.head(n_examples)
# print the title, description, and label of each examplefor idx, row in df.head(n_examples).iterrows():
print("")
print(f"Title: {row['title']}")
print(f"Description: {row['description']}")
print(f"Label: {row['label']}")
3. Build cache to save embeddings
이 기사들에 대해 임베딩 값을 얻기 전에 임베딩을 값을 저장할 캐시를 세팅해 보겠습니다.
이렇게 얻은 임베딩을 저장해서 재 사용하면 이 값을 얻기 위해 openai api를 call 하지 않아도 되기 때문에 비용을 절감할 수 있습니다.
이 캐시는 dictionary로 (text, model) 의 tuples로 매핑되 있습니다.
이 캐시는 Python pickle 파일로 저장 될 것입니다.
# establish a cache of embeddings to avoid recomputing# cache is a dict of tuples (text, model) -> embedding, saved as a pickle file# set path to embedding cache
embedding_cache_path = "data/recommendations_embeddings_cache.pkl"# load the cache if it exists, and save a copy to disk
try:
embedding_cache = pd.read_pickle(embedding_cache_path)
except FileNotFoundError:
embedding_cache = {}
with open(embedding_cache_path, "wb") as embedding_cache_file:
pickle.dump(embedding_cache, embedding_cache_file)
# define a function to retrieve embeddings from the cache if present, and otherwise request via the API
def embedding_from_string(
string: str,
model: str = EMBEDDING_MODEL,
embedding_cache=embedding_cache
) -> list:
"""Return embedding of given string, using a cache to avoid recomputing."""if (string, model) not in embedding_cache.keys():
embedding_cache[(string, model)] = get_embedding(string, model)
with open(embedding_cache_path, "wb") as embedding_cache_file:
pickle.dump(embedding_cache, embedding_cache_file)
return embedding_cache[(string, model)]
처음에 저장될 위치와 pkl 파일 이름을 embedding_cache_path 변수에 담습니다.
다음은 이 cache가 있으면 카피를 저장하는 보분입니다.
pandas의 read_pickle() 함수를 통해 읽습니다. (embedding_cache에 담음)
이 파일을 오픈할 때 사용한 wb 는 파일을 binary format으로 오픈하고 쓰기 기능이 있다는 의미 입니다.
그 다음은 embedding_from_string() 함수 입니다.
입력값으로는 string과 openai의 모델명 그리고 embedding_cache를 받습니다.
출력은 리스트 형식입니다.
다음 if 문은 sriing과 model 이 embedding_cache.keys() 에 없다면 get_embedding()을 통해서 임베딩 값을 얻는 일을 합니다. 여기서도 파일은 바이너리 형태로 열고 쓰기 기능이 허락돼 있습니다.
pickle.dump()는 해당 내용을 파일에 저장할 때사용하는 pickle 모듈의 api 함수 입니다.
# as an example, take the first description from the dataset
example_string = df["description"].values[0]
print(f"\nExample string: {example_string}")
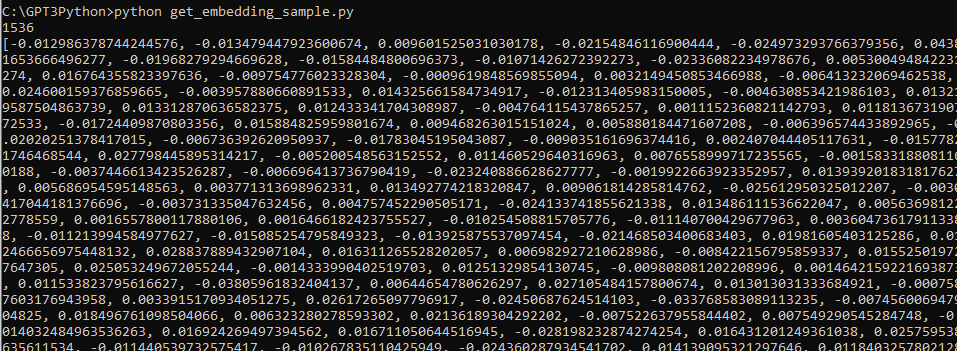
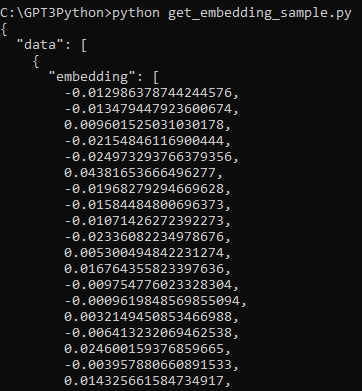
# print the first 10 dimensions of the embedding
example_embedding = embedding_from_string(example_string)
print(f"\nExample embedding: {example_embedding[:10]}...")
이 부분은 위에 작성한 스크립트가 잘 작동하는지 print 해 보는 겁니다.
여기까지 작성 한 것을 실행 하면 아래 출력을 얻을 수 있습니다.
4. Recommend similar articles based on embeddings
비슷한 기사를 찾기 위해서는 아래 3단계를 거쳐야 합니다.
1. 모든 기사의 description들에 대해 similarity 임베딩 값을 얻는다.
2. 소스 타이틀과 다른 모든 기사들간의 distance를 계산한다.
3. source title에 다른 기사들의 closest를 프린트 한다.
defprint_recommendations_from_strings(
strings: list[str],
index_of_source_string: int,
k_nearest_neighbors: int = 1,
model=EMBEDDING_MODEL,
) -> list[int]:"""Print out the k nearest neighbors of a given string."""# get embeddings for all strings
embeddings = [embedding_from_string(string, model=model) for string in strings]
# get the embedding of the source string
query_embedding = embeddings[index_of_source_string]
# get distances between the source embedding and other embeddings (function from embeddings_utils.py)
distances = distances_from_embeddings(query_embedding, embeddings, distance_metric="cosine")
# get indices of nearest neighbors (function from embeddings_utils.py)
indices_of_nearest_neighbors = indices_of_nearest_neighbors_from_distances(distances)
# print out source string
query_string = strings[index_of_source_string]
print(f"Source string: {query_string}")
# print out its k nearest neighbors
k_counter = 0for i in indices_of_nearest_neighbors:
# skip any strings that are identical matches to the starting stringif query_string == strings[i]:
continue# stop after printing out k articlesif k_counter >= k_nearest_neighbors:
break
k_counter += 1# print out the similar strings and their distancesprint(
f"""
--- Recommendation #{k_counter} (nearest neighbor {k_counter} of {k_nearest_neighbors}) ---
String: {strings[i]}
Distance: {distances[i]:0.3f}"""
)
return indices_of_nearest_neighbors
이 소스 코드가 그 일을 합니다.
모든 string들에 대한 임베딩 값들을 받아서 distance를 구합니다. (distances_from_embeddings())
그리고 나서 가장 가까운 neighbor들을 구합니다. (indices_of_nearest_neighbors_from_distances())
그리고 query string을 print 합니다.
그리고 indices_of_nearest_neighbors 에 있는 요소들 만큼 for 루프를 돌리면서 Recommendation을 String, Distance 정보와 함께 print 합니다.
최종적으로 indices_of_nearest_neighbors를 return 합니다.
5. Example recommendations
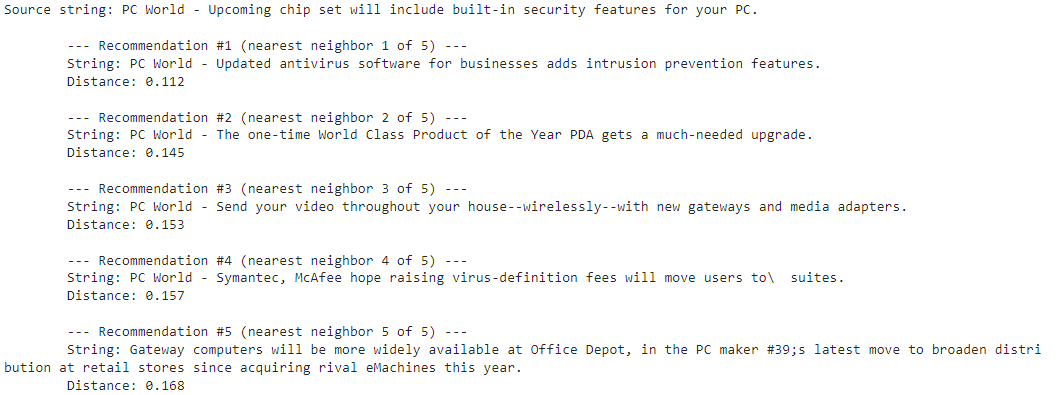
우선 Tony Blair에 대한 유사한 아티클들을 먼저 보죠.
article_descriptions = df["description"].tolist()
tony_blair_articles = print_recommendations_from_strings(
strings=article_descriptions, # let's base similarity off of the article description
index_of_source_string=0, # let's look at articles similar to the first one about Tony Blair
k_nearest_neighbors=5, # let's look at the 5 most similar articles
)
이렇게 하면 다음과 같은 정보를 얻을 수 있습니다.
첫 4개 기사에 토니 블레어가 언급 돼 있고 다섯번째에는 런던발 기후 변화에 대한 내용이 있습니다. 이것도 토니 블레어와 연관이 있다고 얘기할 수 있겠네요.
그러면 두번째 주제인 NVIDIA에 대한 결과물을 보겠습니다.
chipset_security_articles = print_recommendations_from_strings(
strings=article_descriptions, # let's base similarity off of the article description
index_of_source_string=1, # let's look at articles similar to the second one about a more secure chipset
k_nearest_neighbors=5, # let's look at the 5 most similar articles
)
결과를 보면 #1이 다른 결과물들 보다 가장 유사성이 큰 것을 볼 수 있습니다. (거리가 가깝다)
그 내용도 주어진 주제와 가장 가깝습니다.
Appendix: Using embeddings in more sophisticated recommenders
이 추천 시스템을 빌드하기 위한 좀 더 정교한 방법은 항목의 인기도, 사용자 클릭 데이터 같은 수많은 signal들을 가지고 machine learning 모델을 훈련 시키는 것입니다.
추천 시스템에서도 임베딩은 아주 유용하게 이용될 수 있습니다.
아직 기존의 유저 데이터가 없는 신제품에 대한 정보 같은 것들에 대해서 특히 이 임베딩은 잘 사용될 수 있습니다.
Appendix: Using embeddings to visualize similar articles
이 임베딩을 시각화 할 수도 있습니다. t-SNE 혹은 PCA와 같은 기술을 이용해서 임베딩을 2차원 또는 3차원 챠트로 만들 수 있습니다.
여기서는 t-SNE를 사용해서 모든 기사 설명을 시각화 해 봅니다.
(이와 관련된 결과물은 실행 때마다 조금씩 달라질 수 있습니다.)
# get embeddings for all article descriptionsembeddings = [embedding_from_string(string) for string in article_descriptions]# compress the 2048-dimensional embeddings into 2 dimensions using t-SNEtsne_components = tsne_components_from_embeddings(embeddings)# get the article labels for coloring the chartlabels = df["label"].tolist()chart_from_components(components=tsne_components,labels=labels,strings=article_descriptions,width=600,height=500,title="t-SNE components of article descriptions",)
다음은 source article, nearest neighbors 혹은 그 외 다른 것인지에 따라 다른 색으로 나타내 보는 코드 입니다.
# create labels for the recommended articlesdefnearest_neighbor_labels(
list_of_indices: list[int],
k_nearest_neighbors: int = 5) -> list[str]:"""Return a list of labels to color the k nearest neighbors."""
labels = ["Other"for _ in list_of_indices]
source_index = list_of_indices[0]
labels[source_index] = "Source"for i inrange(k_nearest_neighbors):
nearest_neighbor_index = list_of_indices[i + 1]
labels[nearest_neighbor_index] = f"Nearest neighbor (top {k_nearest_neighbors})"return labels
tony_blair_labels = nearest_neighbor_labels(tony_blair_articles, k_nearest_neighbors=5)
chipset_security_labels = nearest_neighbor_labels(chipset_security_articles, k_nearest_neighbors=5
)
# a 2D chart of nearest neighbors of the Tony Blair articlechart_from_components(components=tsne_components,labels=tony_blair_labels,strings=article_descriptions,width=600,height=500,title="Nearest neighbors of the Tony Blair article",category_orders={"label": ["Other", "Nearest neighbor (top 5)", "Source"]},)
# a 2D chart of nearest neighbors of the chipset security articlechart_from_components(components=tsne_components,labels=chipset_security_labels,strings=article_descriptions,width=600,height=500,title="Nearest neighbors of the chipset security article",category_orders={"label": ["Other", "Nearest neighbor (top 5)", "Source"]},)
이런 과정을 통해 결과를 시각화 하면 좀 더 다양한 정보들을 얻을 수 있습니다.
이번 예제는 여기서 사용된 소스 데이터를 구하지 못해서 직접 실행은 못해 봤네요.
다음에 소스데이터를 구할 기회가 생기면 한번 직접 실행 해 봐야 겠습니다.
이 예제를 전부 완성하면 아래와 같은 소스 코드가 될 것입니다.
# imports
import pandas as pd
import pickle
import openai
from openai.embeddings_utils import (
get_embedding,
distances_from_embeddings,
tsne_components_from_embeddings,
chart_from_components,
indices_of_nearest_neighbors_from_distances,
)
# constants
EMBEDDING_MODEL = "text-embedding-ada-002"
def open_file(filepath):
with open(filepath, 'r', encoding='utf-8') as infile:
return infile.read()
openai.api_key = open_file('openaiapikey.txt')
# load data (full dataset available at http://groups.di.unipi.it/~gulli/AG_corpus_of_news_articles.html)
dataset_path = "data/AG_news_samples.csv"
df = pd.read_csv(dataset_path)
# print dataframe
n_examples = 5
df.head(n_examples)
# print the title, description, and label of each examplefor idx, row in df.head(n_examples).iterrows():
print("")
print(f"Title: {row['title']}")
print(f"Description: {row['description']}")
print(f"Label: {row['label']}")
# establish a cache of embeddings to avoid recomputing# cache is a dict of tuples (text, model) -> embedding, saved as a pickle file# set path to embedding cache
embedding_cache_path = "data/recommendations_embeddings_cache.pkl"# load the cache if it exists, and save a copy to disk
try:
embedding_cache = pd.read_pickle(embedding_cache_path)
except FileNotFoundError:
embedding_cache = {}
with open(embedding_cache_path, "wb") as embedding_cache_file:
pickle.dump(embedding_cache, embedding_cache_file)
# define a function to retrieve embeddings from the cache if present, and otherwise request via the API
def embedding_from_string(
string: str,
model: str = EMBEDDING_MODEL,
embedding_cache=embedding_cache
) -> list:
"""Return embedding of given string, using a cache to avoid recomputing."""if (string, model) not in embedding_cache.keys():
embedding_cache[(string, model)] = get_embedding(string, model)
with open(embedding_cache_path, "wb") as embedding_cache_file:
pickle.dump(embedding_cache, embedding_cache_file)
return embedding_cache[(string, model)]
# as an example, take the first description from the dataset
example_string = df["description"].values[0]
print(f"\nExample string: {example_string}")
# print the first 10 dimensions of the embedding
example_embedding = embedding_from_string(example_string)
print(f"\nExample embedding: {example_embedding[:10]}...")
def print_recommendations_from_strings(
strings: list[str],
index_of_source_string: int,
k_nearest_neighbors: int = 1,
model=EMBEDDING_MODEL,
) -> list[int]:
"""Print out the k nearest neighbors of a given string."""# get embeddings for all strings
embeddings = [embedding_from_string(string, model=model) for string in strings]
# get the embedding of the source string
query_embedding = embeddings[index_of_source_string]
# get distances between the source embedding and other embeddings (function from embeddings_utils.py)
distances = distances_from_embeddings(query_embedding, embeddings, distance_metric="cosine")
# get indices of nearest neighbors (function from embeddings_utils.py)
indices_of_nearest_neighbors = indices_of_nearest_neighbors_from_distances(distances)
# print out source string
query_string = strings[index_of_source_string]
print(f"Source string: {query_string}")
# print out its k nearest neighbors
k_counter = 0
for i in indices_of_nearest_neighbors:
# skip any strings that are identical matches to the starting stringif query_string == strings[i]:
continue# stop after printing out k articlesif k_counter >= k_nearest_neighbors:
break
k_counter += 1
# print out the similar strings and their distancesprint(
f"""
--- Recommendation #{k_counter} (nearest neighbor {k_counter} of {k_nearest_neighbors}) ---
String: {strings[i]}
Distance: {distances[i]:0.3f}"""
)
return indices_of_nearest_neighbors
article_descriptions = df["description"].tolist()
tony_blair_articles = print_recommendations_from_strings(
strings=article_descriptions, # let's base similarity off of the article description
index_of_source_string=0, # let's look at articles similar to the first one about Tony Blair
k_nearest_neighbors=5, # let's look at the 5 most similar articles
)
chipset_security_articles = print_recommendations_from_strings(
strings=article_descriptions, # let's base similarity off of the article description
index_of_source_string=1, # let's look at articles similar to the second one about a more secure chipset
k_nearest_neighbors=5, # let's look at the 5 most similar articles
)
# get embeddings for all article descriptions
embeddings = [embedding_from_string(string) for string in article_descriptions]
# compress the 2048-dimensional embeddings into 2 dimensions using t-SNE
tsne_components = tsne_components_from_embeddings(embeddings)
# get the article labels for coloring the chart
labels = df["label"].tolist()
chart_from_components(
components=tsne_components,
labels=labels,
strings=article_descriptions,
width=600,
height=500,
title="t-SNE components of article descriptions",
)
# create labels for the recommended articles
def nearest_neighbor_labels(
list_of_indices: list[int],
k_nearest_neighbors: int = 5
) -> list[str]:
"""Return a list of labels to color the k nearest neighbors."""
labels = ["Other"for _ in list_of_indices]
source_index = list_of_indices[0]
labels[source_index] = "Source"for i in range(k_nearest_neighbors):
nearest_neighbor_index = list_of_indices[i + 1]
labels[nearest_neighbor_index] = f"Nearest neighbor (top {k_nearest_neighbors})"return labels
tony_blair_labels = nearest_neighbor_labels(tony_blair_articles, k_nearest_neighbors=5)
chipset_security_labels = nearest_neighbor_labels(chipset_security_articles, k_nearest_neighbors=5
)
# a 2D chart of nearest neighbors of the Tony Blair article
chart_from_components(
components=tsne_components,
labels=tony_blair_labels,
strings=article_descriptions,
width=600,
height=500,
title="Nearest neighbors of the Tony Blair article",
category_orders={"label": ["Other", "Nearest neighbor (top 5)", "Source"]},
)
# a 2D chart of nearest neighbors of the chipset security article
chart_from_components(
components=tsne_components,
labels=chipset_security_labels,
strings=article_descriptions,
width=600,
height=500,
title="Nearest neighbors of the chipset security article",
category_orders={"label": ["Other", "Nearest neighbor (top 5)", "Source"]},
)
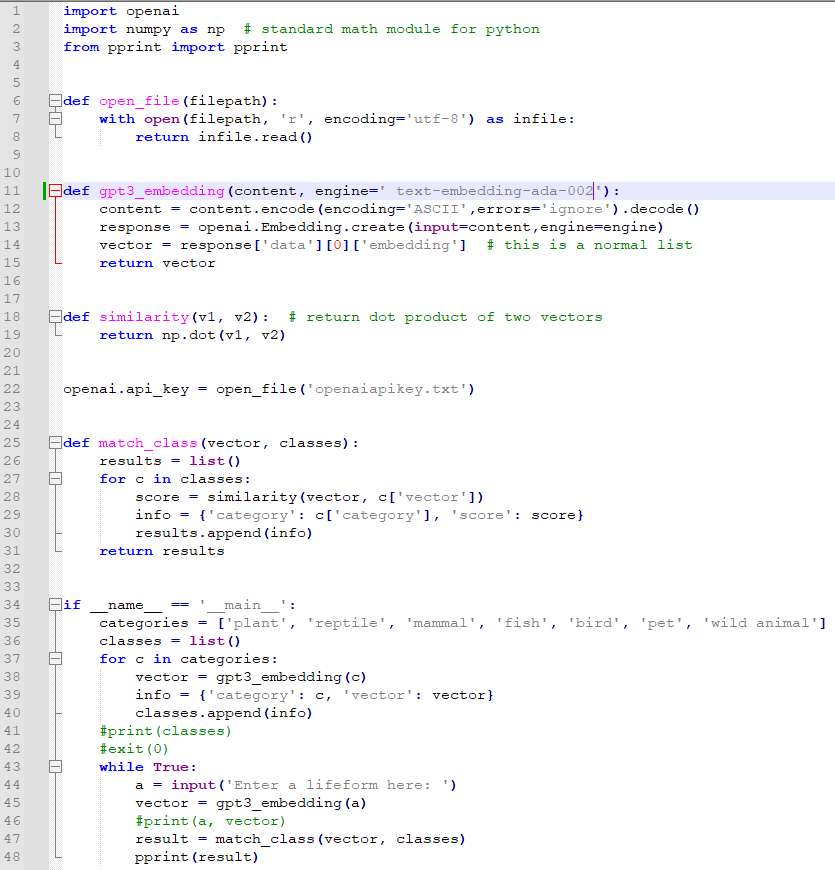
카테고리는 이렇게 7개를 정했습니다. 사용자가 입력한 값이 이 중 어느것에 가장 가까운지 알아 볼 겁니다.
여기에는 다른 값들을 추가해도 됩니다.
예를 들어 food 나 brand 뭐 이런것을 추가해도 될 겁니다.
그 다음은 classes라는 list()를 생성했습니다.
그리고 나서 for 루프가 나오는데요. 이 for 루프는 categories에 있는 인수들 만큼 루프를 돌립니다.
첫번째로 gpt3_embedding(c) 에 각 인수를 전달해서 그 값을 vector에 담습니다.
그 다음 info 에서는 이를 category 별로 그 vector 값이 담기게 합니다.
그리고 아까 만들었든 classes라는 리스트에 이 값을 담습니다.
이러면 categories의 각 인수들 마다 gpt 3 에서 받은 벡터값이 있게 됩니다.
이 벡터값을 이제 사용하게 됩니다.
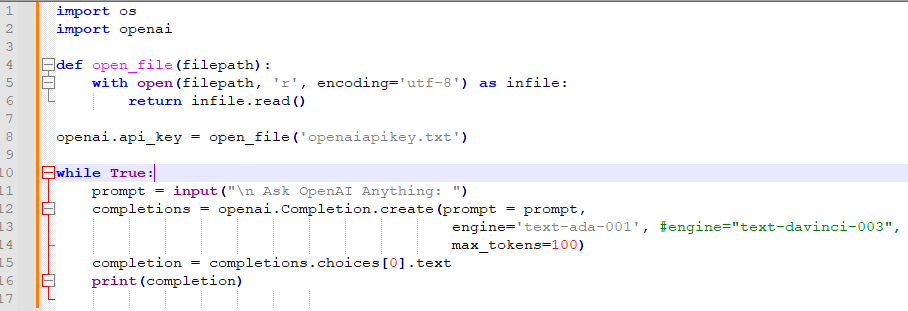
43번째 줄을 보면 while 무한 루프를 만들었습니다.
사용자로부터 계속 입력값을 받기 위함이죠.
44번째 줄은 파이썬의 input() 메소드를 사용해서 사용자로부터 입력 받은 값을 a 라는 변수에 넣는 겁니다.
이 사용자가 입력한 값의 벡터값을 gpt3-embedding() 함수를 통해서 받습니다.
이러면 우리는 입력한 값의 벡터값과 아까 설정해 두었던 categories에 있는 각 인수들의 벡터값을 갖고 있습니다.
그러면 이제 입력한 값이 categories의 각 인수들과 얼마나 유사한지 알 수 있습니다.
47번째 줄에서는 match_class() 함수로 이 두 값을 보내서 각 카테고리별로 유사성 점수가 어떤지 정리한 값을 받습니다.
그 값은 result에 담기게 되고 pprint()를 이용해서 그 값을 이쁘게 출력을 하게 됩니다.
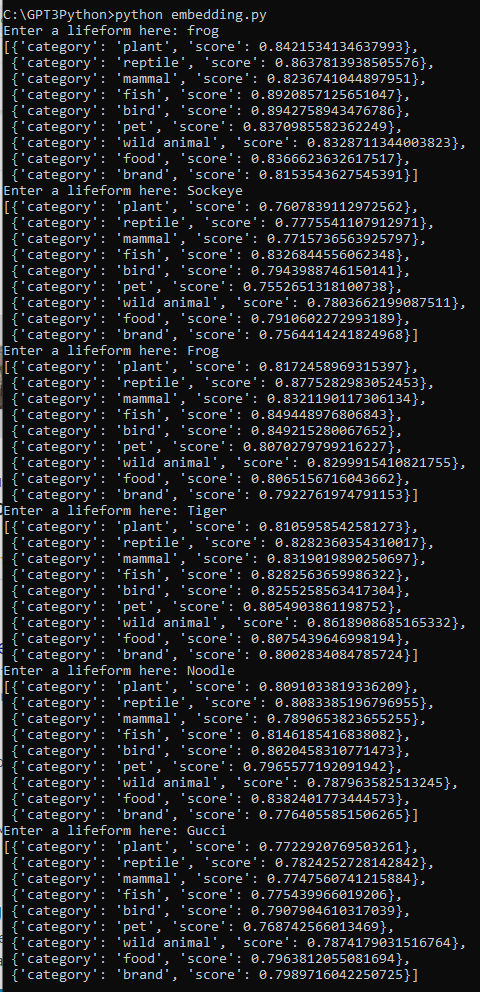
이걸 실행해 봤습니다.
첫번째로 frog 개구리는 새일 가능성이 가장 높고 그 다음은 물고기일 가능성이 높다고 나오네요.
그 다음 파충류일 가능성이 세번째로 높습니다.
양서류라는 보기가 없어서 그럴까요?
그 다음 sockeye는 연어의 종류인데요. 결과는 물고기일 확률이 제일 높게 나옵니다. 그 다음은 새, 그리고 음식 뭐 이런 순으로 나가네요.
그 다음은 개구리를 대문자 F를 사용해서 입력했습니다.
그러면 파충류일 가능성이 제일 높다고 나오네요.
다음 호랑이는 야생동물일 가능성이 가장 높게 나오고 그 다음은 포유류와 유사성이 높다고 나옵니다.
국수를 입력했을 때는 역시 음식이 가장 유사하고 그 다음은 물고기, 식물 뭐 이런 순으로 나옵니다.
구찌를 입력했을 때는 브랜드와 가장 유사하고 그 다음은 음식, 그 다음은 새 이렇게 나옵니다.
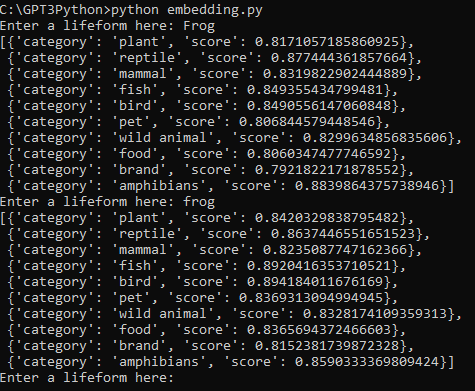
아까 개구리가 약간 이상하게 나와서... 보기에 양서류 (amphibians)를 추가 했습니다.
그 결과는 Frog 일 경우 양서류와 가장 유사하고 그 다음이 파충류로 나옵니다.
frog 일 경우에는 새일 가능성이 가장 높고 그 다음이 물고기 - 파충류 - 양서류 이런 순서네요.
일단 답은 100% 만족스럽지 않지만 Openai GPT 3 의 Embedding 기능에 대해서 어느 정도 감이 잡혔습니다.
참고로 이 임베딩은 아래와 같은 경우에 사용될 수 있습니다.
Search(where results are ranked by relevance to a query string)
Clustering(where text strings are grouped by similarity)
Recommendations(where items with related text strings are recommended)
Anomaly detection(where outliers with little relatedness are identified)
Diversity measurement(where similarity distributions are analyzed)
Classification(where text strings are classified by their most similar label)
전체 소스 코드는 아래에 있습니다.
import openai import numpy as np # standard math module for python from pprint import pprint
def open_file(filepath): with open(filepath, 'r', encoding='utf-8') as infile: return infile.read()
def gpt3_embedding(content, model='text-embedding-ada-002'): content = content.encode(encoding='ASCII',errors='ignore').decode() response = openai.Embedding.create(input=content,model=model) vector = response['data'][0]['embedding'] # this is a normal list return vector
def similarity(v1, v2): # return dot product of two vectors return np.dot(v1, v2)
openai.api_key = open_file('openaiapikey.txt')
def match_class(vector, classes): results = list() for c in classes: score = similarity(vector, c['vector']) info = {'category': c['category'], 'score': score} results.append(info) return results
if __name__ == '__main__': categories = ['plant', 'reptile', 'mammal', 'fish', 'bird', 'pet', 'wild animal', 'food', 'brand', 'amphibians'] classes = list() for c in categories: vector = gpt3_embedding(c) info = {'category': c, 'vector': vector} classes.append(info) #print(classes) #exit(0) while True: a = input('Enter a lifeform here: ') vector = gpt3_embedding(a) #print(a, vector) result = match_class(vector, classes) pprint(result)