개발자로서 현장에서 일하면서 새로 접하는 기술들이나 알게된 정보 등을 정리하기 위한 블로그입니다. 운 좋게 미국에서 큰 회사들의 프로젝트에서 컬설턴트로 일하고 있어서 새로운 기술들을 접할 기회가 많이 있습니다. 미국의 IT 프로젝트에서 사용되는 툴들에 대해 많은 분들과 정보를 공유하고 싶습니다.
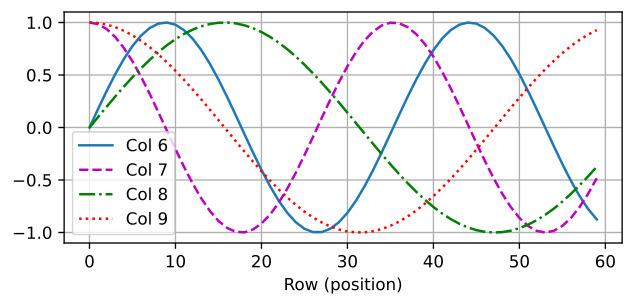
In earlier chapters, we discussed how to train models on the Fashion-MNIST training dataset with only 60000 images. We also described ImageNet, the most widely used large-scale image dataset in academia, which has more than 10 million images and 1000 objects. However, the size of the dataset that we usually encounter is between those of the two datasets.
이전 장에서 60000개의 이미지만으로 Fashion-MNIST 교육 데이터 세트에서 모델을 교육하는 방법에 대해 논의했습니다. 또한 학계에서 가장 널리 사용되는 대규모 이미지 데이터 세트인 ImageNet에 대해서도 설명했습니다. 이 데이터 세트에는 천만 개 이상의 이미지와 1000개 개체가 있습니다. 그러나 우리가 일반적으로 접하는 데이터 세트의 크기는 두 데이터 세트의 중간 크기입니다.
Suppose that we want to recognize different types of chairs from images, and then recommend purchase links to users. One possible method is to first identify 100 common chairs, take 1000 images of different angles for each chair, and then train a classification model on the collected image dataset. Although this chair dataset may be larger than the Fashion-MNIST dataset, the number of examples is still less than one-tenth of that in ImageNet. This may lead to overfitting of complicated models that are suitable for ImageNet on this chair dataset. Besides, due to the limited amount of training examples, the accuracy of the trained model may not meet practical requirements.
이미지에서 다양한 유형의 의자를 인식하고 사용자에게 구매 링크를 추천하고 싶다고 가정합니다. 한 가지 가능한 방법은 먼저 100개의 일반적인 의자를 식별하고 각 의자에 대해 서로 다른 각도의 이미지 1000개를 가져온 다음 수집된 이미지 데이터 세트에서 분류 모델을 훈련하는 것입니다. 이 의자 데이터셋은 Fashion-MNIST 데이터셋보다 클 수 있지만 예제의 수는 여전히 ImageNet의 1/10 미만입니다. 이로 인해 이 의자 데이터 세트에서 ImageNet에 적합한 복잡한 모델이 과대적합될 수 있습니다. 게다가 제한된 양의 학습 예제로 인해 학습된 모델의 정확도가 실제 요구 사항을 충족하지 못할 수 있습니다.
In order to address the above problems, an obvious solution is to collect more data. However, collecting and labeling data can take a lot of time and money. For example, in order to collect the ImageNet dataset, researchers have spent millions of dollars from research funding. Although the current data collection cost has been significantly reduced, this cost still cannot be ignored.
위의 문제를 해결하기 위한 확실한 해결책은 더 많은 데이터를 수집하는 것입니다. 그러나 데이터를 수집하고 레이블을 지정하는 데는 많은 시간과 비용이 소요될 수 있습니다. 예를 들어 ImageNet 데이터 세트를 수집하기 위해 연구자들은 연구 자금에서 수백만 달러를 지출했습니다. 현재 데이터 수집 비용이 크게 줄었지만 이 비용은 여전히 무시할 수 없습니다.
Another solution is to applytransfer learningto transfer the knowledge learned from thesource datasetto thetarget dataset. For example, although most of the images in the ImageNet dataset have nothing to do with chairs, the model trained on this dataset may extract more general image features, which can help identify edges, textures, shapes, and object composition. These similar features may also be effective for recognizing chairs.
또 다른 해결책은 전이 학습(transfer learning)을 적용하여 원본 데이터 세트에서 학습한 지식을 대상 데이터 세트로 이전하는 것입니다. 예를 들어 ImageNet 데이터세트의 대부분의 이미지는 의자와 관련이 없지만 이 데이터세트에서 훈련된 모델은 가장자리, 질감, 모양 및 개체 구성을 식별하는 데 도움이 될 수 있는 보다 일반적인 이미지 기능을 추출할 수 있습니다. 이러한 유사한 기능은 의자를 인식하는 데에도 효과적일 수 있습니다.
Transfer Learning (전이 학습) 이란?
'transfer learning(전이 학습)'은 하나의 작업에서 학습한 모델의 지식을 다른 관련 작업으로 전달하여 학습하는 기술을 말합니다. 기존에 학습된 모델의 일부 또는 전체 네트워크 구조와 가중치를 새로운 작업에 재사용하는 것을 의미합니다. 이를 통해 새로운 작업에 대한 학습 데이터가 부족한 경우에도 모델의 성능을 향상시킬 수 있습니다.
전이 학습은 다음과 같은 장점을 가지고 있습니다:
데이터 부족 문제 해결: 새로운 작업에 충분한 양의 학습 데이터가 없을 때, 기존 작업에서 학습한 모델을 전이하여 성능을 향상시킬 수 있습니다.
학습 시간 단축: 기존에 학습된 모델의 가중치를 초기화로 사용하면 초기 모델의 성능은 높아지며, 새로운 작업에 대한 학습 시간을 단축할 수 있습니다.
일반화 능력 향상: 기존 작업에서 학습한 모델은 이미 다양한 특징을 학습했으므로 이를 활용하여 새로운 작업에서의 성능을 향상시킬 수 있습니다.
전이 학습은 이미지 분류, 객체 검출, 자연어 처리 등 다양한 분야에서 활용되며, 사전 학습된 모델을 가져와서 적절한 수정 및 조정을 통해 새로운 작업에 맞게 재사용하는 것이 일반적인 접근 방식입니다.
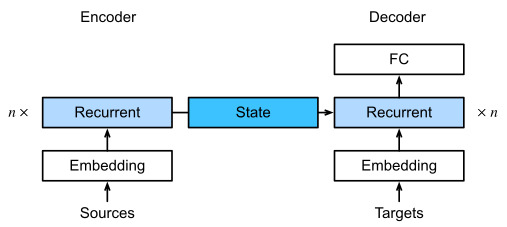
14.2.1.Steps
In this section, we will introduce a common technique in transfer learning:fine-tuning. As shown inFig. 14.2.1, fine-tuning consists of the following four steps:
이 섹션에서는 전이 학습의 일반적인 기술인 미세 조정을 소개합니다. 그림 14.2.1과 같이 미세 조정은 다음 네 단계로 구성됩니다.
Fig. 14.2.1 Fine tuning.
When target datasets are much smaller than source datasets, fine-tuning helps to improve models’ generalization ability.
대상 데이터 세트가 소스 데이터 세트보다 훨씬 작을 때 미세 조정하면 모델의 일반화 능력을 향상시키는 데 도움이 됩니다.
14.2.2.Hot Dog Recognition
Let’s demonstrate fine-tuning via a concrete case: hot dog recognition. We will fine-tune a ResNet model on a small dataset, which was pretrained on the ImageNet dataset. This small dataset consists of thousands of images with and without hot dogs. We will use the fine-tuned model to recognize hot dogs from images.
핫도그 인식이라는 구체적인 사례를 통해 미세 조정을 시연해 보겠습니다. ImageNet 데이터 세트에서 사전 훈련된 작은 데이터 세트에서 ResNet 모델을 미세 조정합니다. 이 작은 데이터 세트는 핫도그가 있거나 없는 수천 개의 이미지로 구성됩니다. 미세 조정된 모델을 사용하여 이미지에서 핫도그를 인식합니다.
%matplotlib inline
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
이 코드는 딥러닝 모델을 구축하고 학습하기 위해 필요한 라이브러리와 설정을 불러오는 부분입니다. 각 줄의 역할을 살펴보겠습니다:
%matplotlib inline: 이 코드는 주피터 노트북 상에서 그래프를 인라인으로 표시하도록 설정하는 매직 명령어입니다. 따라서 그래프를 그릴 때 별도의 창이 아니라 노트북 셀 내에서 바로 보여집니다.
import os: os 모듈은 운영체제와 상호 작용하는 함수를 제공하는 파이썬 내장 모듈입니다. 파일 경로 조작, 환경 변수 설정 등에 사용될 수 있습니다.
import torch: PyTorch 라이브러리를 불러옵니다. 딥러닝 모델을 구축하고 학습하기 위한 핵심 라이브러리입니다.
import torchvision: PyTorch에서 이미지 및 비디오 데이터셋, 변환 등을 처리하기 위한 도구를 제공하는 라이브러리입니다.
from torch import nn: PyTorch의 nn 모듈을 불러옵니다. 이 모듈은 신경망 계층을 정의하고 관리하는 데 사용됩니다.
from d2l import torch as d2l: d2l 모듈에서 torch 모듈을 가져와 d2l이라는 이름으로 사용합니다. 이것은 Dive into Deep Learning (D2L) 프로젝트의 파이썬 유틸리티 모듈로, 딥러닝 학습을 위한 함수 및 도우미 기능을 제공합니다.
이 코드 블록은 딥러닝 모델을 구축하고 학습하는 데 필요한 주요 라이브러리와 설정을 불러오는 역할을 합니다. 해당 코드 이후에 딥러닝 모델을 정의하고 데이터를 불러와 학습하는 등의 작업을 진행할 수 있습니다.
14.2.2.1.Reading the Dataset
The hot dog dataset we use was taken from online images. This dataset consists of 1400 positive-class images containing hot dogs, and as many negative-class images containing other foods. 1000 images of both classes are used for training and the rest are for testing.
우리가 사용하는 핫도그 데이터 세트는 온라인 이미지에서 가져왔습니다. 이 데이터 세트는 핫도그를 포함하는 1400개의 포지티브 클래스 이미지와 다른 음식을 포함하는 많은 네거티브 클래스 이미지로 구성됩니다. 두 클래스의 1000개 이미지는 훈련에 사용되고 나머지는 테스트에 사용됩니다.
After unzipping the downloaded dataset, we obtain two foldershotdog/trainandhotdog/test. Both folders havehotdogandnot-hotdogsubfolders, either of which contains images of the corresponding class.
다운로드한 데이터 세트의 압축을 푼 후 hotdog/train 및 hotdog/test 폴더 두 개를 얻습니다. 두 폴더 모두 핫도그 하위 폴더와 핫도그가 아닌 하위 폴더가 있으며 둘 중 하나에는 해당 클래스의 이미지가 포함되어 있습니다.
이 코드는 D2L (Dive into Deep Learning) 라이브러리의 데이터 허브에 새로운 데이터셋을 등록하고 데이터셋을 다운로드하고 압축을 해제하는 역할을 합니다. 각 줄의 역할을 살펴보겠습니다:
#@save: 이 주석은 코드 블록이 문서화를 위한 주석임을 나타냅니다. D2L에서는 이러한 주석을 사용하여 문서를 생성하는 데 활용합니다.
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip', 'fba480ffa8aa7e0febbb511d181409f899b9baa5'): 이 줄은 데이터 허브에 'hotdog'라는 이름으로 새로운 데이터셋을 등록하는 역할을 합니다. 등록된 데이터셋에 대한 정보 (URL과 해시)를 제공합니다. 이 정보를 통해 데이터셋을 다운로드하고 검증할 수 있습니다.
data_dir = d2l.download_extract('hotdog'): 이 코드는 등록한 'hotdog' 데이터셋을 다운로드하고 압축을 해제하여 로컬 디렉토리에 저장하는 역할을 합니다. 데이터셋의 다운로드 URL과 해시를 사용하여 데이터셋을 검증합니다. data_dir 변수에는 데이터셋이 저장된 로컬 디렉토리 경로가 저장됩니다.
이 코드 블록은 D2L 라이브러리의 데이터 허브에 새로운 데이터셋을 등록하고 해당 데이터셋을 다운로드하고 압축을 해제하여 사용할 수 있도록 준비하는 역할을 합니다.
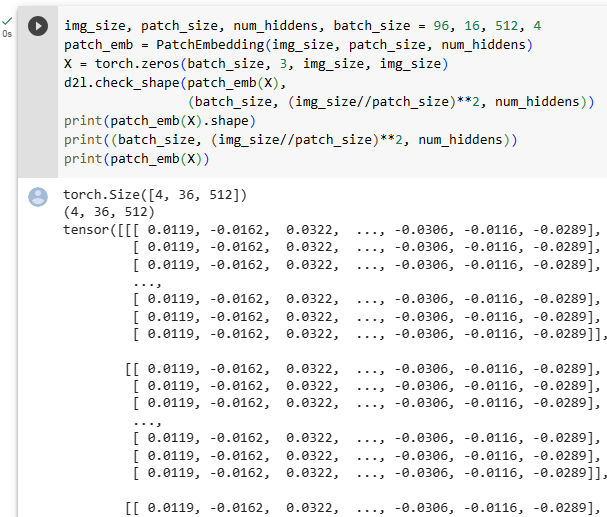
Print number of images in the data_dir.
# Display the first 5 images
for i in range(5):
img = mpimg.imread(image_files[i])
plt.imshow(img)
plt.axis('off') # Turn off axis labels
plt.show()
Number of images: 2800
We create two instances to read all the image files in the training and testing datasets, respectively.
교육 및 테스트 데이터 세트의 모든 이미지 파일을 읽기 위해 각각 두 개의 인스턴스를 만듭니다.
이 코드는 'hotdog' 데이터셋의 학습 및 테스트 이미지들을 로드하는 역할을 합니다. 이해하기 쉽게 코드를 분석해보겠습니다:
#@save: 이 주석은 코드 블록이 문서화를 위한 주석임을 나타냅니다.
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train')): 이 줄은 학습 이미지들이 포함된 디렉토리에서 이미지를 로드하여 train_imgs에 저장합니다. ImageFolder는 디렉토리 구조를 기반으로 이미지 데이터셋을 생성합니다. 학습 이미지들은 'train' 서브디렉토리에 저장되어 있습니다.
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test')): 이 줄은 테스트 이미지들을 로드하여 test_imgs에 저장합니다. 테스트 이미지들은 'test' 서브디렉토리에 저장되어 있습니다.
이렇게 코드를 실행하면 'hotdog' 데이터셋의 학습 이미지와 테스트 이미지를 train_imgs와 test_imgs에 로드하게 됩니다. 'ImageFolder' 클래스는 데이터셋을 쉽게 관리하고 처리할 수 있도록 도와주는 유용한 도구입니다.
The first 8 positive examples and the last 8 negative images are shown below. As you can see, the images vary in size and aspect ratio.
처음 8개의 긍정적인 예와 마지막 8개의 부정적인 이미지가 아래에 나와 있습니다. 보시다시피 이미지의 크기와 종횡비가 다릅니다.
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);
이 코드는 d2l (Dive into Deep Learning) 라이브러리의 d2l.show_images 함수를 사용하여 이미지 그리드를 표시하는 코드입니다. 이 함수는 이미지 목록을 격자 레이아웃으로 표시하는 데 사용됩니다.
코드의 각 부분이 하는 일은 다음과 같습니다.
hotdogs = [train_imgs[i][0] for i in range(8)]: 이 줄은 train_imgs 데이터셋에서 처음 8개의 이미지를 담은 hotdogs 리스트를 생성합니다. hotdogs의 각 요소는 이미지를 나타내는 텐서입니다.
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]: 이 줄은 train_imgs 데이터셋에서 마지막 8개의 이미지를 담은 not_hotdogs 리스트를 생성합니다. 마찬가지로, not_hotdogs의 각 요소는 이미지를 나타내는 텐서입니다.
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);: 이 줄은 d2l.show_images 함수를 사용하여 이미지 그리드를 표시합니다. 표시할 이미지로 hotdogs와 not_hotdogs 리스트를 연결합니다. 2와 8 인자는 격자가 2행 8열을 가지도록 지정합니다. scale=1.4 인자는 표시되는 이미지의 크기를 조정하여 더 나은 가시성을 확보합니다.
요약하면, 이 코드는 d2l.show_images 함수를 사용하여 그리드 형태로 16개의 이미지를 표시합니다. 처음 8개 이미지는 핫도그이고, 마지막 8개 이미지는 핫도그가 아닌 이미지입니다.
During training, we first crop a random area of random size and random aspect ratio from the image, and then scale this area to a224×224input image. During testing, we scale both the height and width of an image to 256 pixels, and then crop a central224×224area as input. In addition, for the three RGB (red, green, and blue) color channels westandardizetheir values channel by channel. Concretely, the mean value of a channel is subtracted from each value of that channel and then the result is divided by the standard deviation of that channel.
학습하는 동안 먼저 이미지에서 임의의 크기와 가로 세로 비율의 임의 영역을 자른 다음 이 영역을 224×224 입력 이미지로 조정합니다. 테스트하는 동안 이미지의 높이와 너비를 모두 256픽셀로 조정한 다음 중앙 224×224 영역을 입력으로 자릅니다. 또한 3개의 RGB(빨간색, 녹색 및 파란색) 색상 채널의 경우 해당 값을 채널별로 표준화합니다. 구체적으로, 채널의 평균값을 해당 채널의 각 값에서 뺀 다음 결과를 해당 채널의 표준 편차로 나눕니다.
# Specify the means and standard deviations of the three RGB channels to
# standardize each channel
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize([256, 256]),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize])
이 코드는 이미지 데이터 전처리를 위한 변환들을 정의하는 부분입니다. 데이터셋을 학습 및 테스트용으로 나눈 후에, 각 데이터셋의 이미지에 대해 수행할 전처리 작업을 설정하는데 사용됩니다. 코드의 각 줄이 하는 역할을 살펴보겠습니다.
normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]): 이 줄은 이미지 정규화를 위한 변환을 정의합니다. 정규화는 각 채널의 평균과 표준 편차를 사용하여 RGB 이미지를 정규화합니다. 이러한 정규화는 모델의 학습 안정성과 성능을 향상시키는 데 도움이 됩니다.
train_augs = torchvision.transforms.Compose([...]): 이 줄은 학습 데이터에 적용할 전처리 과정을 정의합니다. torchvision.transforms.Compose 함수는 여러 개의 전처리 함수를 하나로 연결하여 적용할 수 있게 해줍니다. 학습 데이터에 적용되는 변환은 다음과 같습니다:
RandomResizedCrop(224): 이미지를 임의의 크기로 자르고 224x224 크기로 크롭합니다.
RandomHorizontalFlip(): 이미지를 수평으로 무작위로 뒤집습니다.
ToTensor(): 이미지를 텐서 형식으로 변환합니다.
normalize: 앞서 정의한 정규화를 적용합니다.
test_augs = torchvision.transforms.Compose([...]): 이 줄은 테스트 데이터에 적용할 전처리 과정을 정의합니다. 테스트 데이터에 적용되는 변환은 다음과 같습니다:
Resize([256, 256]): 이미지 크기를 256x256으로 조정합니다.
CenterCrop(224): 이미지를 중앙을 기준으로 224x224 크기로 크롭합니다.
ToTensor(): 이미지를 텐서 형식으로 변환합니다.
normalize: 정규화를 적용합니다.
이렇게 정의된 train_augs와 test_augs는 학습 및 테스트 데이터셋에서 이미지에 적용될 전처리 변환들을 구성합니다.
14.2.2.2.Defining and Initializing the Model
We use ResNet-18, which was pretrained on the ImageNet dataset, as the source model. Here, we specifypretrained=Trueto automatically download the pretrained model parameters. If this model is used for the first time, Internet connection is required for download.
ImageNet 데이터 세트에서 사전 훈련된 ResNet-18을 소스 모델로 사용합니다. 여기에서 pretrained=True를 지정하여 사전 훈련된 모델 매개변수를 자동으로 다운로드합니다. 이 모델을 처음 사용하는 경우 다운로드를 위해 인터넷 연결이 필요합니다.
이 코드는 torchvision 라이브러리의 resnet18 모델을 미리 학습된 가중치와 함께 불러오는 부분입니다.
torchvision.models.resnet18(pretrained=True)은 ResNet-18 아키텍처를 가져와서 미리 학습된 가중치를 사용하여 초기화한 모델을 생성합니다. ResNet-18은 18개의 층으로 구성된 딥 컨볼루션 신경망 아키텍처로, 이미지 분류와 같은 컴퓨터 비전 작업에서 널리 사용됩니다.
pretrained=True 매개변수는 미리 학습된 가중치를 사용하겠다는 의미입니다. 이렇게 하면 모델이 ImageNet 데이터셋에서 사전 학습된 가중치를 가져옵니다. ImageNet은 대규모 이미지 데이터셋으로, 다양한 카테고리에 속하는 이미지로 구성되어 있습니다. 이러한 사전 학습된 가중치는 초기화 단계에서 모델의 성능을 향상시키는 데 도움이 됩니다.
따라서 pretrained_net은 미리 학습된 ResNet-18 모델을 나타냅니다. 이 모델은 이미지 분류 작업에 사용될 수 있으며, 이미지 데이터를 입력으로 받아 각 클래스에 대한 확률 분포를 출력하는 역할을 할 수 있습니다.
사전 훈련된 소스 모델 인스턴스에는 여러 피처 레이어와 출력 레이어 fc가 포함되어 있습니다. 이 분할의 주요 목적은 출력 레이어를 제외한 모든 레이어의 모델 매개변수를 미세 조정하는 것입니다. 소스 모델의 멤버 변수 fc는 다음과 같습니다.
pretrained_net.fc
pretrained_net.fc는 미리 학습된 ResNet-18 모델의 마지막 fully connected (FC) 레이어를 나타냅니다.
ResNet-18 아키텍처의 마지막에는 fully connected 레이어가 존재하며, 이 레이어는 모델이 ImageNet 데이터셋과 같은 대규모 이미지 분류 작업에서 사용될 때 출력 클래스 수에 해당하는 뉴런을 가지고 있습니다. 이 fully connected 레이어는 이미지 특성을 활용하여 각 클래스에 대한 확률 분포를 생성합니다.
pretrained_net.fc를 호출하면 ResNet-18 모델의 마지막 fully connected 레이어가 반환됩니다. 이 레이어는 모델의 출력 역할을 하며, 이 레이어를 통과한 출력은 클래스 확률 분포를 나타냅니다. 이 fully connected 레이어를 변경하거나 새로운 데이터셋에 맞게 fine-tuning하는 등의 작업을 수행할 수 있습니다.
As a fully connected layer, it transforms ResNet’s final global average pooling outputs into 1000 class outputs of the ImageNet dataset. We then construct a new neural network as the target model. It is defined in the same way as the pretrained source model except that its number of outputs in the final layer is set to the number of classes in the target dataset (rather than 1000).
완전히 연결된 계층으로서 ResNet의 최종 글로벌 평균 풀링 출력을 ImageNet 데이터 세트의 1000개 클래스 출력으로 변환합니다. 그런 다음 대상 모델로 새로운 신경망을 구성합니다. 최종 계층의 출력 수가 대상 데이터 세트의 클래스 수(1000이 아닌)로 설정된다는 점을 제외하면 사전 훈련된 소스 모델과 동일한 방식으로 정의됩니다.
In the code below, the model parameters before the output layer of the target model instancefinetune_netare initialized to model parameters of the corresponding layers from the source model. Since these model parameters were obtained via pretraining on ImageNet, they are effective. Therefore, we can only use a small learning rate tofine-tunesuch pretrained parameters. In contrast, model parameters in the output layer are randomly initialized and generally require a larger learning rate to be learned from scratch. Letting the base learning rate beη, a learning rate of10ηwill be used to iterate the model parameters in the output layer.
η - eta
아래 코드에서 대상 모델 인스턴스 finetune_net의 출력 레이어 앞의 모델 매개변수는 소스 모델에서 해당 레이어의 모델 매개변수로 초기화됩니다. 이러한 모델 매개변수는 ImageNet에서 사전 학습을 통해 얻었기 때문에 효과적입니다. 따라서 사전 훈련된 매개변수를 미세 조정하기 위해 작은 학습 속도만 사용할 수 있습니다. 반대로 출력 계층의 모델 매개변수는 무작위로 초기화되며 일반적으로 처음부터 학습하려면 더 큰 학습률이 필요합니다. 기본 학습 속도를 η로 하면 출력 레이어에서 모델 매개변수를 반복하는 데 10η의 학습 속도가 사용됩니다.
위 코드는 미리 학습된 ResNet-18 아키텍처를 가져와서, 해당 아키텍처의 마지막 fully connected 레이어를 새로운 레이어로 교체하는 과정을 나타냅니다.
finetune_net = torchvision.models.resnet18(pretrained=True): 미리 학습된 ResNet-18 모델을 가져옵니다. 이 모델은 ImageNet 데이터셋에서 학습되어 다양한 이미지 분류 작업에 사용할 수 있는 기본 아키텍처와 가중치를 가지고 있습니다.
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2): 기존의 마지막 fully connected 레이어를 새로운 선형 레이어로 교체합니다. 이 때, finetune_net.fc.in_features는 기존 fully connected 레이어의 입력 feature 수를 나타냅니다. 여기서는 이를 유지한 채로 출력 클래스 수를 2로 설정하여 이진 분류 작업에 적합하도록 모델을 수정합니다.
nn.init.xavier_uniform_(finetune_net.fc.weight): 새로운 fully connected 레이어의 가중치를 Xavier 초기화 방법을 사용하여 초기화합니다. 이 초기화 방법은 신경망 가중치 초기화에 일반적으로 사용되는 방법 중 하나로, 초기 가중치를 효과적으로 설정해 네트워크의 학습을 원활하게 만듭니다.
이러한 수정 작업을 통해 ResNet-18 모델을 기존 분류 작업에서 새로운 이진 분류 작업에 맞게 fine-tuning할 수 있습니다. 새로운 fully connected 레이어는 2개의 클래스에 대한 확률 분포를 출력하도록 설정되어 이진 분류 작업을 수행할 수 있게 됩니다.
14.2.2.3.Fine-Tuning the Model
First, we define a training functiontrain_fine_tuningthat uses fine-tuning so it can be called multiple times.
먼저 여러 번 호출할 수 있도록 미세 조정을 사용하는 훈련 함수 train_fine_tuning을 정의합니다.
# If `param_group=True`, the model parameters in the output layer will be
# updated using a learning rate ten times greater
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
if param_group:
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x},
{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
위 코드는 fine-tuning을 통해 사전 훈련된 신경망 모델을 새로운 작업에 맞게 학습시키는 과정을 정의한 함수를 나타냅니다.
train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5, param_group=True): fine-tuning을 수행하기 위한 함수를 정의합니다. net은 모델, learning_rate는 학습률, batch_size는 배치 크기, num_epochs는 학습 에포크 수를 나타냅니다. param_group는 파라미터 그룹화 여부를 결정하는 매개변수로, True로 설정하면 출력 레이어의 가중치에 더 높은 학습률을 적용하는 방식을 사용합니다.
train_iter와 test_iter: 학습 및 테스트 데이터를 DataLoader로 불러오는 과정을 나타냅니다. ImageFolder를 사용하여 데이터셋을 생성하고, transform을 통해 이미지 변환 작업을 수행합니다.
devices = d2l.try_all_gpus(): 사용 가능한 GPU 디바이스를 모두 가져오는 과정입니다.
loss = nn.CrossEntropyLoss(reduction="none"): 손실 함수를 교차 엔트로피 손실로 정의합니다. reduction을 "none"으로 설정하면 배치 내 각 샘플에 대한 손실 값을 구할 수 있습니다.
if param_group:: param_group가 True인 경우, 모델 파라미터를 그룹화하여 학습률을 설정하는 방식을 사용합니다. 이 때, params_1x는 출력 레이어를 제외한 모든 파라미터를 가져오는 리스트입니다. 출력 레이어의 파라미터는 학습률을 10배로 높여서 적용합니다.
trainer = torch.optim.SGD(...): SGD (stochastic gradient descent, 확률적 경사 하강법) 최적화 알고리즘을 사용하여 학습을 수행하는 옵티마이저를 정의합니다. params_1x와 출력 레이어의 파라미터에 서로 다른 학습률을 적용하도록 설정합니다.
d2l.train_ch13(...): 정의한 학습 함수를 호출하여 fine-tuning 학습을 수행합니다. 학습과 테스트 데이터셋, 손실 함수, 옵티마이저 등을 인자로 전달하여 모델을 학습시킵니다.
We set the base learning rate to a small value in order tofine-tunethe model parameters obtained via pretraining. Based on the previous settings, we will train the output layer parameters of the target model from scratch using a learning rate ten times greater.
사전 학습을 통해 얻은 모델 매개 변수를 미세 조정하기 위해 기본 학습 속도를 작은 값으로 설정했습니다. 이전 설정을 기반으로 10배 더 큰 학습률을 사용하여 대상 모델의 출력 계층 매개변수를 처음부터 훈련합니다.
train_fine_tuning(finetune_net, 5e-5)
위 코드는 fine-tuning을 통해 사전 훈련된 ResNet 모델인 finetune_net을 학습하는 과정을 나타냅니다.
train_fine_tuning(finetune_net, 5e-5): train_fine_tuning 함수를 호출하여 finetune_net 모델을 학습합니다. 5e-5는 학습률을 나타내며, 여기서는 상대적으로 작은 학습률로 설정되어 있습니다. 따라서 finetune_net 모델을 학습하면서 학습률을 조절하여 새로운 작업에 맞게 가중치를 조정하게 됩니다.
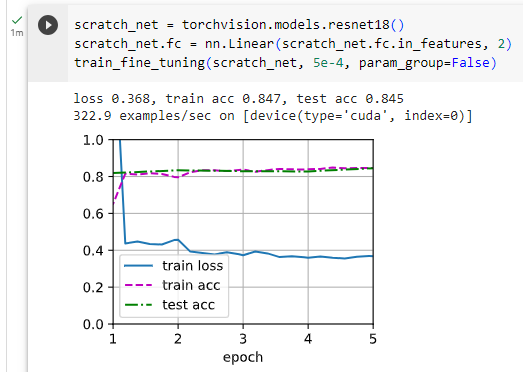
For comparison, we define an identical model, but initialize all of its model parameters to random values. Since the entire model needs to be trained from scratch, we can use a larger learning rate.
비교를 위해 동일한 모델을 정의하지만 모든 모델 매개변수를 임의의 값으로 초기화합니다. 전체 모델을 처음부터 훈련해야 하므로 더 큰 학습률을 사용할 수 있습니다.
위 코드는 "from scratch"로 새로운 ResNet 모델을 생성하고 학습하는 과정을 나타냅니다.
scratch_net = torchvision.models.resnet18(): 새로운 ResNet 모델을 생성합니다. 이 모델은 사전 훈련된 가중치 없이 초기화된 상태입니다.
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2): 생성한 새로운 ResNet 모델의 Fully Connected (FC) 레이어를 수정합니다. 입력 특성 개수에 따라 출력 특성 개수가 2인 FC 레이어로 변경됩니다. 이것은 분류 문제에서 두 개의 클래스를 구분하는 데 사용됩니다.
train_fine_tuning(scratch_net, 5e-4, param_group=False): train_fine_tuning 함수를 호출하여 생성한 새로운 ResNet 모델 scratch_net을 학습합니다. 5e-4는 학습률을 나타내며, param_group=False로 설정되어 FC 레이어에 해당하는 가중치만 학습되며, 사전 훈련된 모델의 가중치는 고정됩니다. 이렇게 하면 새로운 작업에 맞게 FC 레이어만 학습됩니다.
As we can see, the fine-tuned model tends to perform better for the same epoch because its initial parameter values are more effective.
보시다시피 미세 조정된 모델은 초기 매개변수 값이 더 효과적이기 때문에 동일한 에포크에 대해 더 나은 성능을 보이는 경향이 있습니다.
14.2.3.Summary
Transfer learning transfers knowledge learned from the source dataset to the target dataset. Fine-tuning is a common technique for transfer learning. 전이 학습은 원본 데이터 세트에서 학습한 지식을 대상 데이터 세트로 이전합니다. 미세 조정은 전이 학습을 위한 일반적인 기술입니다.
The target model copies all model designs with their parameters from the source model except the output layer, and fine-tunes these parameters based on the target dataset. In contrast, the output layer of the target model needs to be trained from scratch. 대상 모델은 출력 레이어를 제외한 소스 모델의 매개변수가 있는 모든 모델 디자인을 복사하고 대상 데이터 세트를 기반으로 이러한 매개변수를 미세 조정합니다. 반대로 대상 모델의 출력 계층은 처음부터 학습해야 합니다.
Generally, fine-tuning parameters uses a smaller learning rate, while training the output layer from scratch can use a larger learning rate. 일반적으로 미세 조정 매개변수는 더 작은 학습률을 사용하는 반면 출력 계층을 처음부터 훈련하면 더 큰 학습률을 사용할 수 있습니다.
14.2.4.Exercises
Keep increasing the learning rate offinetune_net. How does the accuracy of the model change?
Further adjust hyperparameters offinetune_netandscratch_netin the comparative experiment. Do they still differ in accuracy?
Set the parameters before the output layer offinetune_netto those of the source model and donotupdate them during training. How does the accuracy of the model change? You can use the following code.
for param in finetune_net.parameters():
param.requires_grad = False
4. In fact, there is a “hotdog” class in theImageNetdataset. Its corresponding weight parameter in the output layer can be obtained via the following code. How can we leverage this weight parameter?
InSection 8.1, we mentioned that large datasets are a prerequisitefor the success of deep neural networks in various applications.Image augmentationgenerates similar but distinct training examples after a series of random changes to the training images, thereby expanding the size of the training set. Alternatively, image augmentation can be motivated by the fact that random tweaks of training examples allow models to rely less on certain attributes, thereby improving their generalization ability. For example, we can crop an image in different ways to make the object of interest appear in different positions, thereby reducing the dependence of a model on the position of the object. We can also adjust factors such as brightness and color to reduce a model’s sensitivity to color. It is probably true that image augmentation was indispensable for the success of AlexNet at that time. In this section we will discuss this widely used technique in computer vision.
섹션 8.1에서 대규모 데이터 세트가 다양한 애플리케이션에서 심층 신경망의 성공을 위한 전제 조건이라고 언급했습니다. 이미지 확대는 트레이닝 이미지에 대한 일련의 무작위 변경 후에 유사하지만 별개의 트레이닝 예제를 생성하여 트레이닝 세트의 크기를 확장합니다. 또는 훈련 예제를 임의로 조정하면 모델이 특정 속성에 덜 의존하게 되므로 일반화 능력이 향상된다는 사실에 의해 이미지 확대가 동기가 될 수 있습니다. 예를 들어 관심 대상이 다른 위치에 나타나도록 다양한 방법으로 이미지를 잘라 대상 위치에 대한 모델의 의존성을 줄일 수 있습니다. 밝기 및 색상과 같은 요소를 조정하여 색상에 대한 모델의 민감도를 줄일 수도 있습니다. 당시 AlexNet의 성공을 위해 이미지 확대가 필수 불가결한 것은 아마도 사실일 것입니다. 이 섹션에서는 컴퓨터 비전에서 널리 사용되는 이 기술에 대해 설명합니다.
Image Augmentation이란?
Image augmentation refers to the process of applying various transformations to images in order to create new variations of the original images. This technique is commonly used in machine learning and computer vision tasks, especially in training deep learning models for image recognition, object detection, and other tasks. The goal of image augmentation is to increase the diversity and variability of the training dataset, which can lead to improved model generalization and performance on unseen data.
이미지 증강은 원본 이미지에 다양한 변환을 적용하여 새로운 변형된 이미지를 생성하는 과정을 말합니다. 이 기술은 주로 기계 학습과 컴퓨터 비전 작업에서 사용되며, 특히 이미지 인식, 물체 감지 및 기타 작업에 대한 딥 러닝 모델을 훈련할 때 많이 활용됩니다. 이미지 증강의 목표는 훈련 데이터셋의 다양성과 가변성을 증가시켜 모델의 일반화 성능과 새로운 데이터에서의 성능을 향상시키는 것입니다.
Image augmentation techniques involve making small, controlled changes to the images while preserving their semantic content. Some common image augmentation techniques include:
이미지 증강 기법은 이미지의 시맨틱 콘텐츠를 보존하면서 작은 제어된 변화를 가하는 것을 포함합니다. 일반적인 이미지 증강 기술로는 다음과 같은 것들이 있습니다:
Horizontal and Vertical Flips: Mirroring the image horizontally or vertically to create variations. 수평 및 수직 뒤집기: 이미지를 수평 또는 수직으로 뒤집어서 변형을 만듭니다.
Rotation: Rotating the image by a certain degree. 회전: 이미지를 일정한 각도로 회전합니다.
Zoom: Enlarging or shrinking the image slightly. 확대 및 축소: 이미지를 약간 확대하거나 축소합니다.
Brightness and Contrast Adjustment: Changing the brightness and contrast levels of the image. 밝기 및 대비 조절: 이미지의 밝기와 대비 수준을 조정합니다.
Color Jittering: Applying small color changes to the image. 색상 조절: 이미지에 작은 색상 변화를 적용합니다.
Noise Addition: Adding small amounts of noise to the image. 노이즈 추가: 이미지에 작은 양의 노이즈를 추가합니다.
Random Cropping: Cropping a random portion of the image. 임의의 자르기: 이미지의 임의 부분을 자릅니다.
Elastic Transformations: Applying elastic deformations to the image. 탄성 변형: 이미지에 탄성 변형을 적용합니다.
These transformations help the model learn to be invariant to small changes in the input data, making it more robust and accurate when applied to real-world data.
이러한 변환은 모델이 입력 데이터의 작은 변화에 불변하게 학습하도록 도와줍니다. 이로써 모델은 실제 세계 데이터에 적용할 때 더 견고하고 정확하게 작동할 수 있게 됩니다.
In the context of deep learning and neural networks, image augmentation is often used during the training process to prevent overfitting, improve model generalization, and enhance the model's ability to handle various conditions and scenarios.
딥 러닝과 신경망의 맥락에서 이미지 증강image augmentation은 종종 훈련 과정 중에 사용되어 과적합을 방지하고 모델의 일반화 성능을 개선하며 다양한 조건과 시나리오를 처리할 수 있는 능력을 향상시킵니다.
%matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
14.1.1.Common Image Augmentation Methods
In our investigation of common image augmentation methods, we will use the following400×500image an example.
위 코드는 주피터 노트북에서 사용되는 코드로, 주어진 이미지 파일을 열어서 화면에 보여주는 예제입니다. 코드를 한 줄씩 살펴보겠습니다:
%matplotlib inline: 이 라인은 주피터 노트북에서 그래프나 이미지 등을 인라인으로 표시하기 위한 명령입니다. 이를 통해 그래프나 이미지를 코드 셀 아래에 바로 표시할 수 있습니다.
import torch: 파이토치 라이브러리를 가져옵니다.
import torchvision: 파이토치의 torchvision 패키지를 가져옵니다. torchvision은 이미지 데이터셋 및 변환을 다루는 라이브러리입니다.
from torch import nn: 파이토치의 nn 모듈에서 nn을 가져옵니다. nn은 신경망 모델을 구축하는 데 사용되는 모듈들을 포함하고 있습니다.
from d2l import torch as d2l: d2l 라이브러리에서 torch 모듈을 가져와 d2l이라는 이름으로 사용합니다.
d2l.set_figsize(): 그래프의 크기를 설정하는 d2l 라이브러리의 함수를 호출합니다.
img = d2l.Image.open('../img/cat1.jpg'): d2l 라이브러리의 Image 모듈을 사용하여 '../img/cat1.jpg' 경로에 있는 이미지 파일을 엽니다. img 변수에 이미지 객체가 저장됩니다.
d2l.plt.imshow(img): d2l 라이브러리의 plt 모듈을 사용하여 이미지를 표시합니다. imshow 함수를 호출하여 img를 표시하고, ;를 사용하여 출력 결과를 숨깁니다.
위 코드는 이미지 파일 '../img/cat1.jpg'를 열어서 주피터 노트북에서 화면에 표시하는 예제입니다. 이를 실행하면 해당 경로의 이미지가 출력되게 됩니다.
Most image augmentation methods have a certain degree of randomness. To make it easier for us to observe the effect of image augmentation, next we define an auxiliary functionapply. This function runs the image augmentation methodaugmultiple times on the input imageimgand shows all the results.
대부분의 이미지 확대 image augmentation 방법에는 어느 정도의 무작위성이 있습니다. 이미지 확대 image augmentation 효과를 더 쉽게 관찰할 수 있도록 다음으로 보조 함수 적용을 정의합니다. 이 함수는 입력 이미지 img에서 이미지 확대 image augmentation 방법 aug를 여러 번 실행하고 모든 결과를 표시합니다.
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):
Y = [aug(img) for _ in range(num_rows * num_cols)]
d2l.show_images(Y, num_rows, num_cols, scale=scale)
위 코드는 이미지 변환 (Augmentation) 함수를 적용하여 변환된 이미지들을 그리드 형태로 표시하는 함수를 정의한 것입니다. 코드를 한 줄씩 살펴보겠습니다:
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):: apply라는 함수를 정의합니다. 이 함수는 세 개의 인자를 받습니다. 첫 번째 인자 img는 입력 이미지입니다. 두 번째 인자 aug는 이미지 변환 함수를 나타냅니다. num_rows와 num_cols는 그리드에 표시할 행과 열의 개수를 지정하며, scale은 이미지의 크기를 조절하는 인자입니다.
Y = [aug(img) for _ in range(num_rows * num_cols)]: aug 함수를 num_rows * num_cols번 반복하여 변환된 이미지들을 리스트 Y에 저장합니다. 각 반복마다 aug(img)를 호출하여 이미지를 변환합니다.
d2l.show_images(Y, num_rows, num_cols, scale=scale): 변환된 이미지 리스트 Y를 num_rows 행과 num_cols 열로 나타내는 그리드 형태로 표시합니다. 이미지의 크기는 scale 인자를 사용하여 조절합니다.
즉, 위 함수 apply는 입력 이미지를 주어진 변환 함수로 여러 번 변환하여 그리드 형태로 출력하는 역할을 수행합니다. 이를 통해 이미지 변환의 효과를 시각적으로 확인할 수 있습니다.
14.1.1.1.Flipping and Cropping
Flipping the image left and right usually does not change the category of the object. This is one of the earliest and most widely used methods of image augmentation. Next, we use thetransformsmodule to create theRandomHorizontalFlipinstance, which flips an image left and right with a 50% chance.
이미지를 좌우로 뒤집는 것은 일반적으로 개체의 범주를 변경하지 않습니다. 이것은 이미지 확대의 가장 초기이자 가장 널리 사용되는 방법 중 하나입니다. 다음으로 변환transforms 모듈을 사용하여 이미지를 50%의 확률로 좌우로 뒤집는 RandomHorizontalFlip 인스턴스를 만듭니다.
위 코드는 이미지 변환 함수를 적용하여 입력 이미지를 수평으로 뒤집은 후 변환된 이미지들을 그리드 형태로 표시하는 작업을 수행합니다. 코드를 한 줄씩 살펴보겠습니다:
apply(img, torchvision.transforms.RandomHorizontalFlip()): apply 함수를 호출하여 입력 이미지 img에 torchvision.transforms.RandomHorizontalFlip() 변환 함수를 적용합니다. 이 변환 함수는 입력 이미지를 무작위로 수평으로 뒤집습니다. 즉, 이미지의 왼쪽과 오른쪽이 뒤바뀝니다.
위 코드는 apply 함수를 사용하여 입력 이미지를 수평으로 뒤집은 후 변환된 이미지들을 그리드 형태로 표시하는 작업을 수행합니다. 이를 통해 이미지 뒤집기 변환의 효과를 시각적으로 확인할 수 있습니다.
Flipping up and down is not as common as flipping left and right. But at least for this example image, flipping up and down does not hinder recognition. Next, we create aRandomVerticalFlipinstance to flip an image up and down with a 50% chance.
위아래로 뒤집는 것은 좌우로 뒤집는 것만큼 일반적이지 않습니다. 그러나 적어도 이 예제 이미지의 경우 위아래로 뒤집는 것이 인식을 방해하지 않습니다. 다음으로 RandomVerticalFlip 인스턴스를 생성하여 50% 확률로 이미지를 위아래로 뒤집습니다.
위 코드는 입력 이미지에 수직으로 무작위로 뒤집기 변환을 적용하고, 이를 그리드 형태로 시각화하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
apply(img, torchvision.transforms.RandomVerticalFlip()): apply 함수를 호출하여 입력 이미지 img에 torchvision.transforms.RandomVerticalFlip() 변환 함수를 적용합니다. 이 변환 함수는 입력 이미지를 무작위로 수직으로 뒤집습니다. 즉, 이미지의 위쪽과 아래쪽이 뒤바뀝니다.
이 코드는 입력 이미지를 수직으로 뒤집은 후 변환된 이미지들을 그리드 형태로 표시합니다. 이를 통해 이미지 뒤집기 변환의 효과를 시각적으로 확인할 수 있습니다.
In the example image we used, the cat is in the middle of the image, but this may not be the case in general. InSection 7.5, we explained that the pooling layer can reduce the sensitivity of a convolutional layer to the target position. In addition, we can also randomly crop the image to make objects appear in different positions in the image at different scales, which can also reduce the sensitivity of a model to the target position.
우리가 사용한 예제 이미지에서 고양이는 이미지 중앙에 있지만 일반적으로 그렇지 않을 수 있습니다. 7.5절에서 풀링 레이어가 목표 위치에 대한 컨볼루션 레이어의 민감도를 감소시킬 수 있다고 설명했습니다. 또한 이미지를 무작위로 잘라 개체가 이미지의 다른 위치에 다른 배율로 나타나도록 할 수도 있습니다. 이렇게 하면 대상 위치에 대한 모델의 민감도를 줄일 수도 있습니다.
In the code below, we randomly crop an area with an area of10%∼100%of the original area each time, and the ratio of width to height of this area is randomly selected from0.5∼2. Then, the width and height of the region are both scaled to 200 pixels. Unless otherwise specified, the random number betweenaandbin this section refers to a continuous value obtained by random and uniform sampling from the interval[a,b].
아래 코드에서는 매번 원래 영역의 10%~100% 영역을 무작위로 자르고 이 영역의 너비와 높이의 비율을 0.5~2 중에서 무작위로 선택합니다. 그런 다음 영역의 너비와 높이가 모두 200픽셀로 조정됩니다. 달리 명시하지 않는 한, 이 섹션에서 a와 b 사이의 난수는 간격 [a,b]에서 무작위로 균일하게 샘플링하여 얻은 연속 값을 나타냅니다.
위 코드는 입력 이미지에 무작위 크기와 종횡비로 자르기(resize crop) 변환을 적용하고, 이를 그리드 형태로 시각화하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
shape_aug = torchvision.transforms.RandomResizedCrop((200, 200), scale=(0.1, 1), ratio=(0.5, 2)): torchvision.transforms.RandomResizedCrop() 변환 함수를 사용하여 shape_aug라는 변수에 무작위 크기로 자르기 변환을 생성합니다. 이 함수는 입력 이미지를 주어진 크기로 자르고, 무작위로 크기와 종횡비를 변화시킵니다. 여기서 (200, 200)은 자르고자 하는 크기를 의미하며, scale=(0.1, 1)은 무작위로 선택할 크기의 범위를 나타내고, ratio=(0.5, 2)는 무작위로 선택할 종횡비의 범위를 나타냅니다.
apply(img, shape_aug): apply 함수를 호출하여 입력 이미지 img에 shape_aug로 정의된 변환 함수를 적용합니다. 이를 통해 입력 이미지에 무작위 크기와 종횡비로 자르기 변환을 적용한 이미지들을 그리드 형태로 표시합니다.
이 코드는 이미지를 무작위 크기와 종횡비로 자르는 변환을 적용하여 이미지의 다양한 부분을 추출하고 시각화하는 역할을 합니다.
14.1.1.2.Changing Colors
Another augmentation method is changing colors. We can change four aspects of the image color: brightness, contrast, saturation, and hue. In the example below, we randomly change the brightness of the image to a value between 50% (1−0.5) and 150% (1+0.5) of the original image.
또 다른 증강 방법은 색상을 변경하는 것입니다. 이미지 색상의 네 가지 측면인 밝기, 대비, 채도 및 색조를 변경할 수 있습니다. 아래 예에서는 이미지의 밝기를 원본 이미지의 50%(1−0.5)와 150%(1+0.5) 사이의 값으로 무작위로 변경합니다.
위 코드는 입력 이미지에 색상 조정 변환을 적용하고, 이를 시각화하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
torchvision.transforms.ColorJitter(brightness=0.5, contrast=0, saturation=0, hue=0): torchvision.transforms.ColorJitter() 변환 함수를 사용하여 색상 조정 변환을 생성합니다. 이 함수는 입력 이미지의 색상을 조정하여 다양한 효과를 줄 수 있습니다. 여기서 brightness, contrast, saturation, hue 매개변수를 조정하여 각각 밝기, 대비, 채도, 색조를 조정할 수 있습니다. 각 매개변수의 값이 0보다 크면 변환이 적용됩니다.
apply(img, torchvision.transforms.ColorJitter(brightness=0.5, contrast=0, saturation=0, hue=0)): apply 함수를 호출하여 입력 이미지 img에 색상 조정 변환 함수를 적용합니다. 이를 통해 입력 이미지에 다양한 색상 조정 효과를 적용한 이미지들을 그리드 형태로 표시합니다.
이 코드는 이미지의 색상을 다양하게 변화시켜 시각화하는 역할을 합니다. 여기서는 밝기를 조정하고 대비, 채도, 색조는 조정하지 않습니다.
Similarly, we can randomly change the hue of the image.
위 코드는 입력 이미지에 대한 torchvision.transforms.ColorJitter() 변환을 사용하여 색상 조정 변환을 적용하고, 이를 시각화하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
torchvision.transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0.5): torchvision.transforms.ColorJitter() 변환 함수를 사용하여 색상 조정 변환을 생성합니다. 여기서 brightness, contrast, saturation 매개변수를 0으로 설정하고, hue 매개변수를 0.5로 설정하여 색조에 대한 조정만 적용될 수 있도록 합니다. hue 값이 0.5이므로 이미지의 색조가 최대 ±0.5만큼 변경됩니다.
apply(img, torchvision.transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0.5)): apply 함수를 호출하여 입력 이미지 img에 색상 조정 변환 함수를 적용합니다. 이를 통해 입력 이미지에 다양한 색조 조정 효과를 적용한 이미지들을 그리드 형태로 표시합니다.
이 코드는 이미지의 색조를 다양하게 변화시켜 시각화하는 역할을 합니다.
We can also create aRandomColorJitterinstance and set how to randomly change thebrightness,contrast,saturation, andhueof the image at the same time.
또한 RandomColorJitter 인스턴스를 생성하고 동시에 이미지의 밝기, 대비, 채도 및 색조를 무작위로 변경하는 방법을 설정할 수 있습니다.
위 코드는 torchvision.transforms.ColorJitter() 변환을 사용하여 입력 이미지에 다양한 색상 조정을 적용하고, 이를 시각화하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
torchvision.transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5): torchvision.transforms.ColorJitter() 변환 함수를 사용하여 색상 조정 변환을 생성합니다. 여기서 brightness, contrast, saturation 매개변수를 0.5로 설정하고, hue 매개변수를 0.5로 설정하여 밝기, 대비, 채도, 색조에 대한 조정을 적용할 수 있도록 합니다. 이렇게 설정하면 입력 이미지의 색상이 다양하게 변화됩니다.
apply(img, color_aug): apply 함수를 호출하여 입력 이미지 img에 색상 조정 변환 함수 color_aug를 적용합니다. 이를 통해 입력 이미지에 다양한 색상 조정 효과를 적용한 이미지들을 그리드 형태로 표시합니다.
이 코드는 입력 이미지의 밝기, 대비, 채도, 색조를 다양하게 변화시켜 시각화하는 역할을 합니다.
In practice, we will combine multiple image augmentation methods. For example, we can combine the different image augmentation methods defined above and apply them to each image via aComposeinstance.
실제로는 여러 이미지 확대 방법을 결합합니다. 예를 들어 위에서 정의한 다양한 이미지 확대 방법을 결합하고 Compose 인스턴스를 통해 각 이미지에 적용할 수 있습니다.
all_images = torchvision.datasets.CIFAR10(train=True, root="../data",
download=True)
d2l.show_images([all_images[i][0] for i in range(32)], 4, 8, scale=0.8);
위 코드는 CIFAR-10 데이터셋에서 이미지를 가져와 시각화하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
torchvision.datasets.CIFAR10(train=True, root="../data", download=True): CIFAR-10 데이터셋을 로드합니다. train 매개변수를 True로 설정하여 학습 데이터셋을 로드하며, root 매개변수에 데이터의 저장 경로를 지정합니다. download 매개변수를 True로 설정하면 데이터셋을 다운로드합니다.
[all_images[i][0] for i in range(32)]: CIFAR-10 데이터셋에서 처음부터 32개의 이미지를 가져와 리스트로 만듭니다. 각 이미지 데이터는 (이미지, 레이블) 형태로 저장되어 있으며, 여기서는 이미지 데이터만을 선택합니다.
d2l.show_images([...], 4, 8, scale=0.8): d2l.show_images() 함수를 사용하여 이미지 리스트를 그리드 형태로 시각화합니다. 4는 그리드의 행 수, 8은 그리드의 열 수를 나타냅니다. scale 매개변수는 이미지 크기의 스케일을 조절하는 역할을 합니다.
이 코드는 CIFAR-10 데이터셋에서 가져온 처음 32개의 이미지를 4x8 그리드로 시각화하여 보여줍니다.
In order to obtain definitive results during prediction, we usually only apply image augmentation to training examples, and do not use image augmentation with random operations during prediction. Here we only use the simplest random left-right flipping method. In addition, we use aToTensorinstance to convert a minibatch of images into the format required by the deep learning framework, i.e., 32-bit floating point numbers between 0 and 1 with the shape of (batch size, number of channels, height, width).
예측 중에 결정적인 결과를 얻기 위해 일반적으로 훈련 예제에만 이미지 확대를 적용하고 예측 중에 임의 작업으로 이미지 확대를 사용하지 않습니다. 여기서는 가장 간단한 임의의 좌우 뒤집기 방법만 사용합니다. 또한 ToTensor 인스턴스를 사용하여 이미지의 미니 배치를 딥 러닝 프레임워크에 필요한 형식, 즉 (배치 크기, 채널 수, 높이, 너비).
위 코드는 데이터 증강을 위한 데이터 변환 함수들을 정의하는 작업을 수행합니다. 코드를 단계별로 설명하겠습니다:
train_augs: 학습 데이터에 적용할 데이터 증강 변환 함수들을 조합한 객체를 생성합니다. torchvision.transforms.Compose() 함수를 사용하여 여러 변환 함수들을 순차적으로 적용할 수 있습니다.
torchvision.transforms.RandomHorizontalFlip(): 무작위로 이미지를 수평으로 뒤집는 데이터 증강을 수행합니다. 이는 이미지를 좌우로 반전시키는 효과를 줍니다.
torchvision.transforms.ToTensor(): 이미지를 텐서 형태로 변환합니다. 이 작업은 이미지 데이터를 신경망에 입력하기 위해 필요한 전처리 단계 중 하나입니다.
test_augs: 테스트 데이터에 적용할 데이터 변환 함수들을 조합한 객체를 생성합니다. 여기서는 테스트 데이터에는 이미지 뒤집기 등의 변환을 적용하지 않고, 단순히 이미지를 텐서로 변환하는 ToTensor() 변환만 적용합니다.
이렇게 정의된 train_augs와 test_augs 객체는 학습 및 테스트 데이터에 데이터 증강 및 전처리를 적용할 때 사용됩니다. 학습 데이터에는 수평 뒤집기와 이미지를 텐서로 변환하는 작업이 수행되며, 테스트 데이터에는 이미지를 텐서로 변환하는 작업만 수행됩니다.
Next, we define an auxiliary function to facilitate reading the image and applying image augmentation. Thetransformargument provided by PyTorch’s dataset applies augmentation to transform the images. For a detailed introduction toDataLoader, please refer toSection 4.2.
다음으로 이미지 읽기 및 이미지 확대 적용을 용이하게 하는 보조 기능을 정의합니다. PyTorch의 데이터 세트에서 제공하는 변환 인수는 증강을 적용하여 이미지를 변환합니다. DataLoader에 대한 자세한 소개는 섹션 4.2를 참조하십시오.
위 코드는 CIFAR-10 데이터셋을 로드하는 함수인 load_cifar10를 정의하는 부분입니다. 코드를 단계별로 설명하겠습니다:
is_train: 학습 데이터인지 테스트 데이터인지를 나타내는 인자입니다. True이면 학습 데이터를, False이면 테스트 데이터를 로드합니다.
augs: 데이터 증강 및 전처리를 적용하기 위한 데이터 변환 함수를 받는 인자입니다. 앞서 정의한 train_augs 또는 test_augs와 같은 변환 함수 객체를 여기에 전달합니다.
batch_size: 배치 크기를 나타내는 인자입니다. 데이터를 미니배치로 나눠서 로드할 때 한 번에 로드되는 데이터 샘플의 개수입니다.
torchvision.datasets.CIFAR10(): CIFAR-10 데이터셋을 로드하는 함수입니다. 해당 데이터셋은 지정된 경로에서 이미 다운로드된 경우 로드하며, 그렇지 않은 경우 다운로드합니다. 데이터셋은 CIFAR-10의 학습 데이터 또는 테스트 데이터 중 하나를 선택하여 로드합니다.
transform: 데이터 변환 함수 객체를 전달합니다. 이를 통해 데이터 증강 및 전처리 작업을 수행합니다.
torch.utils.data.DataLoader(): 데이터셋을 미니배치 형태로 로드하기 위한 데이터 로더 객체를 생성합니다. 배치 크기와 데이터 순서를 지정하여 데이터를 로드하며, 필요한 경우 데이터 로드를 병렬화합니다.
d2l.get_dataloader_workers(): 데이터 로더를 병렬화할 때 사용할 워커의 수를 반환하는 함수입니다. 데이터 로드 성능을 향상시키기 위해 병렬 처리에 사용됩니다.
반환값: 로드된 데이터셋을 배치 단위로 로드하는 데이터 로더 객체를 반환합니다. 이를 통해 학습 또는 테스트 데이터를 미니배치 형태로 반복해서 사용할 수 있습니다.
14.1.2.1.Multi-GPU Training
#@save
def train_batch_ch13(net, X, y, loss, trainer, devices):
"""Train for a minibatch with multiple GPUs (defined in Chapter 13)."""
if isinstance(X, list):
# Required for BERT fine-tuning (to be covered later)
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
#@save
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices=d2l.try_all_gpus()):
"""Train a model with multiple GPUs (defined in Chapter 13)."""
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(
net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')
위 코드는 다중 GPU를 활용하여 모델을 학습하는 함수인 train_ch13와 해당 함수 내에서 호출되는 train_batch_ch13 함수를 정의하는 부분입니다. 코드를 단계별로 설명하겠습니다:
train_batch_ch13(net, X, y, loss, trainer, devices): 다중 GPU로 미니배치 학습을 수행하는 함수입니다. 인자로는 모델 net, 입력 데이터 X, 레이블 데이터 y, 손실 함수 loss, 옵티마이저 trainer, 그리고 사용할 GPU 디바이스들의 리스트 devices가 전달됩니다. 이 함수는 미니배치를 처리하고, 손실 계산, 역전파, 가중치 갱신 등의 학습 과정을 수행합니다.
train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices=d2l.try_all_gpus()): 다중 GPU로 모델을 학습하는 함수입니다. 인자로는 모델 net, 학습 데이터 로더 train_iter, 테스트 데이터 로더 test_iter, 손실 함수 loss, 옵티마이저 trainer, 학습 에포크 수 num_epochs, 그리고 사용할 GPU 디바이스들의 리스트 devices가 전달됩니다. 이 함수는 각 에포크마다 학습과 평가 과정을 반복하여 모델을 학습하고 성능을 평가합니다.
nn.DataParallel(net, device_ids=devices).to(devices[0]): DataParallel을 사용하여 모델 net을 여러 GPU에 병렬화하여 할당하는 과정입니다. 병렬화된 모델은 devices[0]에 할당됩니다.
d2l.Accumulator(4): 성능 메트릭을 누적하기 위한 Accumulator 객체를 생성합니다. 누적할 값은 손실, 정확도, 데이터 샘플 수, 예측 수로 총 4개입니다.
timer.start() 및 timer.stop(): 각 미니배치 학습 시간을 측정하기 위한 타이머를 시작하고 중지합니다.
d2l.evaluate_accuracy_gpu(net, test_iter): 테스트 데이터에 대한 정확도를 GPU를 이용하여 평가하는 함수입니다.
animator.add(...): 학습 과정 및 성능 변화를 시각화하는 Animator 객체에 정보를 추가합니다.
마지막에는 각 에포크마다 학습 및 평가 결과를 출력하고, 처리한 예제 수에 대한 처리 속도도 출력합니다.
이러한 함수를 사용하면 다중 GPU를 활용하여 모델을 학습하고 성능을 평가할 수 있습니다.
Now we can define thetrain_with_data_augfunction to train the model with image augmentation. This function gets all available GPUs, uses Adam as the optimization algorithm, applies image augmentation to the training dataset, and finally calls thetrain_ch13function just defined to train and evaluate the model.
이제 train_with_data_aug 함수를 정의하여 이미지 확대image augmentation로 모델을 훈련할 수 있습니다. 이 함수는 사용 가능한 모든 GPU를 가져오고 Adam을 최적화 알고리즘으로 사용하며 훈련 데이터 세트에 이미지 증대를 적용하고 마지막으로 방금 정의한 train_ch13 함수를 호출하여 모델을 훈련하고 평가합니다.
위 코드는 데이터 증강을 적용하여 ResNet-18 모델을 학습하는 과정을 정의하는 부분입니다. 코드를 단계별로 설명하겠습니다:
batch_size, devices, net: 미니배치 크기 batch_size, 사용 가능한 GPU 디바이스 리스트 devices, 그리고 d2l.resnet18 함수를 사용하여 클래스 수 10개, 입력 채널 3개인 ResNet-18 모델 net을 생성합니다.
net.apply(d2l.init_cnn): 모델의 가중치 초기화를 위해 d2l.init_cnn 함수를 적용합니다. 이 함수는 모델 내부의 합성곱 레이어의 가중치를 초기화합니다.
train_with_data_aug(train_augs, test_augs, net, lr=0.001): 데이터 증강을 적용하여 모델을 학습하는 함수입니다. 인자로는 학습 데이터 증강 변환 train_augs, 테스트 데이터 증강 변환 test_augs, 모델 net, 학습률 lr이 전달됩니다. 이 함수는 데이터 로더를 생성하고, 손실 함수, 옵티마이저 등을 설정하여 모델을 학습합니다.
train_iter = load_cifar10(True, train_augs, batch_size): 학습 데이터 로더를 생성합니다. load_cifar10 함수를 사용하여 CIFAR-10 학습 데이터에 데이터 증강을 적용한 후 미니배치 크기 batch_size로 분할합니다.
test_iter = load_cifar10(False, test_augs, batch_size): 테스트 데이터 로더를 생성합니다. 학습 데이터와 마찬가지로 테스트 데이터에 데이터 증강을 적용하고 미니배치 크기 batch_size로 분할합니다.
loss = nn.CrossEntropyLoss(reduction="none"): 손실 함수로 교차 엔트로피 손실 함수를 사용하며, reduction 인자를 "none"으로 설정하여 각 샘플에 대한 손실 값을 반환합니다.
trainer = torch.optim.Adam(net.parameters(), lr=lr): Adam 옵티마이저를 생성하고, 모델의 파라미터를 최적화 대상으로 설정합니다. 학습률은 lr로 설정됩니다.
net(next(iter(train_iter))[0]): 모델의 가중치를 초기화하고, 모델의 출력을 계산하여 GPU 메모리에 모델을 적재합니다.
train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices): 다중 GPU를 활용하여 모델을 학습하는 train_ch13 함수를 호출하여 모델을 학습하고 성능을 평가합니다. 학습과 평가는 각각 10 에포크 동안 수행됩니다.
이러한 과정을 통해 데이터 증강을 적용하고, ResNet-18 모델을 학습하며 성능을 평가하는 과정이 구현되어 있습니다.
Let’s train the model using image augmentation based on random left-right flipping.
무작위 좌우 반전을 기반으로 한 이미지 확대를 사용하여 모델을 훈련시켜 봅시다.
train_with_data_aug(train_augs, test_augs, net)
14.1.3.Summary
Image augmentation generates random images based on existing training data to improve the generalization ability of models.
이미지 증대는 모델의 일반화 능력을 향상시키기 위해 기존 학습 데이터를 기반으로 임의의 이미지를 생성합니다.
In order to obtain definitive results during prediction, we usually only apply image augmentation to training examples, and do not use image augmentation with random operations during prediction.
예측 중에 결정적인 결과를 얻기 위해 일반적으로 훈련 예제에만 이미지 확대를 적용하고 예측 중에 임의 작업으로 이미지 확대를 사용하지 않습니다.
Deep learning frameworks provide many different image augmentation methods, which can be applied simultaneously.
딥 러닝 프레임워크는 동시에 적용할 수 있는 다양한 이미지 확대 image augmentation 방법을 제공합니다.
14.1.4.Exercises
Train the model without using image augmentation:train_with_data_aug(test_augs,test_augs). Compare training and testing accuracy when using and not using image augmentation. Can this comparative experiment support the argument that image augmentation can mitigate overfitting? Why?
Combine multiple different image augmentation methods in model training on the CIFAR-10 dataset. Does it improve test accuracy?
Refer to the online documentation of the deep learning framework. What other image augmentation methods does it also provide?
Whether it is medical diagnosis, self-driving vehicles, camera monitoring, or smart filters, many applications in the field of computer vision are closely related to our current and future lives. In recent years, deep learning has been the transformative power for advancing the performance of computer vision systems. It can be said that the most advanced computer vision applications are almost inseparable from deep learning. In view of this, this chapter will focus on the field of computer vision, and investigate methods and applications that have recently been influential in academia and industry.
의료 진단, 자율 주행 차량, 카메라 모니터링 또는 스마트 필터 등 컴퓨터 비전 분야의 많은 응용 프로그램은 현재와 미래의 삶과 밀접한 관련이 있습니다. 최근 몇 년 동안 딥 러닝은 컴퓨터 비전 시스템의 성능을 향상시키는 변혁적인 힘이었습니다. 가장 진보된 컴퓨터 비전 응용 프로그램은 딥 러닝과 거의 분리할 수 없다고 말할 수 있습니다. 이를 고려하여 이 장에서는 컴퓨터 비전 분야에 초점을 맞추고 최근 학계와 산업계에 영향을 미치고 있는 방법과 응용을 조사합니다.
InSection 7andSection 8, we studied various convolutional neural networks that are commonly used in computer vision, and applied them to simple image classification tasks. At the beginning of this chapter, we will describe two methods that may improve model generalization, namelyimage augmentationandfine-tuning, and apply them to image classification. Since deep neural networks can effectively represent images in multiple levels, such layerwise representations have been successfully used in various computer vision tasks such asobject detection,semantic segmentation, andstyle transfer. Following the key idea of leveraging layerwise representations in computer vision, we will begin with major components and techniques for object detection. Next, we will show how to usefully convolutional networksfor semantic segmentation of images. Then we will explain how to use style transfer techniques to generate images like the cover of this book. In the end, we conclude this chapter by applying the materials of this chapter and several previous chapters on two popular computer vision benchmark datasets.
7절과 8절에서는 컴퓨터 비전에서 흔히 사용되는 다양한 컨볼루션 신경망을 연구하고 이를 간단한 이미지 분류 작업에 적용하였다. 이 장의 시작 부분에서 모델 일반화를 개선할 수 있는 두 가지 방법, 즉 이미지 확대 및 미세 조정을 설명하고 이미지 분류에 적용할 것입니다. 심층 신경망은 여러 수준에서 이미지를 효과적으로 표현할 수 있기 때문에 이러한 레이어별 표현은 개체 감지, 의미론적 분할 및 스타일 전송과 같은 다양한 컴퓨터 비전 작업에서 성공적으로 사용되었습니다. 컴퓨터 비전에서 계층별 표현을 활용하는 핵심 아이디어에 따라 물체 감지를 위한 주요 구성 요소와 기술부터 시작하겠습니다. 다음으로 이미지의 시맨틱 분할을 위해 완전 컨벌루션 네트워크를 사용하는 방법을 보여줍니다. 그런 다음 스타일 변환 기술을 사용하여 이 책의 표지와 같은 이미지를 생성하는 방법을 설명합니다. 마지막으로 이 장의 자료와 두 가지 인기 있는 컴퓨터 비전 벤치마크 데이터 세트에 대한 이전 장의 여러 장을 적용하여 이 장을 마무리합니다.
So far in our image classification and machine translation experiments, models were trained on datasets with input-output examplesfrom scratchto perform specific tasks. For example, a Transformer was trained with English-French pairs (Section 11.7) so that this model can translate input English text into French. As a result, each model becomes aspecific expertthat is sensitive to even slight shift in data distribution (Section 4.7). For better generalized models, or even more competentgeneraliststhat can perform multiple tasks with or without adaptation,pretrainingmodels on large data has been increasingly common.
지금까지 이미지 분류 및 기계 번역 실험에서 모델은 특정 작업을 수행하기 위해 처음부터 입력-출력 예제가 있는 데이터 세트에 대해 훈련되었습니다. 예를 들어 Transformer는 이 모델이 입력 영어 텍스트를 프랑스어로 번역할 수 있도록 영어-프랑스어 쌍(섹션 11.7)으로 훈련되었습니다. 결과적으로 각 모델은 데이터 분포의 약간의 변화에도 민감한 특정 전문가가 됩니다(섹션 4.7). 더 나은 일반화 모델 또는 적응 여부에 관계없이 여러 작업을 수행할 수 있는 더 유능한 제너럴리스트를 위해 대용량 데이터에 대한 모델 사전 훈련이 점점 보편화되었습니다.
Given larger data for pretraining, the Transformer architecture performs better with an increased model size and training compute, demonstrating superiorscalingbehavior. Specifically, performance of Transformer-based language models scales as a power-law with the amount of model parameters, training tokens, and training compute(Kaplanet al., 2020). The scalability of Transformers is also evidenced by the significantly boosted performance from larger vision Transformers trained on larger data (discussed inSection 11.8). More recent success stories include Gato, ageneralistmodel that can play Atari, caption images, chat, and act as a robot(Reedet al., 2022). Gato is a single Transformer that scales well when pretrained on diverse modalities, including text, images, joint torques, and button presses. Notably, all such multi-modal data is serialized into a flat sequence of tokens, which can be processed akin to text tokens (Section 11.7) or image patches (Section 11.8) by Transformers.
사전 교육을 위한 더 큰 데이터가 주어지면 Transformer 아키텍처는 모델 크기와 교육 컴퓨팅이 증가하여 더 나은 성능을 발휘하여 우수한 확장 동작을 보여줍니다. 특히 Transformer 기반 언어 모델의 성능은 모델 매개변수, 교육 토큰 및 교육 컴퓨팅의 양에 따라 power-law으로 확장됩니다(Kaplan et al., 2020). Transformers의 확장성은 또한 더 큰 데이터에 대해 훈련된 더 큰 비전 Transformers의 성능이 크게 향상된 것으로 입증됩니다(11.8절에서 설명). 보다 최근의 성공 사례로는 Atari를 플레이하고, 이미지에 캡션을 달고, 채팅하고, 로봇 역할을 할 수 있는 일반 모델인 Gato가 있습니다(Reed et al., 2022). Gato는 텍스트, 이미지, 조인트 토크 및 버튼 누름을 비롯한 다양한 양식에 대해 사전 훈련되었을 때 잘 확장되는 단일 Transformer입니다. 특히 이러한 모든 다중 모달 데이터는 트랜스포머에 의해 텍스트 토큰(11.7절) 또는 이미지 패치(11.8절)와 유사하게 처리될 수 있는 토큰의 플랫 시퀀스로 직렬화됩니다.
Power-law 란?
The power-law, also known as a power-law distribution or scaling law, refers to a mathematical relationship between two quantities in which one quantity's value is proportional to a power of the other. In other words, a power-law distribution describes a relationship where the frequency of an event (or the occurrence of a value) decreases rapidly as the event becomes more frequent or the value becomes larger.
'Power-law', 또는 'power-law 분포' 또는 'scaling law'는 두 quantities 사이의 수학적 관계를 나타내며, 한 quantity의 값이 다른 quantity의 거듭제곱에 비례하는 관계를 의미합니다. 다시 말해, power-law 분포는 어떤 사건의 빈도(또는 값의 발생)가 해당 사건이 더 자주 발생하거나 값이 더 크면 빠르게 감소하는 관계를 설명합니다.
Mathematically, a power-law relationship can be expressed as:
수학적으로 power-law 관계는 다음과 같이 표현할 수 있습니다:
P(x)∝x−α
Here, P(x) represents the probability or frequency of the event or value x, and α is the exponent that determines the rate of decrease. A smaller value of α leads to a slower decrease, while a larger value of α leads to a faster decrease.
여기서 P(x)는 사건 또는 값 x의 확률 또는 빈도를 나타내며, α는 감소율을 결정하는 지수입니다. α 값이 작을수록 감소가 느리게 진행되며, α 값이 클수록 빠르게 감소합니다.
Power-law distributions are common in various natural, social, and economic systems. They are characterized by a few highly frequent events or values (often referred to as "hubs" or "outliers") and many less frequent events or values. This distribution is also known as a "long-tailed" distribution because the tail of the distribution extends over a wide range of values.
Power-law 분포는 자연, 사회, 경제 시스템에서 일반적으로 나타나며, 몇 개의 높은 빈도 사건 또는 값(일반적으로 "허브" 또는 "아웃라이어"로 불림)과 많은 낮은 빈도 사건 또는 값이 특징입니다. 이 분포는 종종 "긴 꼬리" 분포로 알려져 있습니다. 분포의 꼬리 부분이 넓은 범위의 값을 포함하기 때문입니다.
Examples of phenomena that exhibit power-law distributions include the distribution of income, city sizes, word frequencies in texts, earthquake magnitudes, and the number of links in online networks like the Internet. The study of power-law distributions is essential in understanding the behavior and dynamics of complex systems and networks.
수입 분포, 도시 규모, 텍스트에서의 단어 빈도, 지진 규모, 인터넷과 같은 온라인 네트워크의 링크 수 등 다양한 자연, 사회 및 경제 현상에서 power-law 분포가 나타납니다. power-law 분포의 연구는 복잡한 시스템과 네트워크의 동작과 역학을 이해하는 데 중요합니다.
Before compelling success of pretraining Transformers for multi-modal data, Transformers were extensively pretrained with a wealth of text. Originally proposed for machine translation, the Transformer architecture inFig. 11.7.1consists of an encoder for representing input sequences and a decoder for generating target sequences. Primarily, Transformers can be used in three different modes:encoder-only,encoder-decoder, anddecoder-only. To conclude this chapter, we will review these three modes and explain the scalability in pretraining Transformers.
multi-modal data에 대한 Transformers의 사전 교육이 성공하기 전에 Transformers는 풍부한 텍스트로 광범위하게 사전 교육을 받았습니다. 원래 기계 번역을 위해 제안된 그림 11.7.1의 Transformer 아키텍처는 입력 시퀀스를 나타내는 인코더와 대상 시퀀스를 생성하는 디코더로 구성됩니다. 기본적으로 트랜스포머는 encoder-only,encoder-decoder, anddecoder-only 의 세 가지 모드로 사용할 수 있습니다. 이 장을 마무리하기 위해 이 세 가지 모드를 검토하고 Transformer를 사전 훈련할 때의 확장성을 설명합니다.
Multi Modal 이란?
'Multi-modal'은 여러 가지 다른 형태, 유형 또는 모드가 함께 존재하는 상황이나 시스템을 나타내는 용어입니다. 이 용어는 다양한 정보나 자료 소스가 혼합되어 하나의 전체를 구성하는 경우를 가리킵니다. 다른 말로 하면, 다양한 모드나 형태가 복합적으로 존재하여 상호작용하거나 조합되는 상황을 말합니다.
예를 들어, 'multi-modal data'는 여러 유형의 데이터가 함께 존재하는 경우를 의미합니다. 이러한 데이터는 텍스트, 이미지, 음성 등 다양한 형식의 정보를 포함할 수 있습니다. 머신러닝이나 딥러닝 분야에서 'multi-modal learning'은 여러 종류의 데이터로부터 모델을 학습시키는 기술을 의미합니다. 이러한 방식으로 학습된 모델은 다양한 유형의 정보를 통합하여 더 풍부한 표현을 생성하거나 복잡한 문제를 해결하는 데 사용될 수 있습니다.
또한 'multi-modal'은 감각적인 정보나 경험의 다양성을 나타낼 때도 사용될 수 있습니다. 예를 들어, 'multi-modal perception'은 시각, 청각, 후각, 촉각 등 다양한 감각 정보를 통해 환경을 인식하는 능력을 의미합니다.
BERT란?
BERT, which stands for "Bidirectional Encoder Representations from Transformers," is a revolutionary pre-trained language model developed by Google AI (Google Research) in 2018. BERT has significantly advanced the field of natural language processing (NLP) and has had a profound impact on various NLP tasks.
BERT는 "Bidirectional Encoder Representations from Transformers"의 약자로, 2018년 Google AI(구글 연구소)에서 개발한 혁신적인 사전 훈련 언어 모델입니다. BERT는 자연어 처리(NLP) 분야를 혁신하며 다양한 NLP 작업에 깊은 영향을 미쳤습니다.
Here are some key features and concepts related to BERT:
다음은 BERT에 관련한 주요 기능과 개념입니다:
Transformer Architecture: BERT is built upon the Transformer architecture, which is a type of neural network architecture specifically designed for handling sequences of data, such as sentences or paragraphs. The Transformer architecture incorporates self-attention mechanisms that allow it to capture contextual relationships among words in a sentence.
트랜스포머 아키텍처: BERT는 트랜스포머 아키텍처를 기반으로 구축되었으며, 문장이나 단락과 같은 시퀀스 데이터를 처리하는 데 특화된 신경망 아키텍처입니다. 트랜스포머 아키텍처는 self-attention 메커니즘을 포함하며 문장 내 단어 간의 문맥 관계를 파악할 수 있습니다.
Bidirectional Context: One of the most important features of BERT is that it's bidirectional, meaning it reads text in both directions (left-to-right and right-to-left) during training. This allows the model to have a better understanding of the context in which a word appears.
양방향 문맥: BERT의 가장 중요한 특징 중 하나는 양방향입니다. 이는 모델이 학습 중에 텍스트를 양방향(왼쪽에서 오른쪽으로, 오른쪽에서 왼쪽으로)으로 읽는다는 것을 의미합니다. 이로써 모델은 단어가 문맥 내에서 어떻게 나타나는지에 대한 더 나은 이해를 갖게 됩니다.
Pre-training and Fine-tuning: BERT is pre-trained on a massive amount of text data using two unsupervised tasks: masked language modeling and next sentence prediction. In masked language modeling, random words in a sentence are masked, and the model is trained to predict those masked words. In next sentence prediction, the model learns to predict whether two sentences follow each other logically.
사전 훈련 및 세부 조정: BERT는 무언어 학습 작업 중 두 가지 비지도 작업인 마스크된 언어 모델링과 다음 문장 예측으로 대량의 텍스트 데이터에 사전 훈련됩니다. 마스크된 언어 모델링에서 문장 내의 무작위 단어가 마스크되고, 모델은 해당 마스크된 단어를 예측하도록 훈련됩니다. 다음 문장 예측에서는 두 문장이 논리적으로 이어지는지를 예측하는 방식으로 학습합니다.
Contextualized Word Representations: BERT generates contextualized word representations, which means that the representation of a word depends on its surrounding words in a sentence. This allows the model to capture various nuances and polysemy in language.
문맥화된 단어 표현: BERT는 문맥화된 단어 표현을 생성하며, 단어의 표현이 문장 내 주변 단어에 따라 다릅니다. 이를 통해 모델은 언어의 다양한 뉘앙스와 일어날 수 있는 다의성을 포착할 수 있습니다.
Transfer Learning: BERT's pre-trained model can be fine-tuned on specific downstream tasks with smaller amounts of task-specific data. This transfer learning approach has been shown to yield impressive results on a wide range of NLP tasks, such as text classification, named entity recognition, question answering, sentiment analysis, and more.
전이 학습: BERT의 사전 훈련된 모델은 작은 양의 과제 특화 데이터로 세부적인 다운스트림 작업에 대해 세밀하게 조정될 수 있습니다. 이러한 전이 학습 방식은 다양한 NLP 작업(텍스트 분류, 개체명 인식, 질문 응답, 감정 분석 등)에서 놀라운 결과를 얻을 수 있도록 해주었습니다.
Transformer Layers: BERT consists of multiple layers of Transformer encoders. Each layer processes the input sequence and passes it through self-attention mechanisms and feed-forward neural networks, enhancing the model's ability to capture complex relationships.
트랜스포머 레이어: BERT는 여러 개의 트랜스포머 인코더 레이어로 구성됩니다. 각 레이어는 입력 시퀀스를 처리하고 자기 어텐션 메커니즘과 피드포워드 신경망을 통과시켜 복잡한 관계를 포착하는 능력을 향상시킵니다.
Large Scale: BERT was initially released in two versions: BERT-base and BERT-large. The "large" version has more parameters and is capable of capturing more nuanced patterns in the text but requires more computational resources.
대규모 규모: BERT는 초기에 BERT-base와 BERT-large 두 가지 버전으로 출시되었습니다. "large" 버전은 매개변수가 더 많고 텍스트 내에서 더 미묘한 패턴을 포착할 수 있지만, 더 많은 컴퓨팅 자원이 필요합니다.
Contextualized Word Embeddings: BERT produces contextualized word embeddings, which are highly useful for downstream tasks. These embeddings capture not only syntactic information but also semantic relationships between words.
문맥화된 단어 임베딩: BERT는 문맥화된 단어 임베딩을 생성하며, 이는 하위 작업에 매우 유용합니다. 이러한 임베딩은 구문 정보 뿐만 아니라 단어 간의 의미적 관계를 포착합니다.
BERT's success has led to the development of various other transformer-based models like GPT (Generative Pre-trained Transformer), RoBERTa, XLNet, and more. These models have achieved state-of-the-art results on a wide array of NLP benchmarks and continue to drive advancements in the field.
BERT의 성공은 GPT(Generative Pre-trained Transformer), RoBERTa, XLNet 등과 같은 다양한 트랜스포머 기반 모델의 개발을 이끌었습니다. 이러한 모델은 다양한 NLP 벤치마크에서 최첨단 결과를 달성하고, 계속해서 이 분야의 발전을 주도하고 있습니다.
11.9.1.Encoder-Only
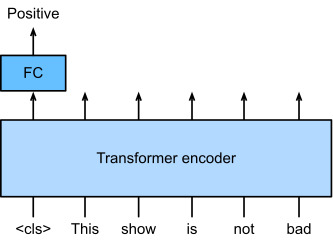
When only the Transformer encoder is used, a sequence of input tokens is converted into the same number of representations that can be further projected into output (e.g., classification). A Transformer encoder consists of self-attention layers, where all input tokens attend to each other. For example, vision Transformers depicted inFig. 11.8.1are encoder-only, converting a sequence of input image patches into the representation of a special “<cls>” token. Since this representation depends on all input tokens, it is further projected into classification labels. This design was inspired by an earlier encoder-only Transformer pretrained on text: BERT (Bidirectional Encoder Representations from Transformers)(Devlinet al., 2018).
Transformer encoder만 사용되는 경우 입력 토큰 시퀀스는 출력(예: 분류)으로 추가로 투영될 수 있는 동일한 수의 representations으로 변환됩니다. Transformer 인코더는 모든 입력 토큰이 서로 attend 하는self-attention layers으로 구성됩니다. 예를 들어 그림 11.8.1에 묘사된 비전 트랜스포머는 인코더 전용이며 일련의 입력 이미지 패치를 특수 "<cls>" 토큰의 representation으로 변환합니다. 이 representation은 모든 입력 토큰에 따라 달라지므로 분류 레이블에 추가로 투영됩니다. 이 디자인은 BERT(Bidirectional Encoder Representations from Transformers)(Devlin et al., 2018)라는 텍스트로 사전 훈련된 초기 인코더 전용 Transformer에서 영감을 받았습니다.
11.9.1.1.Pretraining BERT
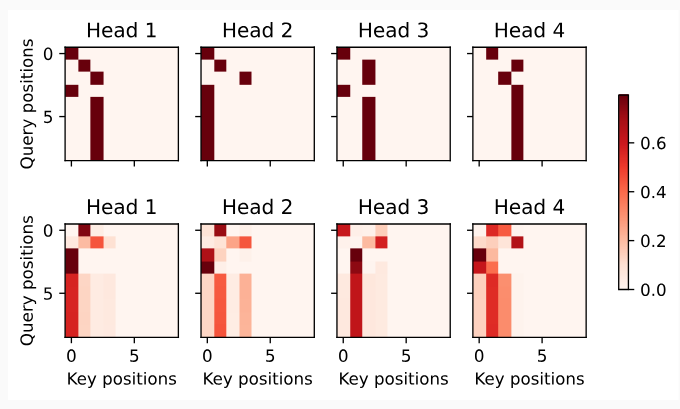
Fig. 11.9.1 Left: Pretraining BERT with masked language modeling. Prediction of the masked “love” token depends on all input tokens before and after “love”. Right: Attention pattern in the Transformer encoder. Each token along the vertical axis attends to all input tokens along the horizontal axis.
BERT is pretrained on text sequences usingmasked language modeling: input text with randomly masked tokens is fed into a Transformer encoder to predict the masked tokens. As illustrated inFig. 11.9.1, an original text sequence “I”, “love”, “this”, “red”, “car” is prepended with the “<cls>” token, and the “<mask>” token randomly replaces “love”; then the cross-entropy loss between the masked token “love” and its prediction is to be minimized during pretraining. Note that there is no constraint in the attention pattern of Transformer encoders (right ofFig. 11.9.1) so all tokens can attend to each other. Thus, prediction of “love” depends on input tokens before and after it in the sequence. This is why BERT is a “bidirectional encoder”. Without need for manual labeling, large-scale text data from books and Wikipedia can be used for pretraining BERT.
BERT는 masked language modeling을 사용하여 텍스트 시퀀스에 대해 사전 학습된 모델입니다. 임의로 마스킹된 토큰이 있는 입력 텍스트는 masked tokens을 예측하기 위해 Transformer 인코더에 공급됩니다. 그림 11.9.1과 같이 원본 텍스트 시퀀스 "I", "love", "this", "red", "car" 앞에 "<cls>" 토큰이 추가되고 "<mask>" 토큰은 무작위로 "love"을 대체합니다. 그런 다음 마스킹된 토큰 "사랑"과 그 예측 사이의 교차 엔트로피 손실은 사전 훈련 중에 최소화됩니다. Transformer 인코더(그림 11.9.1의 오른쪽)의 attention 패턴에는 제약이 없으므로 모든 토큰이 서로 attend할 수 있습니다. 따라서 "love"의 예측은 시퀀스에서 전후의 입력 토큰에 따라 달라집니다. 이것이 BERT가 "양방향 인코더 bidirectional encoder"인 이유입니다. 수동 레이블 지정이 필요 없이 책과 Wikipedia의 대규모 텍스트 데이터를 BERT 사전 학습에 사용할 수 있습니다.
11.9.1.2.Fine-Tuning BERT
The pretrained BERT can befine-tunedto downstream encoding tasks involving single text or text pairs. During fine-tuning, additional layers can be added to BERT with randomized parameters: these parameters and those pretrained BERT parameters will beupdatedto fit training data of downstream tasks.
사전 훈련된 BERT는 단일 텍스트 또는 텍스트 쌍을 포함하는 다운스트림 인코딩 작업으로 미세 조정fine-tuned 할 수 있습니다. 미세 조정 중에 무작위 매개변수를 사용하여 추가 계층을 BERT에 추가할 수 있습니다. 이러한 매개변수와 사전 훈련된 BERT 매개변수는 다운스트림 작업의 훈련 데이터에 맞게 업데이트됩니다.
Fig. 11.9.2 Fine-tuning BERT for sentiment analysis.
Fig. 11.9.2illustrates fine-tuning of BERT for sentiment analysis. The Transformer encoder is a pretrained BERT, which takes a text sequence as input and feeds the “<cls>” representation (global representation of the input) into an additional fully connected layer to predict the sentiment. During fine-tuning, the cross-entropy loss between the prediction and the label on sentiment analysis data is minimized via gradient-based algorithms, where the additional layer is trained from scratch while pretrained parameters of BERT are updated. BERT does more than sentiment analysis. The general language representations learned by the 350-million-parameter BERT from 250 billion training tokens advanced the state of the art for natural language tasks such as single text classification, text pair classification or regression, text tagging, and question answering.
그림 11.9.2는 감정 분석을 위한 BERT의 미세 조정을 보여줍니다. 트랜스포머 인코더는 사전 훈련된 BERT로, 텍스트 시퀀스를 입력으로 취하고 "<cls>" 표현(입력의 전역 표현)을 완전히 연결된 추가 레이어에 공급하여 감정을 예측합니다. 미세 조정 중에 감정 분석 데이터의 예측과 레이블 간의 교차 엔트로피 손실은 그래디언트 기반 알고리즘을 통해 최소화됩니다. 여기서 추가 레이어는 처음부터 훈련되고 BERT의 사전 훈련된 매개변수는 업데이트됩니다. BERT는 감정 분석 이상의 기능을 수행합니다. 2,500억 개의 훈련 토큰에서 3억 5천만 개의 매개변수 BERT가 학습한 일반 언어 표현은 단일 텍스트 분류, 텍스트 쌍 분류 또는 회귀, 텍스트 태깅 및 질문 응답과 같은 자연어 작업을 위한 최신 기술을 발전시켰습니다.
You may note that these downstream tasks include text pair understanding. BERT pretraining has another loss for predicting whether one sentence immediately follows the other. However, this loss was later found not useful when pretraining RoBERTa, a BERT variant of the same size, on 2000 billion tokens(Liuet al., 2019). Other derivatives of BERT improved model architectures or pretraining objectives, such as ALBERT (enforcing parameter sharing)(Lanet al., 2019), SpanBERT (representing and predicting spans of text)(Joshiet al., 2020), DistilBERT (lightweight via knowledge distillation)(Sanhet al., 2019), and ELECTRA (replaced token detection)(Clarket al., 2020). Moreover, BERT inspired Transformer pretraining in computer vision, such as with vision Transformers(Dosovitskiyet al., 2021), Swin Transformers(Liuet al., 2021), and MAE (masked autoencoders)(Heet al., 2022).
이러한 다운스트림 작업에는 텍스트 쌍 이해가 포함되어 있음을 알 수 있습니다. BERT 사전 훈련은 한 문장이 다른 문장 바로 뒤에 오는지 예측하는 데 또 다른 손실이 있습니다. 그러나 이 손실은 나중에 동일한 크기의 BERT 변형인 RoBERTa를 20000억 개(2조개?)의 토큰으로 사전 훈련할 때 유용하지 않은 것으로 밝혀졌습니다(Liu et al., 2019). ALBERT(매개 변수 공유 적용)(Lan et al., 2019), SpanBERT(텍스트 범위 표현 및 예측)(Joshi et al., 2020), DistilBERT(lightweight via 지식 증류)(Sanh et al., 2019) 및 ELECTRA(대체 토큰 탐지)(Clark et al., 2020). 또한 BERT는 비전 Transformers(Dosovitskiy et al., 2021), Swin Transformers(Liu et al., 2021) 및 MAE(masked autoencoders)(He et al., 2022)와 같은 컴퓨터 비전의 Transformer 사전 훈련에 영감을 주었습니다.
11.9.2.Encoder-Decoder
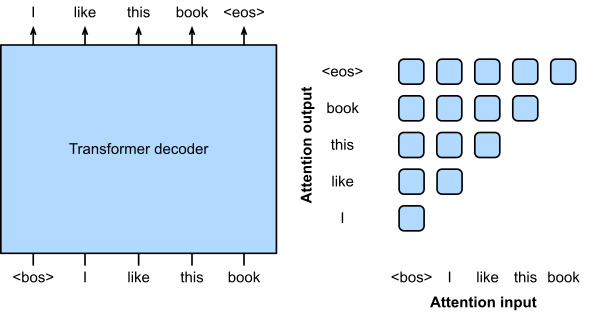
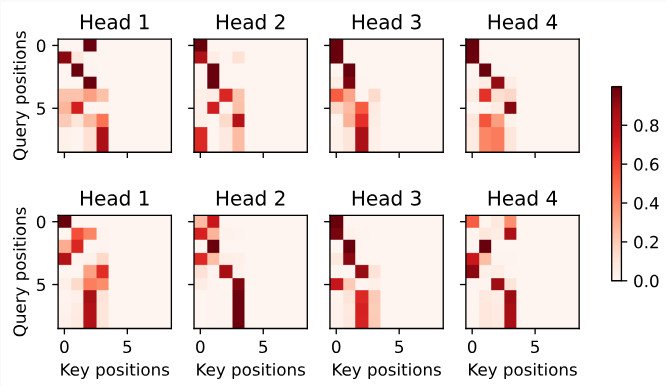
Since a Transformer encoder converts a sequence of input tokens into the same number of output representations, the encoder-only mode cannot generate a sequence of arbitrary length like in machine translation. As originally proposed for machine translation, the Transformer architecture can be outfitted with a decoder that autoregressively predicts the target sequence of arbitrary length, token by token, conditional on both encoder output and decoder output: (i) for conditioning on encoder output, encoder-decoder cross-attention (multi-head attention of decoder inFig. 11.7.1) allows target tokens to attend toallinput tokens; (ii) conditioning on decoder output is achieved by a so-calledcausalattention (this name is common in the literature but is misleading as it has little connection to the proper study of causality) pattern (masked multi-head attention of decoder inFig. 11.7.1), where any target token can only attend topastandpresenttokens in the target sequence.
Transformer 인코더는 일련의 입력 토큰을 동일한 수의 출력 표현으로 변환하므로 인코더 전용 모드는 기계 번역과 같이 임의 길이의 시퀀스를 생성할 수 없습니다. 원래 기계 번역을 위해 제안된 것처럼 Transformer 아키텍처에는 인코더 출력과 디코더 출력 모두에 조건부로 토큰별로 임의 길이의 대상 시퀀스를 자동 회귀적으로 예측하는 디코더가 장착될 수 있습니다.(i)encoder-decoder cross-attention(그림 11.7.1의 디코더의 multi-head attention)는 대상 토큰이 모든 입력 토큰에 attend하도록 허용합니다. (ii) 디코더 출력에 대한 컨디셔닝은 소위 causalattention(이 이름은 문헌에서 일반적이지만 causal 관계에 대한 적절한 연구와 거의 관련이 없기 때문에 오해의 소지가 있음) 패턴(그림에서 디코더의 마스킹된 다중 헤드 주의)에 의해 달성됩니다. . 11.7.1), 대상 토큰은 대상 시퀀스의 과거 및 현재 토큰에만 attend할 수 있습니다.
Casual Attention이란?
"Casual Attention"은 주로 시계열 데이터와 같이 순차적인 시간 또는 순서적인 관계를 가진 데이터에서 사용되는 어텐션 메커니즘입니다. 이러한 어텐션은 현재 위치 이전의 시점들만을 참조하여 예측하거나 분석하는 데 사용됩니다.
일반적으로 어텐션 메커니즘은 현재 위치의 쿼리(Query)와 모든 위치의 키(Key) 및 값(Value)을 사용하여 가중 평균을 계산하는데, 이 때문에 시계열 데이터와 같이 순서가 중요한 데이터에서 미래의 정보가 과도하게 유출될 수 있습니다. 이러한 문제를 해결하기 위해 "Casual Attention"은 현재 시점 이후의 정보에 대한 접근을 막음으로써 미래 정보의 유출을 방지합니다.
보통 "Casual Attention"은 마스크(mask)를 사용하여 현재 시점 이후의 위치를 가리고, 오직 현재 시점 이전의 위치만을 참조하도록 제한합니다. 이로써 모델은 현재 시점까지의 정보만을 사용하여 예측하거나 분석하게 되며, 시계열 데이터와 같은 순차적인 데이터에서 더 정확한 예측을 할 수 있도록 도와줍니다.
To pretrain encoder-decoder Transformers beyond human-labeled machine translation data, BART(Lewiset al., 2019)and T5(Raffelet al., 2020)are two concurrently proposed encoder-decoder Transformers pretrained on large-scale text corpora. Both attempt to reconstruct original text in their pretraining objectives, while the former emphasizes noising input (e.g., masking, deletion, permutation, and rotation) and the latter highlights multitask unification with comprehensive ablation studies.
사람이 라벨링한 기계 번역 데이터 이상으로 인코더-디코더 Transformer를 사전 훈련하기 위해 BART(Lewis et al., 2019) 및 T5(Raffel et al., 2020)는 대규모 텍스트 말뭉치(large-scale text corpora)에서 사전 훈련된 동시에 제안된 두 개의 인코더-디코더 Transformers입니다. 둘 다 사전 학습 목표에서 원본 텍스트를 재구성하려고 시도하는 반면, 전자는 노이즈 입력(예: 마스킹, 삭제, 순열 및 회전)을 강조하고 후자는 포괄적인 절제 연구(comprehensive ablation studies)를 통한 멀티태스크 통합을 강조합니다.
11.9.2.1.Pretraining T5
As an example of the pretrained Transformer encoder-decoder, T5 (Text-to-Text Transfer Transformer) unifies many tasks as the same text-to-text problem: for any task, the input of the encoder is a task description (e.g., “Summarize”, “:”) followed by task input (e.g., a sequence of tokens from an article), and the decoder predicts the task output (e.g., a sequence of tokens summarizing the input article). To perform as text-to-text, T5 is trained to generate some target text conditional on input text.
미리 훈련된 Transformer 인코더-디코더의 예로 T5(Text-to-Text Transfer Transformer)는 많은 작업을 동일한 text-to-text problem로 통합합니다. 모든 작업에 대해 인코더의 입력은 task description입니다(예: "Summarize", ":") 다음에 작업 입력(예: 기사의 토큰 시퀀스)이 있고 디코더는 작업 출력(예: a sequence of tokens from an article)을 예측합니다. 텍스트 대 텍스트로 수행하기 위해 T5는 입력 텍스트에 따라 일부 대상 텍스트를 생성하도록 훈련됩니다.
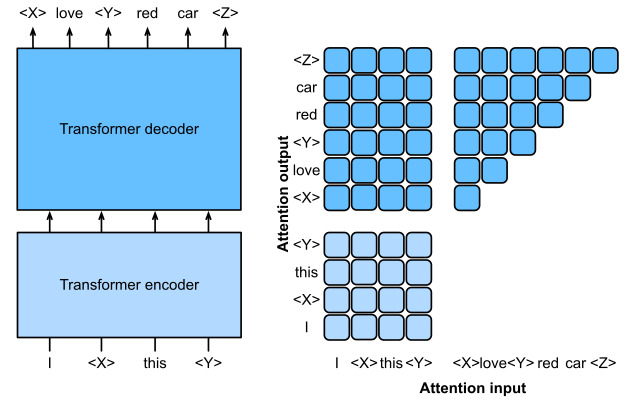
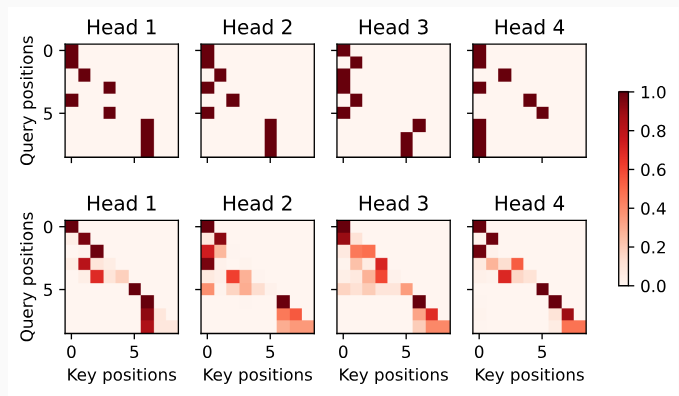
Fig. 11.9.3 Left: Pretraining T5 by predicting consecutive spans. The original sentence is “I”, “love”, “this”, “red”, “car”, where “love” is replaced by a special “<X>” token, and consecutive “red”, “car” are replaced by a special “<Y>” token. The target sequence ends with a special “<Z>” token. Right: Attention pattern in the Transformer encoder-decoder. In the encoder self-attention (lower square), all input tokens attend to each other; In the encoder-decoder cross-attention (upper rectangle), each target token attends to all input tokens; In the decoder self-attention (upper triangle), each target token attends to present and past target tokens only (causal). 그림 11.9.3 왼쪽: 연속적인 범위를 예측하여 T5를 사전 훈련합니다. 원래 문장은 "I", "love", "this", "red", "car"이며 여기서 "love"는 특별한 "<X>" 토큰으로 대체되고 연속적인 "red", "car"는 특수 "<Y>" 토큰으로 대체됩니다. 대상 시퀀스는 특수 "<Z>" 토큰으로 끝납니다. 오른쪽: Transformer 인코더-디코더의 주의 패턴. 인코더 self-attention(하단 사각형)에서 모든 입력 토큰은 서로에게 주의를 기울입니다. 인코더-디코더 교차 주의(위쪽 사각형)에서 각 대상 토큰은 모든 입력 토큰에 주의를 기울입니다. 디코더 self-attention(상단 삼각형)에서 각 대상 토큰은 현재 및 과거 대상 토큰에만 주의를 기울입니다(인과적).¶ ¶
To obtain input and output from any original text, T5 is pretrained to predict consecutive spans. Specifically, tokens from text are randomly replaced by special tokens where each consecutive span is replaced by the same special token. Consider the example inFig. 11.9.3, where the original text is “I”, “love”, “this”, “red”, “car”. Tokens “love”, “red”, “car” are randomly replaced by special tokens. Since “red” and “car” are a consecutive span, they are replaced by the same special token. As a result, the input sequence is “I”, “<X>”, “this”, “<Y>”, and the target sequence is “<X>”, “love”, “<Y>”, “red”, “car”, “<Z>”, where “<Z>” is another special token marking the end. As shown inFig. 11.9.3, the decoder has a causal attention pattern to prevent itself from attending to future tokens during sequence prediction.
원본 텍스트에서 입력 및 출력을 얻기 위해 T5는 연속 범위를 예측하도록 사전 훈련됩니다. 특히 텍스트의 토큰은 각 연속 범위가 동일한 특수 토큰으로 대체되는 특수 토큰으로 무작위로 대체됩니다. 원본 텍스트가 "I", "love", "this", "red", "car"인 그림 11.9.3의 예를 고려하십시오. "love", "red", "car" 토큰은 무작위로 특수 토큰으로 대체됩니다. "red"와 "car"는 연속적인 범위이므로 동일한 특수 토큰으로 대체됩니다. 결과적으로 입력 시퀀스는 “I”, “<X>”, “this”, “<Y>”이고 타겟 시퀀스는 “<X>”, “love”, “<Y>”, “ red”, “car”, “<Z>”, 여기서 “<Z>”는 끝을 표시하는 또 다른 특수 토큰입니다. 그림 11.9.3에서 볼 수 있듯이 디코더는 시퀀스 예측 중에 미래의 토큰에 attending 하는 것을 방지하기 위해 causal attention pattern을 가지고 있습니다.
In T5, predicting consecutive span is also referred to as reconstructing corrupted text. With this objective, T5 is pretrained with 1000 billion tokens from the C4 (Colossal Clean Crawled Corpus) data, which consists of clean English text from the Web(Raffelet al., 2020).
T5에서 연속 스팬 consecutive span 예측은 손상된 텍스트 재구성이라고도 합니다. 이 목표를 통해 T5는 웹의 깨끗한 영어 텍스트로 구성된 C4(Colossal Clean Crawled Corpus) 데이터의 10000억 개의 토큰으로 사전 훈련됩니다(Raffel et al., 2020).
11.9.2.2.Fine-Tuning T5
Similar to BERT, T5 needs to be fine-tuned (updating T5 parameters) on task-specific training data to perform this task. Major differences from BERT fine-tuning include: (i) T5 input includes task descriptions; (ii) T5 can generate sequences with arbitrary length with its Transformer decoder; (iii) No additional layers are required.
BERT와 유사하게 T5는 이 작업을 수행하기 위해 작업별 교육 데이터에서 미세 조정(T5 매개변수 업데이트)해야 합니다. BERT 미세 조정과의 주요 차이점은 다음과 같습니다. (i) T5 입력에는 task descriptions이 포함됩니다. (ii) T5는 트랜스포머 디코더로 임의 길이의 시퀀스를 생성할 수 있습니다. (iii) 추가 레이어가 필요하지 않습니다.
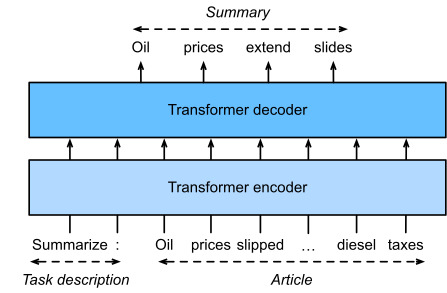
Fig. 11.9.4 Fine-tuning T5 for text summarization. Both the task description and article tokens are fed into the Transformer encoder for predicting the summary.
Fig. 11.9.4explains fine-tuning T5 using text summarization as an example. In this downstream task, the task description tokens “Summarize”, “:” followed by the article tokens are input to the encoder.
그림 11.9.4는 텍스트 요약을 예로 들어 T5 미세 조정을 설명합니다. 이 다운스트림 작업에서 작업 설명 토큰 "Summarize", ":" 뒤에 기사 토큰이 인코더에 입력됩니다.
After fine-tuning, the 11-billion-parameter T5 (T5-11B) achieved state-of-the-art results on multiple encoding (e.g., classification) and generation (e.g., summarization) benchmarks. Since released, T5 has been extensively used in later research. For example, switch Transformers are designed based off T5 to activate a subset of the parameters for better computational efficiency(Feduset al., 2022). In a text-to-image model called Imagen, text is input to a frozen T5 encoder (T5-XXL) with 4.6 billion parameters(Sahariaet al., 2022). The photorealistic text-to-image examples inFig. 11.9.5suggest that the T5 encoder alone may effectively represent text even without fine-tuning.
미세 조정 후 110억 매개변수 T5(T5-11B)는 다중 인코딩(예: 분류) 및 생성(예: 요약) 벤치마크에서 최첨단 결과를 달성했습니다. 출시 이후 T5는 이후 연구에서 광범위하게 사용되었습니다. 예를 들어 스위치 트랜스포머는 더 나은 계산 효율성을 위해 매개변수의 하위 집합을 활성화하기 위해 T5를 기반으로 설계되었습니다(Fedus et al., 2022). Imagen이라는 텍스트-이미지 모델에서 텍스트는 46억 개의 매개변수가 있는 고정된 T5 인코더(T5-XXL)에 입력됩니다(Saharia et al., 2022). 그림 11.9.5의 사실적인 텍스트 대 이미지 예는 미세 조정 없이도 T5 인코더만으로도 텍스트를 효과적으로 표현할 수 있음을 시사합니다.
Fig. 11.9.5 Text-to-image examples by the Imagen model, whose text encoder is from T5 (figures taken from Saharia et al. (2022)).
T5란?
T5(Tap-to-Transfer Transformer) is a versatile and powerful language model developed by Google Research in 2020. T5 is based on the transformer architecture, similar to BERT, and it takes the idea of transfer learning in natural language processing to a new level. The main innovation of T5 is its unified framework that can handle a wide range of NLP tasks using a single model.
T5(Tap-to-Transfer Transformer)은 2020년에 구글 리서치에서 개발한 다재다능한 언어 모델입니다. T5는 BERT와 마찬가지로 트랜스포머 아키텍처를 기반으로 하며, 자연어 처리의 전이 학습 아이디어를 새로운 수준으로 가져갑니다. T5의 주요 혁신은 하나의 모델로 다양한 NLP 작업을 처리할 수 있는 통합된 프레임워크입니다.
Here are some key points about T5:
다음은 T5에 관한 주요 사항입니다:
Transfer Learning for Various Tasks: T5 aims to simplify and unify the process of applying transformer models to various NLP tasks. Instead of developing separate models for different tasks like translation, text classification, question answering, and more, T5's single model can be fine-tuned for a wide array of tasks.
다양한 작업에 대한 전이 학습: T5는 트랜스포머 모델을 다양한 NLP 작업에 적용하기 위한 과정을 단순화하고 통합하려는 목표를 가지고 있습니다. 번역, 텍스트 분류, 질의 응답 등 다양한 작업을 위해 별도의 모델을 개발하는 대신 T5의 단일 모델을 다양한 작업에 미세 조정할 수 있습니다.
Unified Text-to-Text Format: T5 approaches all NLP tasks as text-to-text tasks. This means that both input and output are treated as text sequences. For example, translation can be seen as translating an input sentence to an output sentence, text classification as classifying an input text into a category, and so on.
통합된 텍스트-투-텍스트 형식: T5는 모든 NLP 작업을 텍스트-투-텍스트 작업으로 처리합니다. 이는 입력과 출력 모두를 텍스트 시퀀스로 처리하는 것을 의미합니다. 예를 들어, 번역은 입력 문장을 출력 문장으로 번역하는 작업으로 볼 수 있으며, 텍스트 분류는 입력 텍스트를 범주로 분류하는 작업과 같이 처리됩니다.
Pretraining and Fine-Tuning: T5 follows a two-step process: pretraining and fine-tuning. In the pretraining phase, the model is trained on a large corpus of text in an unsupervised manner, similar to how BERT is pretrained. In the fine-tuning phase, the pretrained model is adapted to specific tasks using labeled data.
사전 훈련과 미세 조정: T5는 사전 훈련 및 미세 조정 두 단계의 프로세스를 따릅니다. 사전 훈련 단계에서 모델은 대규모 텍스트 말뭉치에서 무지성으로 훈련되며, BERT와 유사한 방식입니다. 미세 조정 단계에서는 사전 훈련된 모델이 레이블된 데이터를 사용하여 특정 작업에 적응되는 과정입니다.
Text Generation and Compression: T5 excels in both text generation and text compression tasks. It can generate coherent and contextually relevant text, making it suitable for tasks like language translation, summarization, and story generation. Additionally, it can compress longer texts into shorter, informative versions, which is valuable for tasks like data-to-text generation.
텍스트 생성과 압축: T5는 텍스트 생성 및 텍스트 압축 작업 모두에서 뛰어난 성과를 보입니다. 일관되고 문맥에 맞는 텍스트를 생성할 수 있어 언어 번역, 요약, 이야기 생성과 같은 작업에 적합합니다. 더불어 긴 텍스트를 간결하면서도 정보를 잘 담은 형태로 압축하는 능력도 갖추고 있습니다. 이는 데이터를 텍스트로 변환하는 데이터-투-텍스트 생성 작업에 유용합니다.
Flexible Inputs and Outputs: T5 can accept various types of inputs and produce diverse outputs. For example, it can take prompts like "Translate the following English text to French: ..." and generate the translation. It can also be used for multiple-choice questions, summarization, and even image captioning by converting the task into text-to-text format.
유연한 입력과 출력: T5는 다양한 유형의 입력을 받아들이고 다양한 출력을 생성할 수 있습니다. 예를 들어 "다음 영어 텍스트를 프랑스어로 번역하세요: ..."와 같은 프롬프트를 받아들이고 번역을 생성할 수 있습니다. 선택지 문제, 요약, 심지어 이미지 캡션 작업에도 텍스트-투-텍스트 형식으로 활용될 수 있습니다.
Large-Scale Model: Similar to other transformer models, T5 comes in different sizes, such as T5-small, T5-base, T5-large, and T5-3B, with increasing model parameters and capabilities.
대규모 모델: 다른 트랜스포머 모델과 마찬가지로 T5는 T5-small, T5-base, T5-large, T5-3B 등 다양한 크기로 제공되며 모델 파라미터와 능력이 증가합니다.
T5's unified framework and its ability to handle a wide range of NLP tasks have made it a popular choice in the NLP community. It has achieved impressive results on various benchmarks and has contributed to advancing the field of natural language processing and understanding.
T5의 통합된 프레임워크와 다양한 NLP 작업을 처리하는 능력은 NLP 커뮤니티에서 인기를 얻었습니다. 다양한 벤치마크에서 놀라운 결과를 달성하며 자연어 처리와 이해 분야의 발전에 기여하였습니다.
11.9.3.Decoder-Only
We have reviewed encoder-only and encoder-decoder Transformers. Alternatively, decoder-only Transformers remove the entire encoder and the decoder sublayer with the encoder-decoder cross-attention from the original encoder-decoder architecture depicted inFig. 11.7.1. Nowadays, decoder-only Transformers have been the de facto architecture in large-scale language modeling (Section 9.3), which leverages the world’s abundant unlabeled text corpora via self-supervised learning.
인코더 전용 및 인코더-디코더 transformer를 검토했습니다. 또는 디코더 전용 트랜스포머는 전체 인코더와 그림 11.7.1에 묘사된 원래 인코더-디코더 아키텍처에서 인코더-디코더 cross attention이 있는 디코더 하위 계층을 제거합니다. 오늘날 디코더 전용 트랜스포머는 대규모 언어 모델링(9.3절)에서 사실상의 아키텍처였으며, 이는 자기 지도 학습을 통해 전 세계의 풍부한 레이블 없는 텍스트 말뭉치를 활용합니다.
11.9.3.1.GPT and GPT-2
Using language modeling as the training objective, the GPT (generative pre-training) model chooses a Transformer decoder as its backbone(Radfordet al., 2018).
학습 목표로 언어 모델링을 사용하는 GPT(Generative Pre-training) 모델은 Transformer 디코더를 백본으로 선택합니다(Radford et al., 2018).
Fig. 11.9.6 Left: Pretraining GPT with language modeling. The target sequence is the input sequence shifted by one token. Both “<bos>” and “<eos>” are special tokens marking the beginning and end of sequences, respectively. Right: Attention pattern in the Transformer decoder. Each token along the vertical axis attends to only its past tokens along the horizontal axis (causal). ¶그림 11.9.6 왼쪽: 언어 모델링을 사용한 GPT 사전 학습. 대상 시퀀스는 하나의 토큰만큼 이동된 입력 시퀀스입니다. "<bos>"와 "<eos>"는 각각 시퀀스의 시작과 끝을 표시하는 특수 토큰입니다. 오른쪽: Transformer 디코더의 주의 패턴. 세로축의 각 토큰은 가로축의 과거 토큰에만 적용됩니다(인과적).¶
Following the autoregressive language model training as described inSection 9.3.3,Fig. 11.9.6illustrates GPT pretraining with a Transformer encoder, where the target sequence is the input sequence shifted by one token. Note that the attention pattern in the Transformer decoder enforces that each token can only attend to its past tokens (future tokens cannot be attended to because they have not yet been chosen).
섹션 9.3.3에 설명된 autoregressive language model training에 이어 그림 11.9.6은 Transformer 인코더를 사용한 GPT 사전 교육을 보여줍니다. 여기서 대상 시퀀스는 하나의 토큰만큼 이동된 입력 시퀀스입니다. Transformer 디코더의 attention pattern은 각 토큰이 과거 토큰에만 attend할 수 있도록 합니다(미래의 토큰은 아직 선택되지 않았기 때문에 참석할 수 없음).
GPT has 100 million parameters and needs to be fine-tuned for individual downstream tasks. A much larger Transformer-decoder language model, GPT-2, was introduced one year later(Radfordet al., 2019). Compared with the original Transformer decoder in GPT, pre-normalization (discussed inSection 11.8.3) and improved initialization and weight-scaling were adopted in GPT-2. Pretrained on 40 GB of text, the 1.5-billion-parameter GPT-2 obtained the state-of-the-art results on language modeling benchmarks and promising results on multiple other taskswithout updating the parameters or architecture.
GPT에는 1억 개의 매개변수가 있으며 개별 다운스트림 작업에 맞게 미세 조정해야 합니다. 훨씬 더 큰 Transformer-decoder 언어 모델인 GPT-2가 1년 후에 도입되었습니다(Radford et al., 2019). GPT의 원래 Transformer 디코더와 비교하여 사전 정규화(11.8.3절에서 설명)와 향상된 초기화 및 가중치 스케일링이 GPT-2에 채택되었습니다. 40GB의 텍스트로 사전 훈련된 15억 개의 매개변수 GPT-2는 언어 모델링 벤치마크에서 최신 결과를 얻었고 매개변수나 아키텍처를 업데이트하지 않고도 여러 다른 작업에서 유망한 결과를 얻었습니다.
11.9.3.2.GPT-3
GPT-2 demonstrated potential of using the same language model for multiple tasks without updating the model. This is more computationally efficient than fine-tuning, which requires model updates via gradient computation.
GPT-2는 모델을 업데이트하지 않고 여러 작업에 동일한 언어 모델을 사용할 수 있는 가능성을 보여주었습니다. 이것은 그래디언트 계산을 통해 모델을 업데이트해야 하는 미세 조정보다 계산적으로 더 효율적입니다.
Fig. 11.9.7 Zero-shot, one-shot, few-shot in-context learning with language models (Transformer decoders). No parameter update is needed.
Before explaining the more computationally efficient use of language models without parameter update, recallSection 9.5that a language model can be trained to generate a text sequence conditional on some prefix text sequence. Thus, a pretrained language model may generate the task output as a sequencewithout parameter update, conditional on an input sequence with the task description, task-specific input-output examples, and a prompt (task input). This learning paradigm is calledin-context learning(Brownet al., 2020), which can be further categorized intozero-shot,one-shot, andfew-shot, when there is no, one, and a few task-specific input-output examples, respectively (Fig. 11.9.7).
매개 변수 업데이트 없이 언어 모델을 보다 계산적으로 효율적으로 사용하는 방법을 설명하기 전에 일부 접두사 텍스트 시퀀스에 조건부 텍스트 시퀀스를 생성하도록 언어 모델을 훈련할 수 있다는 섹션 9.5를 상기하십시오. 따라서 미리 훈련된 언어 모델은 작업 설명, 작업별 입력-출력 예제 및 프롬프트(작업 입력)가 있는 입력 시퀀스에 따라 매개 변수 업데이트 없이 시퀀스로 작업 출력을 생성할 수 있습니다. 이러한 학습 패러다임을 in-context learning(Brown et al., 2020)이라고 하며, 더 나아가 제로샷(zero-shot), 원샷(one-shot), 퓨어샷(female-shot)으로 분류할 수 있다. 각각 입력-출력 예(그림 11.9.7).
in-context learning이란?
'In-context learning'은 주어진 문맥(context) 내에서 학습하는 개념을 나타냅니다. 이것은 기계 학습 또는 딥 러닝 모델이 주어진 데이터 포인트를 주변 문맥과 관련하여 학습하고 예측하는 것을 의미합니다.
예를 들어, 자연어 처리(NLP)에서 특정 단어의 의미를 이해하려면 해당 단어의 주변 문맥을 고려해야 합니다. 이를 위해 주어진 단어 주변의 단어들을 입력으로 사용하여 모델을 학습하고, 주변 문맥을 통해 해당 단어의 의미를 파악하려는 것이 'in-context learning'입니다.
'In-context learning'은 문제를 더 정확하게 이해하고 예측하기 위해 문맥 정보를 활용하는 중요한 방법 중 하나입니다. 이는 자연어 처리, 컴퓨터 비전, 음성 처리 등 다양한 분야에서 활용되며, 모델의 성능을 향상시키는 데 도움이 됩니다.
zero-shot, one-shot, few shot이란?
'Zero-shot', 'one-shot', 그리고 'few-shot'은 머신 러닝 및 딥 러닝에서 사용되는 학습 접근 방식을 나타내는 용어입니다.
Zero-shot Learning (제로샷 학습): 제로샷 학습은 학습 데이터 없이 새로운 클래스 또는 작업에 대한 학습을 시도하는 접근 방식입니다. 모델은 이미 학습된 정보를 기반으로 새로운 데이터에 대한 예측을 수행합니다. 이를 위해 추가 정보나 외부 지식을 활용하는 경우가 많습니다.
One-shot Learning (원샷 학습): 원샷 학습은 매우 작은 수의 학습 데이터만을 이용하여 새로운 클래스 또는 작업에 대한 학습을 시도하는 접근 방식입니다. 예를 들어, 하나의 학습 샘플만 사용하여 클래스를 구분하는 작업을 수행하는 것을 말합니다.
Few-shot Learning (퓨샷 학습): 퓨샷 학습은 원샷 학습과 비슷하지만, 더 큰 데이터 셋에서 몇 개의 학습 샘플을 사용하여 새로운 클래스나 작업에 대한 학습을 시도하는 접근 방식입니다. 보통 5개 이하의 학습 샘플을 사용하는 경우를 말합니다.
이러한 접근 방식들은 데이터가 부족한 상황에서 새로운 클래스나 작업에 대한 모델을 구축할 때 유용하게 활용될 수 있습니다.
Fig. 11.9.8 Aggregate performance of GPT-3 for all 42 accuracy-denominated benchmarks (caption adapted and figure taken from Brown et al. (2020)).
These three settings were tested in GPT-3(Brownet al., 2020), whose largest version uses data and model size about two orders of magnitude larger than those in GPT-2. GPT-3 uses the same Transformer decoder architecture in its direct predecessor GPT-2 except that attention patterns (right ofFig. 11.9.6) are sparser at alternating layers. Pretrained with 300 billion tokens, GPT-3 performs better with larger model size, where few-shot performance increases most rapidly (Fig. 11.9.8).
이 세 가지 설정은 GPT-3(Brown et al., 2020)에서 테스트되었으며, 가장 큰 버전은 GPT-2보다 약 2배 더 큰 데이터와 모델 크기를 사용합니다. GPT-3는 어텐션 패턴(그림 11.9.6의 오른쪽)이 교대 레이어에서 희박하다는 점을 제외하면 이전 GPT-2와 동일한 트랜스포머 디코더 아키텍처를 사용합니다. 3000억 개의 토큰으로 사전 훈련된 GPT-3는 더 큰 모델 크기에서 더 나은 성능을 발휘하며 여기서 퓨샷 성능이 가장 빠르게 증가합니다(그림 11.9.8).
Large language models offer an exciting prospect of formulating text input to induce models to perform desired tasks via in-context learning, which is also known asprompting. For example,chain-of-thought prompting(Weiet al., 2022), an in-context learning method with few-shot “question, intermediate reasoning steps, answer” demonstrations, elicits the complex reasoning capabilities of large language models to solve mathematical, commonsense, and symbolic reasoning tasks. Sampling multiple reasoning paths(Wanget al., 2023), diversifying few-shot demonstrations(Zhanget al., 2023), and reducing complex problems to sub-problems(Zhouet al., 2023)can all improve the reasoning accuracy. In fact, with simple prompts like “Let’s think step by step” just before each answer, large language models can even performzero-shotchain-of-thought reasoning with decent accuracy(Kojimaet al., 2022). Even for multimodal inputs consisting of both text and images, language models can perform multimodal chain-of-thought reasoning with further improved accuracy than using text input only(Zhanget al., 2023).
대규모 언어 모델은 프롬프트라고도 하는 in-context learning을 통해 모델이 원하는 작업을 수행하도록 유도하기 위해 텍스트 입력을 공식화하는 흥미로운 전망을 제공합니다. 예를 들어, 몇 번의 "질문, 중간 추론 단계, 답변" 데모가 포함된 상황 내 학습 방법인 chain-of-thought prompting(Wei et al., 2022)는 문제를 해결하기 위해 대규모 언어 모델의 복잡한 추론 기능을 이끌어냅니다. 수학, 상식 및 상징적 추론 작업. 다중 추론 경로 샘플링(Wang et al., 2023), 소수 샷 시연 다양화(Zhang et al., 2023), 복잡한 문제를 하위 문제로 줄이는 것(Zhou et al., 2023) 모두 추론 정확도를 향상시킬 수 있습니다. 사실, 각 답변 직전에 "차근차근 생각해 봅시다"와 같은 간단한 프롬프트를 통해 대규모 언어 모델은 적절한 정확도로 제로샷 연쇄 사고 추론을 수행할 수도 있습니다(Kojima et al., 2022). 텍스트와 이미지로 구성된 다중 모드 입력의 경우에도 언어 모델은 텍스트 입력만 사용하는 것보다 더 향상된 정확도로 다중 모드 사고 연쇄 추론을 수행할 수 있습니다(Zhang et al., 2023).
11.9.4.Scalability
Fig. 11.9.8empirically demonstrates scalability of Transformers in the GPT-3 language model. For language modeling, more comprehensive empirical studies on the scalability of Transformers have led researchers to see promise in training larger Transformers with more data and compute(Kaplanet al., 2020).
그림 11.9.8은 GPT-3 언어 모델에서 Transformers의 확장성을 실증적으로 보여준다. 언어 모델링의 경우 Transformers의 확장성에 대한 보다 포괄적인 경험적 연구를 통해 연구자들은 더 많은 데이터와 컴퓨팅으로 더 큰 Transformers를 교육할 가능성을 확인했습니다(Kaplan et al., 2020).
Fig. 11.9.9 Transformer language model performance improves smoothly as we increase the model size, dataset size, and amount of compute used for training. For optimal performance all three factors must be scaled up in tandem. Empirical performance has a power-law relationship with each individual factor when not bottlenecked by the other two (caption adapted and figure taken from Kaplan et al. (2020)).
As shown inFig. 11.9.9,power-law scalingcan be observed in the performance with respect to the model size (number of parameters, excluding embedding layers), dataset size (number of training tokens), and amount of training compute (PetaFLOP/s-days, excluding embedding layers). In general, increasing all these three factors in tandem leads to better performance. However,howto increase them in tandem still remains a matter of debate(Hoffmannet al., 2022).
그림 11.9.9에서와 같이 Model size (number of parameters, excluding embedding layers), data size (number of training tokens) 그리고 amount of training compute (PetaFLOP/s-days, excluding embedding layers) 가 늘어날 수록 성능이 좋아진다. ==> power-law scaling을 볼 수 있다. 그러나 그것들을 동시에 증가시키는 방법은 여전히 논쟁의 문제로 남아 있습니다(Hoffmann et al., 2022).
Fig. 11.9.10 Transformer language model training runs (figure taken from Kaplan et al. (2020)).
Besides increased performance, large models also enjoy better sample efficiency than small models.Fig. 11.9.10shows that large models need fewer training samples (tokens processed) to perform at the same level achieved by small models, and performance is scaled smoothly with compute.
향상된 성능 외에도 대형 모델은 소형 모델보다 샘플 효율성이 더 좋습니다. 그림 11.9.10은 작은 모델이 달성한 것과 동일한 수준에서 수행하기 위해 더 적은 수의 교육 샘플(처리된 토큰)이 필요한 큰 모델을 보여 주며 성능은 컴퓨팅을 통해 원활하게 확장됩니다.
Fig. 11.9.11 GPT-3 performance (cross-entropy validation loss) follows a power-law trend with the amount of compute used for training. The power-law behavior observed in Kaplan et al. (2020) continues for an additional two orders of magnitude with only small deviations from the predicted curve. Embedding parameters are excluded from compute and parameter counts (caption adapted and figure taken from Brown et al. (2020)).
The empirical scaling behaviors inKaplanet al.(2020)have been tested in subsequent large Transformer models. For example, GPT-3 supported this hypothesis with two more orders of magnitude inFig. 11.9.11.
Kaplan et al.의 경험적 스케일링 동작. (2020) 이후의 대형 Transformer 모델에서 테스트되었습니다. 예를 들어, GPT-3는 그림 11.9.11에서 두 자릿수 이상의 크기로 이 가설을 뒷받침했습니다.
The scalability of Transformers in the GPT series has inspired subsequent Transformer language models. While the Transformer decoder in GPT-3 was largely followed in OPT (Open Pretrained Transformers)(Zhanget al., 2022)using only 1/7th the carbon footprint of the former, the GPT-2 Transformer decoder was used in training the 530-billion-parameter Megatron-Turing NLG(Smithet al., 2022)with 270 billion training tokens. Following the GPT-2 design, the 280-billion-parameter Gopher(Raeet al., 2021)pretrained with 300 billion tokens achieved state-of-the-art performance across the majority on about 150 diverse tasks. Inheriting the same architecture and using the same compute budget of Gopher, Chinchilla(Hoffmannet al., 2022)is a substantially smaller (70 billion parameters) model that trains much longer (1.4 trillion training tokens), outperforming Gopher on many tasks. To continue the scaling line of language modeling, PaLM (Pathway Language Model)(Chowdheryet al., 2022), a 540-billion-parameter Transformer decoder with modified designs pretrained on 780 billion tokens, outperformed average human performance on the BIG-Bench benchmark(Srivastavaet al., 2022). Further training PaLM on 38.5 billion tokens containing scientific and mathematical content results in Minerva(Lewkowyczet al., 2022), a large language model that can answer nearly a third of undergraduate-level problems that require quantitative reasoning, such as in physics, chemistry, biology, and economics.
GPT 시리즈의 트랜스포머 확장성은 후속 트랜스포머 언어 모델에 영감을 주었습니다. GPT-3의 Transformer 디코더는 OPT(Open Pretrained Transformers)(Zhang et al., 2022)에서 전자의 탄소 발자국의 1/7만 사용하여 주로 따랐지만 GPT-2 Transformer 디코더는 530을 교육하는 데 사용되었습니다. - 2700억 개의 훈련 토큰이 있는 10억 개의 매개변수 Megatron-Turing NLG(Smith et al., 2022). GPT-2 설계에 따라 3000억 개의 토큰으로 사전 훈련된 2800억 개의 매개변수 Gopher(Rae et al., 2021)는 약 150개의 다양한 작업에서 대다수에 걸쳐 최첨단 성능을 달성했습니다. 동일한 아키텍처를 상속하고 Gopher의 동일한 컴퓨팅 예산을 사용하는 Chinchilla(Hoffmann et al., 2022)는 훨씬 더 오래(1조 4천억 개의 훈련 토큰) 훈련하는 상당히 작은(700억 매개변수) 모델로 많은 작업에서 Gopher를 능가합니다. 언어 모델링의 스케일링 라인을 계속하기 위해, 7,800억 개의 토큰으로 사전 훈련된 수정된 설계가 있는 5,400억 개의 매개변수 Transformer 디코더인 PaLM(Pathway Language Model)(Chowdhery et al., 2022)은 BIG-Bench에서 평균적인 인간 성능을 능가했습니다. 벤치마크(Srivastava et al., 2022). 과학 및 수학적 콘텐츠가 포함된 385억 개의 토큰에 대해 PaLM을 추가로 교육하면 물리학, 화학과 같이 정량적 추론이 필요한 학부 수준 문제의 거의 1/3에 답할 수 있는 대규모 언어 모델인 Minerva(Lewkowycz et al., 2022)가 생성됩니다. , 생물학 및 경제학.
Weiet al.(2022)discussed emergent abilities of large language models that are only present in larger models, but not present in smaller models. However, simply increasing model size does not inherently make models follow human instructions better. Following InstructGPT that aligns language models with human intent via fine-tuning(Ouyanget al., 2022),ChatGPTis able to follow instructions, such as code debugging and note drafting, from its conversations with humans.
Weiet al. (2022)는 더 큰 모델에만 존재하고 더 작은 모델에는 존재하지 않는 대규모 언어 모델의 창발적 능력에 대해 논의했습니다. 그러나 단순히 모델 크기를 늘리는 것이 본질적으로 모델이 사람의 지시를 더 잘 따르도록 만들지는 않습니다. 미세 조정을 통해 언어 모델을 인간의 의도에 맞추는 InstructGPT(Ouyang et al., 2022)에 이어 ChatGPT는 인간과의 대화에서 코드 디버깅 및 메모 작성과 같은 지침을 따를 수 있습니다.
GPT, GPT2, GPT3에 대하여.
GPT (Generative Pre-trained Transformer) series refers to a sequence of language models developed by OpenAI, each building upon the success and innovations of the previous version. These models are designed based on the Transformer architecture, which has proven to be highly effective for a wide range of natural language processing tasks. Here's an overview of each model:
GPT(Generative Pre-trained Transformer) 시리즈는 OpenAI에서 개발한 언어 모델 시퀀스로, 각 버전이 이전 버전의 성과와 혁신을 기반으로 발전되었습니다. 이 모델들은 Transformer 아키텍처를 기반으로 설계되어 다양한 자연어 처리 작업에 높은 효율성을 보입니다. 각 모델에 대한 개요는 아래와 같습니다:
GPT-1 (Generative Pre-trained Transformer 1): GPT-1 was the first model in the series. It introduced the concept of pre-training a large neural network on a massive amount of text data and then fine-tuning it on specific downstream tasks. It used a decoder-only Transformer architecture and demonstrated impressive performance on various language tasks. However, it was limited by its relatively smaller size compared to later versions.
GPT-1 (Generative Pre-trained Transformer 1): GPT-1은 시리즈에서 처음 나온 모델입니다. 이 모델은 대량의 텍스트 데이터에서 큰 신경망을 사전 훈련하고 특정 하위 작업에 대해 세밀하게 튜닝하는 개념을 소개했습니다. 디코더만을 사용하는 Transformer 아키텍처를 사용하였으며, 다양한 언어 작업에서 인상적인 성능을 보였습니다. 하지만 이후 버전들과 비교하여 크기가 상대적으로 작아 제한된 성능을 보였습니다.
GPT-2 (Generative Pre-trained Transformer 2): GPT-2 was a significant leap forward in terms of size and capabilities. It gained widespread attention for its large number of parameters (up to 1.5 billion) and its ability to generate coherent and contextually relevant text. GPT-2 was so powerful that OpenAI initially chose not to release its largest versions due to concerns about potential misuse for generating fake news or deceptive content. GPT-2 showed remarkable performance across a wide range of tasks and achieved state-of-the-art results on various benchmarks.
GPT-2 (Generative Pre-trained Transformer 2): GPT-2는 크기와 성능 면에서 큰 도약을 이루었습니다. 15억 개의 파라미터를 가진 대규모 모델로, 연관성 있는 문장을 생성하는 능력으로 널리 주목받았습니다. GPT-2는 파라미터의 많은 양과 함께 크고 복잡한 텍스트를 생성할 수 있는 능력으로 유명해졌습니다. GPT-2는 다양한 작업에서 높은 성능을 보여주며 다양한 벤치마크에서 최고 수준의 결과를 달성했습니다.
GPT-3 (Generative Pre-trained Transformer 3): GPT-3 marked another substantial advancement in the series. With a staggering 175 billion parameters, GPT-3 is one of the largest language models ever created. It demonstrated the ability to generate highly coherent and contextually relevant text across a wide variety of prompts. What makes GPT-3 particularly remarkable is its "few-shot" or "zero-shot" learning capabilities. It can perform tasks with minimal examples or even no explicit training, as long as the task is described in the prompt.
GPT-3's versatility has allowed it to excel in tasks ranging from translation and summarization to question answering and code generation. However, GPT-3 also raised concerns about biases present in its training data and the ethical implications of such powerful language models.
GPT-3 (Generative Pre-trained Transformer 3): GPT-3는 시리즈의 또 다른 큰 발전을 이루었습니다. 1750억 개의 파라미터를 가지며, 이는 역사적으로 가장 큰 언어 모델 중 하나입니다. GPT-3는 문맥상 관련성이 높은 텍스트를 다양한 프롬프트에 대해 생성할 수 있는 능력을 보였습니다. 특히 GPT-3의 놀라운 점은 "few-shot" 또는 "zero-shot" 학습 능력입니다. 몇 개의 예시나 아예 훈련이 없더라도 프롬프트에 명시된 작업을 수행할 수 있습니다.
GPT-3의 다재다능함은 번역, 요약, 질문 답변, 코드 생성과 같은 다양한 작업에서 뛰어난 성과를 거두게 했습니다. 하지만 GPT-3는 훈련 데이터의 편향성과 같은 문제, 그리고 이러한 강력한 언어 모델의 윤리적인 측면에 대한 우려를 불러일으켰습니다.
All of these models, GPT-1, GPT-2, and GPT-3, are part of the broader trend of using large-scale pre-training followed by fine-tuning for specific tasks. They have contributed significantly to advancing the field of natural language processing and understanding.
GPT-1, GPT-2 및 GPT-3는 모두 대량 사전 훈련 후 특정 작업에 대한 세부 튜닝을 통한 넓은 범위의 프레임워크를 대표합니다. 이들은 자연어 처리 및 이해 분야를 크게 발전시키는 데 기여한 중요한 모델 시리즈입니다.
11.9.5.Summary and Discussion
Transformers have been pretrained as encoder-only (e.g., BERT), encoder-decoder (e.g., T5), and decoder-only (e.g., GPT series). Pretrained models may be adapted to perform different tasks with model update (e.g., fine tuning) or not (e.g., few shot). Scalability of Transformers suggests that better performance benefits from larger models, more training data, and more training compute. Since Transformers were first designed and pretrained for text data, this section leans slightly towards natural language processing. Nonetheless, those models discussed above can be often found in more recent models across multiple modalities. For example, (i) Chinchilla(Hoffmannet al., 2022)was further extended to Flamingo(Alayracet al., 2022), a visual language model for few-shot learning; (ii) GPT-2(Radfordet al., 2019)and the vision Transformer encode text and images in CLIP (Contrastive Language-Image Pre-training)(Radfordet al., 2021), whose image and text embeddings were later adopted in the DALL-E 2 text-to-image system(Rameshet al., 2022). Although there has been no systematic studies on Transformer scalability in multi-modal pretraining yet, a recent all-Transformer text-to-image model, Parti(Yuet al., 2022), shows potential of scalability across modalities: a larger Parti is more capable of high-fidelity image generation and content-rich text understanding (Fig. 11.9.12).
트랜스포머는 인코더 전용(예: BERT), 인코더-디코더(예: T5) 및 디코더 전용(예: GPT 시리즈)으로 사전 훈련되었습니다. 사전 훈련된 모델은 모델 업데이트(예: 미세 조정) 또는 그렇지 않은(예: 소수 샷) 다른 작업을 수행하도록 조정될 수 있습니다. Transformers의 확장성은 더 큰 모델, 더 많은 교육 데이터 및 더 많은 교육 컴퓨팅에서 더 나은 성능 이점을 제공합니다. 트랜스포머는 처음에 텍스트 데이터용으로 설계되고 사전 훈련되었기 때문에 이 섹션은 자연어 처리에 약간 기울어져 있습니다. 그럼에도 불구하고 위에서 논의한 모델은 종종 여러 양식에 걸친 최신 모델에서 찾을 수 있습니다. 예를 들어, (i) 친칠라(Hoffmann et al., 2022)는 퓨어샷 학습을 위한 시각적 언어 모델인 Flamingo(Alayrac et al., 2022)로 더욱 확장되었습니다. (ii) GPT-2(Radford et al., 2019) 및 비전 트랜스포머는 CLIP(Contrastive Language-Image Pre-training)(Radford et al., 2021)에서 텍스트와 이미지를 인코딩하며, 이미지 및 텍스트 임베딩은 나중에 채택되었습니다. DALL-E 2 텍스트-이미지 시스템에서(Ramesh et al., 2022). 다중 모달 사전 훈련에서 Transformer 확장성에 대한 체계적인 연구는 아직 없지만 최근의 모든 변환기 텍스트-이미지 모델인 Parti(Yu et al., 2022)는 양식에 걸친 확장 가능성을 보여줍니다. 더 큰 Parti는 고화질 이미지 생성 및 내용이 풍부한 텍스트 이해가 더 가능합니다(그림 11.9.12).
Fig. 11.9.12 Image examples generated from the same text by the Parti model of increasing sizes (350M, 750M, 3B, 20B) (examples taken from Yu et al. (2022)).
11.9.6.Exercises
Is it possible to fine tune T5 using a minibatch consisting of different tasks? Why or why not? How about for GPT-2?
Given a powerful language model, what applications can you think of?
Say that you are asked to fine tune a language model to perform text classification by adding additional layers. Where will you add them? Why?
Consider sequence to sequence problems (e.g., machine translation) where the input sequence is always available throughout the target sequence prediction. What could be limitations of modeling with decoder-only Transformers? Why?
The Transformer architecture was initially proposed for sequence to sequence learning, with a focus on machine translation. Subsequently, Transformers emerged as the model of choice in various natural language processing tasks(Brownet al., 2020,Devlinet al., 2018,Radfordet al., 2018,Radfordet al., 2019,Raffelet al., 2020). However, in the field of computer vision the dominant architecture has remained the CNN (Section 8). Naturally, researchers started to wonder if it might be possible to do better by adapting Transformer models to image data. This question sparked immense interest in the computer vision community. Recently,Ramachandranet al.(2019)proposed a scheme for replacing convolution with self-attention. However, its use of specialized patterns in attention makes it hard to scale up models on hardware accelerators. Then,Cordonnieret al.(2020)theoretically proved that self-attention can learn to behave similarly to convolution. Empirically,2×2patches were taken from images as inputs, but the small patch size makes the model only applicable to image data with low resolutions.
Transformer 아키텍처는 처음에 기계 번역에 중점을 둔 sequence to sequence learning을 위해 제안되었습니다. 이후 Transformers는 다양한 자연어 처리 작업에서 선택 모델로 등장했습니다(Brown et al., 2020, Devlin et al., 2018, Radford et al., 2018, Radford et al., 2019, Raffel et al., 2020). ). 그러나 컴퓨터 비전 분야에서 지배적인 아키텍처는 CNN으로 남아 있습니다(섹션 8). 당연히 연구자들은 Transformer 모델을 이미지 데이터에 적용하여 더 잘할 수 있을지 궁금해하기 시작했습니다. 이 질문은 컴퓨터 비전 커뮤니티에서 엄청난 관심을 불러일으켰습니다. 최근 Ramachandran et al. (2019)는 컨볼루션을 self-attention으로 대체하는 방식을 제안했습니다. 그러나 어텐션에 특화된 패턴을 사용하면 hardware accelerators에서 모델을 확장하기가 어렵습니다. ??? 그런 다음 Cordonnier et al. (2020)은 self-attention이 convolution과 유사하게 동작하도록 학습할 수 있음을 이론적으로 증명했습니다. 경험적으로 이미지에서 2×2 패치를 입력으로 가져왔지만 패치 크기가 작기 때문에 모델은 해상도가 낮은 이미지 데이터에만 적용할 수 있습니다.
Without specific constraints on patch size,vision Transformers(ViTs) extract patches from images and feed them into a Transformer encoder to obtain a global representation, which will finally be transformed for classification(Dosovitskiyet al., 2021). Notably, Transformers show better scalability than CNNs: when training larger models on larger datasets, vision Transformers outperform ResNets by a significant margin. Similar to the landscape of network architecture design in natural language processing, Transformers also became a game-changer in computer vision.
패치 크기에 대한 특정 제약 없이 vision Transformers(ViTs)는 이미지에서 패치를 추출하고 트랜스포머 인코더에 공급하여 최종적으로 분류를 위해 변환될 글로벌 representation을 얻습니다(Dosovitskiy et al., 2021). 특히 트랜스포머는 CNN보다 더 나은 확장성을 보여줍니다. 더 큰 데이터 세트에서 더 큰 모델을 교육할 때 비전 트랜스포머는 ResNets보다 훨씬 뛰어난 성능을 보입니다. 자연어 처리의 네트워크 아키텍처 설계 환경과 유사하게 Transformers도 컴퓨터 비전의 게임 체인저가 되었습니다.
import torch
from torch import nn
from d2l import torch as d2l
11.8.1.Model
Fig. 11.8.1depicts the model architecture of vision Transformers. This architecture consists of a stem that patchifies images, a body based on the multi-layer Transformer encoder, and a head that transforms the global representation into the output label.
그림 11.8.1은 비전 트랜스포머의 모델 아키텍처를 보여줍니다. 이 아키텍처는 이미지를 패치하는 stem, multi-layer Transformer encoder를 기반으로 하는 body, global representation을 output label로 변환하는 head로 구성됩니다.
Fig. 11.8.1 The vision Transformer architecture. In this example, an image is split into 9 patches. A special “<cls>” token and the 9 flattened image patches are transformed via patch embedding and n Transformer encoder blocks into 10 representations, respectively. The “<cls>” representation is further transformed into the output label.
Consider an input image with heightℎ, widthh, andwchannels. Specifying the patch height and width both asp, the image is split into a sequence ofm=ℎw/p^2patches, where each patch is flattened to a vector of lengthcp^2. In this way, image patches can be treated similarly to tokens in text sequences by Transformer encoders. A special “<cls>” (class) token and themflattened image patches are linearly projected into a sequence ofm+1vectors, summed with learnable positional embeddings. The multi-layer Transformer encoder transformsm+1input vectors into the same amount of output vector representations of the same length. It works exactly the same way as the original Transformer encoder inFig. 11.7.1, only differing in the position of normalization. Since the “<cls>” token attends to all the image patches via self-attention (seeFig. 11.6.1), its representation from the Transformer encoder output will be further transformed into the output label.
높이 ℎ, 너비 h 및 w 채널이 있는 입력 이미지를 고려하십시오. 패치 높이와 너비를 모두 p로 지정하면 이미지가 m=ℎw/p^2 패치 시퀀스로 분할되며 각 패치는 길이 cp^2의 벡터로 병합됩니다. 이러한 방식으로 이미지 패치는 Transformer 인코더에 의해 텍스트 시퀀스의 토큰과 유사하게 처리될 수 있습니다. 특수 "<cls>"(클래스) 토큰과 m개의 평면화된 이미지 패치는 학습 가능한 위치 임베딩으로 합산된 일련의 m+1 벡터로 선형 투영됩니다. 다층 트랜스포머 인코더는 m+1개의 입력 벡터를 같은 길이의 같은 양의 출력 벡터 표현representations으로 변환합니다. 정규화 위치만 다를 뿐 그림 11.7.1의 원래 Transformer 인코더와 정확히 동일한 방식으로 작동합니다. "<cls>" 토큰은 self-attention(그림 11.6.1 참조)을 통해 모든 이미지 패치에 attends하므로 Transformer 인코더 출력의 representation은 출력 레이블로 추가 변환됩니다.
Tip. Deep Learning에서 Feature와 Representation 이란?
In the context of deep learning, the terms "feature" and "representation" are closely related concepts, but they have slightly different meanings.
딥 러닝의 맥락에서 "특징"과 "표현"이라는 용어는 밀접한 관련이 있는 개념이지만, 약간의 차이가 있습니다.
Feature: A feature refers to a specific property, characteristic, or aspect of the input data that is relevant for solving a particular task. Features are often extracted or selected from raw data to provide meaningful and informative input to a machine learning or deep learning model. Features can be thought of as the input variables or attributes that the model uses to make predictions or decisions. In deep learning, features can be learned automatically through the layers of a neural network.
특징은 특정 작업을 해결하는 데 관련성 있는 입력 데이터의 특정 속성, 특성 또는 측면을 나타냅니다. 특징은 종종 원시 데이터에서 추출되거나 선택되어 기계 학습 또는 딥 러닝 모델에 의해 의미 있는 정보를 제공하는 입력을 제공합니다. 특징은 모델이 예측하거나 결정하는 데 사용하는 입력 변수 또는 속성으로 생각할 수 있습니다. 딥 러닝에서는 특징은 신경망의 레이어를 통해 자동으로 학습될 수 있습니다.
For example, in image recognition, features could be the presence of edges, corners, textures, or specific patterns within an image. In natural language processing, features could include the frequency of certain words or phrases in a text document.
예를 들어 이미지 인식에서 특징은 이미지 내의 가장자리, 모서리, 질감 또는 특정 패턴의 존재와 관련이 있을 수 있습니다. 자연어 처리에서 특징은 텍스트 문서에서 특정 단어 또는 구문의 빈도와 관련할 수 있습니다.
Representation: Representation, on the other hand, is a broader term that encompasses the entire encoding of the input data in a format that can be processed by a machine learning model. Representation refers to how the input data is transformed and structured to be compatible with the model's architecture and learning process. It includes both the extracted features and any additional transformation that might be applied to the data.
한편, 표현은 입력 데이터를 모델이 처리할 수 있는 형식으로 전체적으로 인코딩하는 것을 나타냅니다. 표현은 입력 데이터가 모델의 아키텍처 및 학습 과정과 호환되도록 변환되고 구조화된 방식을 포함합니다. 이것은 추출된 특징 및 데이터에 적용된 추가 변환을 모두 포함합니다.
In deep learning, representations are often learned hierarchically through the layers of neural networks. Each layer extracts increasingly abstract and complex features from the previous layer's representation, gradually building a more informative and discriminating representation of the input data. The final learned representation is then used for making predictions or classifications.
딥 러닝에서 표현은 종종 신경망의 레이어를 통해 계층적으로 학습됩니다. 각 레이어는 이전 레이어의 표현에서 점점 추상적이고 복잡한 특징을 추출하여 입력 데이터의 보다 의미 있는 표현을 점진적으로 구축합니다. 최종 학습된 표현은 예측이나 분류를 위해 사용됩니다.
In summary, features are specific characteristics of the data that are relevant to a task, while representation is the overall encoding of the data that captures relevant information and is used by the model for learning and making predictions.
요약하자면, 특징은 작업에 관련된 데이터의 특정 특성이며, 표현은 입력 데이터의 전체적인 인코딩으로써 관련 정보를 포착하고 모델의 학습과 예측에 사용되는 것입니다.
CNN에서 Channel 이란?
In Convolutional Neural Networks (CNNs), a "channel" refers to one of the dimensions of the input data and the corresponding learned filters. In the context of images, which are commonly used with CNNs, the term "channel" typically refers to the color channels or color planes of an image. Each channel represents a specific color component: red, green, and blue (RGB), in the case of a standard color image.
합성곱 신경망(CNN)에서 "채널"은 입력 데이터와 해당하는 학습된 필터의 차원 중 하나를 가리킵니다. 이미지와 함께 주로 사용되는 CNN의 맥락에서 "채널"이라는 용어는 일반적으로 이미지의 색상 채널 또는 컬러 플레인을 의미합니다. 각 채널은 특정한 색상 구성요소를 나타냅니다. 표준 컬러 이미지의 경우 빨강, 초록 및 파랑(RGB)에 해당하는 채널이 있습니다.
For example, in an RGB image, there are three color channels: one for red, one for green, and one for blue. Each channel contains pixel values that represent the intensity of the corresponding color component for each pixel in the image. These channels are stacked together to create the full color image.
예를 들어 RGB 이미지에서는 세 가지 색상 채널이 있습니다: 빨강, 초록, 파랑 각각에 하나씩입니다. 각 채널에는 이미지의 각 픽셀에 대한 해당 색상 구성요소의 강도를 나타내는 픽셀 값이 포함되어 있습니다. 이러한 채널은 함께 쌓여 전체 컬러 이미지를 생성합니다.
When a CNN processes an image, it performs convolution operations on each channel separately. The learned filters, also known as kernels, are applied to each channel to extract various features. The convolutional layers in a CNN are responsible for learning these filters and combining the information from different channels to detect patterns, textures, and structures in the input image.
CNN이 이미지를 처리할 때 각 채널별로 합성곱 연산을 수행합니다. 학습된 필터 또는 커널이 각 채널에 적용되어 입력 이미지의 다양한 특징을 추출합니다. CNN의 합성곱 레이어는 이러한 필터를 학습하고 서로 다른 채널의 정보를 결합하여 입력 이미지에서 패턴, 질감 및 구조를 감지합니다.
In summary, in CNNs, a channel refers to a separate color component or feature map in the input data, and they play a crucial role in capturing different aspects of the input data for feature extraction and pattern recognition.
요약하면, CNN에서 "채널"은 입력 데이터의 개별 색상 구성 요소 또는 특징 맵을 의미하며, 입력 데이터의 다양한 측면을 포착하여 특징 추출과 패턴 인식을 위한 중요한 역할을 합니다.
11.8.2.Patch Embedding
To implement a vision Transformer, let’s start with patch embedding inFig. 11.8.1. Splitting an image into patches and linearly projecting these flattened patches can be simplified as a single convolution operation, where both the kernel size and the stride size are set to the patch size.
비전 트랜스포머를 구현하기 위해 그림 11.8.1의 패치 임베딩부터 시작하겠습니다. 이미지를 패치로 분할하고 이러한 평면화된 패치를 선형으로 프로젝션하는 것은 커널 크기와 보폭 크기가 모두 패치 크기로 설정되는 단일 컨볼루션 작업으로 단순화될 수 있습니다.
class PatchEmbedding(nn.Module):
def __init__(self, img_size=96, patch_size=16, num_hiddens=512):
super().__init__()
def _make_tuple(x):
if not isinstance(x, (list, tuple)):
return (x, x)
return x
img_size, patch_size = _make_tuple(img_size), _make_tuple(patch_size)
self.num_patches = (img_size[0] // patch_size[0]) * (
img_size[1] // patch_size[1])
self.conv = nn.LazyConv2d(num_hiddens, kernel_size=patch_size,
stride=patch_size)
def forward(self, X):
# Output shape: (batch size, no. of patches, no. of channels)
return self.conv(X).flatten(2).transpose(1, 2)
이 코드는 이미지를 패치로 나누고 패치 임베딩을 수행하는 클래스인 PatchEmbedding을 정의하는 부분입니다.
PatchEmbedding 클래스의 생성자(__init__)는 세 가지 매개변수를 받습니다: img_size, patch_size, 그리고 num_hiddens. 이 클래스는 이미지의 크기를 img_size, 패치의 크기를 patch_size, 그리고 임베딩 차원을 num_hiddens로 설정하고 초기화됩니다.
_make_tuple 함수는 입력이 스칼라 또는 리스트/튜플인지 확인하고, 리스트 또는 튜플이 아니라면 입력을 스칼라로 만듭니다. 이 함수는 입력을 튜플로 변환해주는 역할을 합니다.
img_size와 patch_size는 _make_tuple 함수를 사용하여 튜플 형태로 변환됩니다. 이는 이미지의 크기와 패치의 크기가 각각 스칼라 또는 튜플 형태로 제공될 수 있기 때문입니다.
num_patches는 이미지 내에 생성되는 패치의 수를 나타냅니다. 이는 이미지의 세로 및 가로 방향에서 패치의 수를 곱하여 계산됩니다.
self.conv는 합성곱 레이어를 생성합니다. 이 레이어는 num_hiddens 차원의 커널을 사용하여 이미지에서 패치를 추출하게 됩니다. 이 때, kernel_size와 stride는 patch_size로 설정되어 패치의 크기에 맞게 이미지를 추출합니다.
forward 메서드는 주어진 이미지 X에 대해 패치 임베딩을 계산합니다. self.conv(X)는 이미지에서 패치를 추출하고, .flatten(2)는 패치의 차원을 펼치고 각 패치의 픽셀 값을 하나의 벡터로 만듭니다. .transpose(1, 2)는 차원을 바꿔서 결과를 반환하여, 출력의 형태는 (배치 크기, 패치 수, 임베딩 차원)이 됩니다.
이 PatchEmbedding 클래스는 이미지를 패치로 나눈 후 패치 임베딩을 계산하여 이미지 데이터를 임베딩된 벡터로 변환하는 역할을 수행합니다. 이러한 변환은 주로 트랜스포머 모델에서 사용되는 초기 입력 데이터 전처리 과정 중 하나입니다.
In the following example, taking images with height and width ofimg_sizeas inputs, the patch embedding outputs(img_size//patch_size)**2patches that are linearly projected to vectors of lengthnum_hiddens.
다음 예에서 높이와 너비가 img_size인 이미지를 입력으로 가져오면 패치 포함 출력(img_size//patch_size)**2 패치가 길이 num_hiddens의 벡터에 선형 투영됩니다.
위 코드는 PatchEmbedding 클래스를 사용하여 이미지 데이터를 패치 임베딩으로 변환하고, 그 결과의 형태를 확인하는 과정을 나타냅니다.
img_size, patch_size, num_hiddens, batch_size 변수들은 이미지 크기, 패치 크기, 임베딩 차원, 그리고 배치 크기를 설정합니다. 예를 들어 img_size가 96이면 이미지의 높이와 너비가 각각 96 픽셀로 가정됩니다.
PatchEmbedding 클래스의 객체 patch_emb를 생성합니다. 생성자에는 이미지 크기, 패치 크기, 그리고 임베딩 차원이 전달됩니다.
X는 형태가 (batch_size, 3, img_size, img_size)인 텐서로, 배치 크기만큼의 이미지 데이터를 나타냅니다. 여기서 3은 이미지의 채널 수를 나타냅니다. (예: 컬러 이미지의 경우 RGB 채널)
patch_emb(X)는 입력 이미지 X를 PatchEmbedding 클래스로 전달하여 패치 임베딩을 계산합니다. 결과로 얻은 텐서는 (batch_size, (img_size//patch_size)^2, num_hiddens) 형태를 가지게 됩니다. 이는 배치 크기, 패치 수, 그리고 각 패치의 임베딩 차원을 나타냅니다.
d2l.check_shape 함수는 실제로 계산된 결과와 기대하는 결과의 형태가 일치하는지 확인합니다. 기대하는 결과의 형태는 (batch_size, (img_size//patch_size)^2, num_hiddens)입니다.
11.8.3.Vision Transformer Encoder
The MLP of the vision Transformer encoder is slightly different from the position-wise FFN of the original Transformer encoder (seeSection 11.7.2). First, here the activation function uses the Gaussian error linear unit (GELU), which can be considered as a smoother version of the ReLU(Hendrycks and Gimpel, 2016). Second, dropout is applied to the output of each fully connected layer in the MLP for regularization.
비전 Transformer 엔코더의 MLP는 원래 Transformer 엔코더의 position-wise FFN과 약간 다릅니다(섹션 11.7.2 참조). 먼저 여기에서 활성화 함수는 ReLU의 부드러운 버전으로 간주될 수 있는 GELU(Gaussian error linear unit)를 사용합니다(Hendrycks and Gimpel, 2016). 둘째, 정규화를 위해 MLP의 각 fully connected layer의 출력에 드롭아웃이 적용됩니다.
위 코드는 ViT (Vision Transformer) 모델의 MLP (Multi-Layer Perceptron) 레이어를 정의한 ViTMLP 클래스를 나타냅니다.
mlp_num_hiddens은 MLP의 은닉 유닛 수를, mlp_num_outputs는 출력 차원 수를 의미합니다. dropout은 드롭아웃 비율을 설정하는 파라미터로 기본값은 0.5입니다.
ViTMLP 클래스의 생성자에서는 MLP의 레이어들과 활성화 함수인 GELU(Gaussian Error Linear Unit)를 설정합니다. GELU는 비선형 활성화 함수로 사용됩니다.
forward 메서드는 입력 데이터 x를 받아서 MLP 레이어들을 통과시켜 출력을 반환합니다.
실행 순서:
self.dense1(x) : 첫 번째 fully connected 레이어를 통과한 결과
self.gelu(...) : GELU 활성화 함수를 적용한 결과
self.dropout1(...) : 첫 번째 드롭아웃 레이어를 통과한 결과
self.dense2(...) : 두 번째 fully connected 레이어를 통과한 결과
self.dropout2(...) : 두 번째 드롭아웃 레이어를 통과한 최종 출력
결과적으로, forward 메서드를 통해 입력 x가 MLP를 통과하고 드롭아웃까지 적용된 출력이 반환됩니다. 이렇게 정의된 ViTMLP 클래스는 ViT 모델 내에서 MLP 레이어로 활용될 수 있습니다.
The vision Transformer encoder block implementation just follows the pre-normalization design inFig. 11.8.1, where normalization is applied rightbeforemulti-head attention or the MLP. In contrast to post-normalization (“add & norm” inFig. 11.7.1), where normalization is placed rightafterresidual connections, pre-normalization leads to more effective or efficient training for Transformers(Baevski and Auli, 2018,Wanget al., 2019,Xionget al., 2020).
vision Transformer encoder block implementation은 그림 11.8.1의 pre-normalization 설계를 따르며 정규화가 multi-head attention 또는 MLP 직전에 적용됩니다. residual connections 바로 뒤에 정규화가 배치되는 post-normalization(그림 11.7.1의 "추가 및 규범")와 달리 pre-normalization는 트랜스포머에 대한 보다 효과적이고 효율적인 교육으로 이어집니다(Baevski and Auli, 2018, Wang et al., 2019, Xiong et al., 2020).
위 코드는 ViT (Vision Transformer) 모델의 블록을 정의한 ViTBlock 클래스를 나타냅니다.
num_hiddens은 블록 내에서의 은닉 유닛 수를, norm_shape은 Layer Normalization을 위한 모양을, mlp_num_hiddens는 MLP의 은닉 유닛 수를, num_heads는 Multi-Head Attention의 헤드 개수를, dropout은 드롭아웃 비율을 나타냅니다. use_bias는 사용할 경우 편향을 사용하는지 여부를 나타내는 불리언 값입니다.
ViTBlock 클래스의 생성자에서는 레이어 정규화(nn.LayerNorm)와 Multi-Head Attention(d2l.MultiHeadAttention) 그리고 MLP(ViTMLP)을 설정합니다.
forward 메서드는 입력 데이터 X와 필요한 경우의 유효한 길이(valid_lens)를 받아서 블록을 통과시키고 출력을 반환합니다.
실행 순서:
self.ln1(X) : 입력 데이터에 레이어 정규화를 적용한 결과
self.attention(...): Multi-Head Attention 레이어를 통과시킨 결과
self.ln2(X): 입력 데이터에 레이어 정규화를 다시 적용한 결과
self.mlp(...): MLP 레이어를 통과시킨 결과
X + ...과 X + ...: 위 두 결과를 원본 입력 데이터에 더한 최종 출력
이렇게 정의된 ViTBlock 클래스는 Vision Transformer의 핵심 구성 요소 중 하나인 블록을 나타내며, 입력 데이터를 Multi-Head Attention과 MLP 레이어를 거치면서 변환하는 역할을 합니다.
Same as inSection 11.7.4, any vision Transformer encoder block does not change its input shape.
섹션 11.7.4에서와 마찬가지로 모든 비전 Transformer 인코더 블록은 입력 모양을 변경하지 않습니다.
encoder_blk.eval() : 블록을 평가 모드로 설정합니다. 평가 모드에서는 드롭아웃과 같이 학습 시에만 적용되는 연산들이 비활성화됩니다.
d2l.check_shape(encoder_blk(X), X.shape) : 생성한 encoder_blk에 입력 데이터 X를 전달하여 블록을 통과시킨 결과의 크기를 확인합니다. 이 결과가 입력 데이터의 크기와 동일해야 합니다.
즉, 위 코드는 ViTBlock 클래스로 생성한 블록에 입력 데이터를 넣고, 해당 블록을 통과시킨 결과의 크기가 입력 데이터의 크기와 일치하는지 확인하는 예시를 보여줍니다.
11.8.4.Putting It All Together
The forward pass of vision Transformers below is straightforward. First, input images are fed into anPatchEmbeddinginstance, whose output is concatenated with the “<cls>” token embedding. They are summed with learnable positional embeddings before dropout. Then the output is fed into the Transformer encoder that stacksnum_blksinstances of theViTBlockclass. Finally, the representation of the “<cls>” token is projected by the network head.
아래의 vision Transformers의 forward pass는 직관적입니다. 먼저 입력 이미지는 PatchEmbedding 인스턴스로 공급되며 출력은 "<cls>" 토큰 임베딩과 연결됩니다. 드롭아웃 전에 학습 가능한 positional embeddings으로 합산됩니다. 그런 다음 출력은 ViTBlock 클래스의 num_blks 인스턴스를 쌓는 Transformer 인코더로 공급됩니다. 마지막으로 “<cls>” 토큰의 representation은 network head에 의해 투영됩니다.
class ViT(d2l.Classifier):
"""Vision Transformer."""
def __init__(self, img_size, patch_size, num_hiddens, mlp_num_hiddens,
num_heads, num_blks, emb_dropout, blk_dropout, lr=0.1,
use_bias=False, num_classes=10):
super().__init__()
self.save_hyperparameters()
self.patch_embedding = PatchEmbedding(
img_size, patch_size, num_hiddens)
self.cls_token = nn.Parameter(torch.zeros(1, 1, num_hiddens))
num_steps = self.patch_embedding.num_patches + 1 # Add the cls token
# Positional embeddings are learnable
self.pos_embedding = nn.Parameter(
torch.randn(1, num_steps, num_hiddens))
self.dropout = nn.Dropout(emb_dropout)
self.blks = nn.Sequential()
for i in range(num_blks):
self.blks.add_module(f"{i}", ViTBlock(
num_hiddens, num_hiddens, mlp_num_hiddens,
num_heads, blk_dropout, use_bias))
self.head = nn.Sequential(nn.LayerNorm(num_hiddens),
nn.Linear(num_hiddens, num_classes))
def forward(self, X):
X = self.patch_embedding(X)
X = torch.cat((self.cls_token.expand(X.shape[0], -1, -1), X), 1)
X = self.dropout(X + self.pos_embedding)
for blk in self.blks:
X = blk(X)
return self.head(X[:, 0])
위 코드는 ViT 클래스를 정의하여 Vision Transformer 모델을 생성하는 과정을 보여주고 있습니다.
class ViT(d2l.Classifier): : d2l.Classifier를 상속하는 ViT 클래스를 정의합니다. 이 클래스는 Vision Transformer 모델을 나타냅니다.
def __init__(self, img_size, patch_size, num_hiddens, mlp_num_hiddens, num_heads, num_blks, emb_dropout, blk_dropout, lr=0.1, use_bias=False, num_classes=10): : 클래스 생성자입니다. 모델의 매개변수를 초기화하고 모델 구성을 설정합니다.
self.save_hyperparameters() : 클래스 내에서 정의된 하이퍼파라미터를 저장합니다.
self.patch_embedding = PatchEmbedding(img_size, patch_size, num_hiddens) : PatchEmbedding 클래스를 활용하여 이미지를 패치로 분할하고 임베딩하는 부분입니다.
self.cls_token = nn.Parameter(torch.zeros(1, 1, num_hiddens)) : 클래스 토큰을 위한 파라미터로, 이미지 내에서 특별한 의미를 갖는 토큰입니다.
self.pos_embedding = nn.Parameter(torch.randn(1, num_steps, num_hiddens)) : 위치 임베딩으로, 패치 위치에 대한 정보를 임베딩한 파라미터입니다.
self.dropout = nn.Dropout(emb_dropout) : 입력 임베딩에 대한 드롭아웃을 정의합니다.
self.blks = nn.Sequential() : 여러 개의 ViTBlock 레이어를 포함하는 시퀀셜 레이어를 정의합니다.
for i in range(num_blks): : 지정한 개수만큼 ViTBlock을 생성하여 self.blks에 추가합니다.
self.head = nn.Sequential(nn.LayerNorm(num_hiddens), nn.Linear(num_hiddens, num_classes)) : 분류를 위한 레이어를 정의합니다. 클래스 개수에 맞게 선형 레이어를 설정합니다.
def forward(self, X): : 모델의 순전파 연산을 정의합니다.
X = self.patch_embedding(X) : 입력 이미지를 패치 임베딩으로 변환합니다.
X = torch.cat((self.cls_token.expand(X.shape[0], -1, -1), X), 1) : 클래스 토큰을 임베딩된 패치와 연결합니다.
X = self.dropout(X + self.pos_embedding) : 입력 임베딩과 위치 임베딩을 더하고 드롭아웃을 적용합니다.
for blk in self.blks: : 모델 내의 모든 ViTBlock에 대해 루프를 실행하여 순차적으로 블록을 통과시킵니다.
return self.head(X[:, 0]) : 최종 결과를 분류 레이어에 통과시켜 예측 결과를 반환합니다.
이렇게 정의된 ViT 클래스는 입력 이미지에 대한 Vision Transformer 모델을 생성하고 해당 이미지의 클래스를 예측할 수 있는 모델을 만드는 데 사용될 수 있습니다.
11.8.5.Training
Training a vision Transformer on the Fashion-MNIST dataset is just like how CNNs were trained inSection 8.
Fashion-MNIST 데이터 세트로 비전 Transformer를 교육하는 것은 섹션 8에서 CNN을 교육한 것과 같습니다.
위 코드는 Vision Transformer 모델을 생성하고 FashionMNIST 데이터셋을 사용하여 모델을 학습시키는 과정을 보여주고 있습니다.
img_size, patch_size = 96, 16 : 이미지 크기와 패치 크기를 설정합니다.
num_hiddens, mlp_num_hiddens, num_heads, num_blks = 512, 2048, 8, 2 : 모델의 하이퍼파라미터인 은닉 유닛 수, MLP 은닉 유닛 수, 어텐션 헤드 수, 블록 수를 설정합니다.
emb_dropout, blk_dropout, lr = 0.1, 0.1, 0.1 : 입력 임베딩 드롭아웃 비율, 블록 드롭아웃 비율, 학습률을 설정합니다.
model = ViT(img_size, patch_size, num_hiddens, mlp_num_hiddens, num_heads, num_blks, emb_dropout, blk_dropout, lr) : 위에서 정의한 하이퍼파라미터들을 사용하여 ViT 모델을 생성합니다.
trainer = d2l.Trainer(max_epochs=10, num_gpus=1) : 학습을 위한 트레이너를 생성합니다. 최대 에포크 수와 GPU 개수를 설정합니다.
data = d2l.FashionMNIST(batch_size=128, resize=(img_size, img_size)) : FashionMNIST 데이터셋을 생성합니다. 배치 크기와 이미지 리사이즈 크기를 설정합니다.
trainer.fit(model, data) : 생성한 모델과 데이터셋을 이용하여 학습을 수행합니다. 트레이너의 fit 메서드를 사용하여 모델을 학습시킵니다.
이렇게 정의된 코드는 Vision Transformer 모델을 생성하고 FashionMNIST 데이터셋을 사용하여 모델을 학습시키는 예시를 보여줍니다.
11.8.6.Summary and Discussion
You may notice that for small datasets like Fashion-MNIST, our implemented vision Transformer does not outperform the ResNet inSection 8.6. Similar observations can be made even on the ImageNet dataset (1.2 million images). This is because Transformerslackthose useful principles in convolution, such as translation invariance and locality (Section 7.1). However, the picture changes when training larger models on larger datasets (e.g., 300 million images), where vision Transformers outperform ResNets by a large margin in image classification, demonstrating intrinsic superiority of Transformers in scalability(Dosovitskiyet al., 2021). The introduction of vision Transformers has changed the landscape of network design for modeling image data. They were soon shown effective on the ImageNet dataset with data-efficient training strategies of DeiT(Touvronet al., 2021). However, quadratic complexity of self-attention (Section 11.6) makes the Transformer architecture less suitable for higher-resolution images. Towards a general-purpose backbone network in computer vision, Swin Transformers addressed the quadratic computational complexity with respect to image size (Section 11.6.2) and added back convolution-like priors, extending the applicability of Transformers to a range of computer vision tasks beyond image classification with state-of-the-art results(Liuet al., 2021).
Fashion-MNIST와 같은 작은 데이터 세트의 경우 구현된 비전 Transformer가 섹션 8.6의 ResNet보다 성능이 좋지 않음을 알 수 있습니다. ImageNet 데이터 세트(120만 이미지)에서도 비슷한 관찰이 가능합니다. Transformers에는 변환 불변성 및 지역성(섹션 7.1)과 같은 컨볼루션의 유용한 원칙이 없기 때문입니다. 그러나 더 큰 데이터 세트(예: 3억 개의 이미지)에서 더 큰 모델을 교육할 때 그림이 변경됩니다. 여기서 비전 트랜스포머는 이미지 분류에서 ResNets를 훨씬 능가하여 확장성에서 트랜스포머의 본질적인 우월성을 보여줍니다(Dosovitskiy et al., 2021). 비전 트랜스포머의 도입으로 이미지 데이터 모델링을 위한 네트워크 설계의 환경이 바뀌었습니다. DeiT(Touvron et al., 2021)의 데이터 효율적인 교육 전략을 사용하여 ImageNet 데이터 세트에서 곧 효과적인 것으로 나타났습니다. 그러나 self-attention의 2차 복잡도(11.6절)는 Transformer 아키텍처를 고해상도 이미지에 적합하지 않게 만듭니다. 컴퓨터 비전의 범용 백본 네트워크를 향하기 위한 노력 중 Swin Transformers는 이미지 크기(섹션 11.6.2)와 관련하여 2차 계산 복잡성을 해결하고 convolution-like priors을 다시 추가하여 최신 결과로 이미지 분류를 넘어 다양한 컴퓨터 비전 작업으로 Transformers의 적용 가능성을 확장했습니다. (리우 외, 2021).
Swin Transformers 란?
Swin Transformer는 "Shifted Window Transformer"의 약자로, 컴퓨터 비전 분야에서 자연어 처리 모델인 Transformer 아키텍처를 적용한 최신의 딥 러닝 모델입니다. Swin Transformer는 이미지 분류, 객체 검출 및 분할과 같은 여러 컴퓨터 비전 작업에 사용되며, 특히 대규모 이미지 데이터셋에서 뛰어난 성능을 보이는 것으로 알려져 있습니다.
Swin Transformer의 주요 아이디어는 윈도우 기반의 셔틀 셋팅과 계층적 비트레이드 방법을 결합하여 높은 효율성과 확장성을 달성하는 것입니다. 이러한 방법을 사용하여 Swin Transformer는 큰 이미지를 처리하는 데도 우수한 성능을 발휘하면서도 기존의 비슷한 모델보다 더 적은 계산 비용을 필요로 합니다.
Swin Transformer의 주요 특징은 다음과 같습니다:
Hierarchical Architecture: Swin Transformer는 여러 계층으로 구성되어 있으며, 각 계층은 점진적으로 작아지는 윈도우 크기로 이미지를 처리합니다. 이 계층 구조는 다양한 스케일의 정보를 캡처하고 전역 및 로컬 패턴을 동시에 인식할 수 있는 능력을 제공합니다.
Shifted Windows: 기존의 이미지 분할 모델과는 달리 Swin Transformer는 이미지를 겹치는 윈도우로 나누어 처리합니다. 이것은 이미지의 모든 영역을 효율적으로 캡처하는 데 도움이 되며, 각 윈도우는 다른 윈도우의 정보를 사용하여 컨텍스트를 공유합니다.
Tokenization and Position Embeddings: Swin Transformer는 이미지를 토큰화하고 각 토큰에 위치 정보를 포함하는 포지션 임베딩을 추가합니다. 이를 통해 이미지를 시퀀스로 처리하는 Transformer 아키텍처를 적용할 수 있습니다.
비트레이드 압축: Swin Transformer는 계층 간에 비트레이드 압축을 사용하여 모델의 파라미터 수를 줄이고 메모리 사용량을 최적화합니다.
Swin Transformer는 컴퓨터 비전 분야에서 주목받는 최신 모델 중 하나로, 다양한 이미지 처리 작업에 유연하게 적용할 수 있는 강력한 아키텍처입니다.
11.8.7.Exercises
How does the value ofimg_sizeaffect training time?
Instead of projecting the “<cls>” token representation to the output, how to project the averaged patch representations? Implement this change and see how it affects the accuracy.
Can you modify hyperparameters to improve the accuracy of the vision Transformer?
We have compared CNNs, RNNs, and self-attention inSection 11.6.2. Notably, self-attention enjoys both parallel computation and the shortest maximum path length. Therefore naturally, it is appealing to design deep architectures by using self-attention. Unlike earlier self-attention models that still rely on RNNs for input representations(Chenget al., 2016,Linet al., 2017,Pauluset al., 2017), the Transformer model is solely based on attention mechanisms without any convolutional or recurrent layer(Vaswaniet al., 2017). Though originally proposed for sequence to sequence learning on text data, Transformers have been pervasive in a wide range of modern deep learning applications, such as in areas of language, vision, speech, and reinforcement learning.
섹션 11.6.2에서 CNN, RNN 및 self-attention을 비교했습니다. 특히 self-attention은 병렬 계산과 가장 짧은 최대 경로 길이를 모두 즐깁니다. 따라서 당연히 self-attention을 사용하여 심층적인 아키텍처를 설계하는 것이 매력적입니다. 입력 representations 에 대해 여전히 RNN에 의존하는 이전의 self-attention 모델(Cheng et al., 2016, Lin et al., 2017, Paulus et al., 2017)과 달리 Transformer 모델은 컨볼루션 또는 recurrent layer(Vaswani et al., 2017)에 없이 attention 메카니즘만을 사용합니다. 원래 텍스트 데이터에 대한 sequence to sequence learning을 위해 제안되었지만 트랜스포머는 언어, 시각, 음성 및 강화 학습 영역과 같은 광범위한 최신 딥 러닝 응용 프로그램에 널리 보급되었습니다.
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
11.7.1.Model
As an instance of the encoder-decoder architecture, the overall architecture of the Transformer is presented inFig. 11.7.1. As we can see, the Transformer is composed of an encoder and a decoder. Different from Bahdanau attention for sequence to sequence learning inFig. 11.4.2, the input (source) and output (target) sequence embeddings are added with positional encoding before being fed into the encoder and the decoder that stack modules based on self-attention.
인코더-디코더 아키텍처의 예로서 Transformer의 전체 아키텍처는 그림 11.7.1에 나와 있습니다. 보시다시피 Transformer는 인코더와 디코더로 구성됩니다. 그림 11.4.2의 sequence to sequence learning을 위한 Bahdanau 어텐션과 달리 입력(소스) 및 출력(타겟) 시퀀스 임베딩은 positional encoding이 추가된 후 셀프 어텐션을 기반으로 모듈을 쌓는 인코더 및 디코더에 공급됩니다. .
Fig. 11.7.1 The Transformer architecture.
Now we provide an overview of the Transformer architecture inFig. 11.7.1. On a high level, the Transformer encoder is a stack of multiple identical layers, where each layer has two sublayers (either is denoted assublayer). The first is a multi-head self-attention pooling and the second is a positionwise feed-forward network. Specifically, in the encoder self-attention, queries, keys, and values are all from the outputs of the previous encoder layer. Inspired by the ResNet design inSection 8.6, a residual connection is employed around both sublayers. In the Transformer, for any input x∈ℝ^dat any position of the sequence, we require thatsublayer(x)∈ℝ^dso that the residual connectionx+sublayer(x)∈ℝ^dis feasible. This addition from the residual connection is immediately followed by layer normalization(Baet al., 2016). As a result, the Transformer encoder outputs ad-dimensional vector representation for each position of the input sequence.
이제 그림 11.7.1에서 Transformer 아키텍처의 개요를 제공합니다. high level에서 Transformer 인코더는 여러 identical 레이어의 스택이며 각 레이어에는 두 개의 하위 레이어가 있습니다(둘 중 하나는 하위 레이어로 표시됨). 첫 번째는 multi-head self-attention pooling이고 두 번째는 positionwise feed-forward network입니다. 특히 인코더 self-attention에서 쿼리, 키 및 값은 모두 이전 인코더 계층의 출력에서 가져옵니다. 섹션 8.6의 ResNet 설계에서 영감을 받아 두 하위 계층 주위에 잔여 연결이 사용됩니다. Transformer에서 시퀀스의 임의 위치에 있는 입력 x∈ℝ^d에 대해 나머지 연결 x+sublayer(x)∈ℝ^d가 가능하도록 sublayer(x)∈ℝ^d가 필요합니다. 잔류 연결로부터의 이 추가는 즉시 계층 정규화로 이어집니다(Ba et al., 2016). 결과적으로 Transformer 인코더는 입력 시퀀스의 각 위치에 대한 d차원 벡터 표현을 출력합니다.
The Transformer decoder is also a stack of multiple identical layers with residual connections and layer normalizations. Besides the two sublayers described in the encoder, the decoder inserts a third sublayer, known as the encoder-decoder attention, between these two. In the encoder-decoder attention, queries are from the outputs of the previous decoder layer, and the keys and values are from the Transformer encoder outputs. In the decoder self-attention, queries, keys, and values are all from the outputs of the previous decoder layer. However, each position in the decoder is allowed to only attend to all positions in the decoder up to that position. Thismaskedattention preserves the auto-regressive property, ensuring that the prediction only depends on those output tokens that have been generated.
Transformer 디코더는 또한 residual connections 및 layer normalizations가 포함된 여러 identicallayers의 스택입니다. 인코더에 설명된 두 하위 계층 외에도 디코더는 이 두 계층 사이에 encoder-decoder attention라고 하는 세 번째 sublayer을 삽입합니다. encoder-decoder attention에서 쿼리는 이전 디코더 계층의 출력에서 가져오고키와 값은 Transformer 인코더 출력에서 가져옵니다. 디코더 self-attention에서 쿼리, 키 및 값은 모두 이전 디코더 계층의 출력에서 가져옵니다. 그러나 디코더의 각 위치는 해당 위치까지 디코더의 모든 위치에만 attend할 수 있습니다. 이 maskedattention는 auto-regressive property을 보존하여 generate 된 output token들에 대해서만 prediction 하도록 합니다.
We have already described and implemented multi-head attention based on scaled dot-products inSection 11.5and positional encoding inSection 11.6.3. In the following, we will implement the rest of the Transformer model.
우리는 섹션 11.5에서 scaled dot-products 과 섹션 11.6.3에서 positional encoding에 기반한 multi-head attention을 이미 설명하고 구현했습니다. 다음에서는 Transformer 모델의 나머지 부분을 구현합니다.
11.7.2.Positionwise Feed-Forward Networks
The positionwise feed-forward network transforms the representation at all the sequence positions using the same MLP. This is why we call itpositionwise. In the implementation below, the inputXwith shape (batch size, number of time steps or sequence length in tokens, number of hidden units or feature dimension) will be transformed by a two-layer MLP into an output tensor of shape (batch size, number of time steps,ffn_num_outputs).
positionwise feed-forward network는 동일한 MLP를 사용하여 모든 sequence positions에서 representation을 변환합니다. 그래서 우리는 이것을 positionwise라고 부르는 이유입니다. 아래 구현에서 shape(배치 크기, 시간 단계 수 또는 토큰의 시퀀스 길이, 숨겨진 단위 수 또는 기능 차원)이 있는 입력 X는 two-layer MLP에 의해 shape(배치 크기, 시간 단계 수, ffn_num_outputs의 출력 텐서로 변환됩니다.
위의 코드는 'PositionWiseFFN'이라는 클래스를 정의하고 있는 부분입니다. 이 클래스는 트랜스포머(Transformer)와 같은 모델의 구성 요소 중 하나인 Positionwise Feed-Forward Network(위치별 전방향 신경망)을 구현한 것입니다.
이 클래스의 목적은 각 위치별로 다른 출력을 생성하기 위해 특정 위치의 입력을 인코딩하는 역할을 합니다. 트랜스포머에서는 이러한 Positionwise FFN을 각 인코더 및 디코더 레이어 내에서 사용하여 입력 시퀀스의 각 요소에 대한 개별적인 변환을 수행합니다.
구체적으로 클래스는 다음과 같은 구성 요소를 가지고 있습니다:
nn.LazyLinear: 이 클래스는 선형 변환을 수행하는 레이어입니다. 여기서 ffn_num_hiddens 크기의 출력을 생성하는 첫 번째 레이어와, 이를 ffn_num_outputs 크기의 출력으로 변환하는 두 번째 레이어로 구성됩니다.
nn.ReLU: ReLU(렐루) 활성화 함수로서, 신경망의 비선형성을 추가합니다.
forward 메서드는 다음과 같은 과정을 거칩니다:
입력 X를 첫 번째 레이어인 dense1에 통과시켜 변환을 수행합니다.
변환된 출력에 ReLU 활성화 함수를 적용합니다.
ReLU를 통과한 출력을 두 번째 레이어인 dense2에 통과시켜 최종 출력을 생성합니다.
이렇게 구현된 Positionwise FFN은 트랜스포머 내에서 다양한 위치별 변환을 수행하는 데 사용되며, 모델의 특징을 추출하고 문맥 정보를 활용하는 데 도움을 줍니다.
The following example shows that the innermost dimension of a tensor changes to the number of outputs in the positionwise feed-forward network. Since the same MLP transforms at all the positions, when the inputs at all these positions are the same, their outputs are also identical.
다음 예제에서는 텐서의 innermost dimension이 positionwise feed-forward network안에서number of outputs로 변경됨을 보여줍니다. 동일한 MLP가 모든 위치에서 transforms되기 때문에 이러한 모든 위치의 입력이 동일하면 출력도 동일합니다.
위의 코드는 PositionWiseFFN 클래스의 인스턴스를 생성하고 해당 인스턴스에 입력 데이터를 전달하여 출력을 확인하는 부분입니다.
ffn = PositionWiseFFN(4, 8): PositionWiseFFN 클래스의 인스턴스를 생성합니다. 이 때 첫 번째 인자는 첫 번째 선형 레이어의 출력 크기(ffn_num_hiddens), 두 번째 인자는 두 번째 선형 레이어의 출력 크기(ffn_num_outputs)를 나타냅니다. 따라서 첫 번째 선형 레이어는 입력을 4차원으로 변환하고, 두 번째 선형 레이어는 이를 다시 8차원으로 변환합니다.
ffn.eval(): 모델을 평가 모드로 설정합니다. 평가 모드로 설정하면 드롭아웃과 같은 레이어들이 활성화되지 않으므로, 예측과 같은 작업에 사용됩니다.
ffn(torch.ones((2, 3, 4)))[0]: 2개의 샘플로 이루어진 미니배치에서 각 샘플은 3개의 위치와 4차원의 임베딩을 가진 입력을 생성합니다. 이 입력을 ffn에 전달하여 변환을 수행하고, 결과로 출력 벡터를 생성합니다. [0]을 사용하여 첫 번째 샘플의 결과만 선택합니다.
결과적으로, 입력에 대한 ffn의 변환을 확인할 수 있습니다. 이 코드에서는 입력 벡터의 각 위치에 대해 4차원에서 8차원으로 변환하는 작업이 수행되었습니다.
11.7.3.Residual Connection and Layer Normalization
Now let’s focus on the “add & norm” component inFig. 11.7.1. As we described at the beginning of this section, this is a residual connection immediately followed by layer normalization. Both are key to effective deep architectures.
이제 그림 11.7.1의 "add & norm" 구성 요소에 초점을 맞추겠습니다. 이 섹션의 시작 부분에서 설명한 것처럼 이것은 레이어 정규화가 바로 뒤따르는 잔류 연결입니다. 둘 다 효과적인 심층 아키텍처의 핵심입니다.
InSection 8.5, we explained how batch normalization recenters and rescales across the examples within a minibatch. As discussed inSection 8.5.2.3, layer normalization is the same as batch normalization except that the former normalizes across the feature dimension, thus enjoying benefits of scale independence and batch size independence. Despite its pervasive applications in computer vision, batch normalization is usually empirically less effective than layer normalization in natural language processing tasks, whose inputs are often variable-length sequences.
섹션 8.5에서 우리는 배치 정규화가 미니배치 내의 예제 전체에서 어떻게 중앙화 및 재조정되는지 설명했습니다. 섹션 8.5.2.3에서 논의된 바와 같이 레이어 정규화는 배치 정규화와 동일하지만 전자는 피처 차원 전체에서 정규화되므로 스케일 독립성과 배치 크기 독립성의 이점을 누릴 수 있습니다. 컴퓨터 비전의 광범위한 적용에도 불구하고 배치 정규화는 일반적으로 입력이 종종 가변 길이 시퀀스인 자연어 처리 작업의 계층 정규화보다 경험적으로 덜 효과적입니다.
The following code snippet compares the normalization across different dimensions by layer normalization and batch normalization.
다음 코드 스니펫은 레이어 정규화와 일괄 정규화를 통해 다양한 차원에서 정규화를 비교합니다.
ln = nn.LayerNorm(2)
bn = nn.LazyBatchNorm1d()
X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)
# Compute mean and variance from X in the training mode
print('layer norm:', ln(X), '\nbatch norm:', bn(X))
위의 코드는 PyTorch의 nn.LayerNorm과 nn.LazyBatchNorm1d 레이어를 사용하여 입력 데이터에 대한 정규화를 수행하고 결과를 출력하는 부분입니다.
ln = nn.LayerNorm(2): nn.LayerNorm 클래스의 인스턴스를 생성합니다. 2는 입력 데이터의 피처 차원을 의미합니다. 이 정규화 레이어는 입력 데이터의 피처 차원에 대해 평균과 표준편차를 계산하여 정규화합니다.
bn = nn.LazyBatchNorm1d(): nn.LazyBatchNorm1d 클래스의 인스턴스를 생성합니다. 이는 배치 정규화 레이어로, 학습 시 배치 단위로 평균과 표준편차를 계산하여 정규화합니다.
X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32): 입력 데이터 X를 생성합니다. 이 데이터는 2개의 샘플과 각 샘플은 2차원의 피처를 가진 형태입니다.
print('layer norm:', ln(X), '\nbatch norm:', bn(X)): 입력 데이터 X에 대해 레이어 정규화와 배치 정규화를 각각 수행한 결과를 출력합니다. ln(X)는 X에 대한 레이어 정규화 결과이며, bn(X)는 X에 대한 배치 정규화 결과입니다.
따라서 코드 실행 결과에서 레이어 정규화와 배치 정규화에 의해 변환된 입력 데이터를 확인할 수 있습니다.
In the context of the Transformer model, "Normalization" refers to techniques used to normalize the activations of neurons or layers within the model. Normalization methods help stabilize and speed up the training process of deep neural networks by ensuring that the input distribution to each layer remains relatively consistent. This can mitigate the vanishing gradient problem and help the model converge more effectively.
트랜스포머 모델의 맥락에서 "정규화(Normalization)"는 모델 내의 뉴런 또는 레이어의 활성화를 정규화하는 데 사용되는 기술을 의미합니다. 정규화 방법은 각 레이어 내에서 뉴런의 입력 분포를 비교적 일관되게 유지하도록 돕는 역할을 합니다. 이를 통해 사라지는 그래디언트 문제를 완화하고 모델의 수렴을 더 효과적으로 이끌어내는 데 도움이 됩니다.
Two common types of normalization used in the Transformer architecture are Layer Normalization and Batch Normalization:
트랜스포머 아키텍처에서 일반적으로 사용되는 정규화 종류는 두 가지입니다:
Layer Normalization (LN): Layer Normalization is applied independently to each element in the same layer, across all samples in a batch. It normalizes the mean and variance of the activations within a layer, helping to maintain a stable distribution of inputs. Layer Normalization is commonly used in the Transformer's multi-head self-attention and position-wise feedforward network.
레이어 정규화 (Layer Normalization, LN): 레이어 정규화는 동일한 레이어 내의 각 요소에 대해 독립적으로 적용되며, 배치 내 모든 샘플을 대상으로 정규화합니다. 레이어 내 활성화의 평균과 분산을 정규화하여 안정된 입력 분포를 유지하는 데 도움이 됩니다. 레이어 정규화는 주로 트랜스포머의 멀티헤드 셀프 어텐션과 위치별 피드포워드 네트워크에서 사용됩니다.
Batch Normalization (BN): Batch Normalization is applied to a batch of data. It computes the mean and variance across all samples in a batch and uses these statistics to normalize the activations. Batch Normalization can help improve training by reducing internal covariate shifts, which can make the optimization process more stable. However, in the context of the Transformer, where sequence length can vary across batches, using Batch Normalization directly might not be suitable due to the varying sequence lengths.
배치 정규화 (Batch Normalization, BN): 배치 정규화는 데이터 배치에 적용됩니다. 배치 내 모든 샘플을 대상으로 평균과 분산을 계산하고, 이 통계치를 사용하여 활성화를 정규화합니다. 배치 정규화는 내부 공분산 변화(internal covariate shift)를 줄이는 데 도움이 되어 최적화 과정을 더 안정적으로 만들 수 있습니다. 그러나 배치의 시퀀스 길이가 다양한 트랜스포머의 맥락에서는 배치 정규화를 직접 사용하는 것이 적합하지 않을 수 있습니다.
Normalization techniques are important for training deep neural networks, including the Transformer, as they contribute to better convergence, faster training, and more stable gradient propagation. They are crucial components in ensuring the effectiveness of the model's self-attention and feedforward operations.
정규화 기술은 트랜스포머를 비롯한 딥 뉴럴 네트워크의 훈련에 중요한 역할을 하며, 더 나은 수렴, 빠른 훈련 및 안정된 그래디언트 전파에 기여합니다. 이는 모델의 셀프 어텐션과 피드포워드 작업의 효과적인 수행을 보장하는 데 핵심적인 구성 요소입니다.
Now we can implement theAddNormclass using a residual connection followed by layer normalization. Dropout is also applied for regularization.
이제 residual connection과 layer normalization를 사용하여 AddNorm 클래스를 구현할 수 있습니다. 드롭아웃은 정규화에도 적용됩니다.
class AddNorm(nn.Module): #@save
"""The residual connection followed by layer normalization."""
def __init__(self, norm_shape, dropout):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(norm_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
위 코드는 레이어 정규화를 적용한 잔차 연결(Residual Connection)을 나타내는 클래스인 AddNorm을 정의하는 부분입니다. 이 클래스는 트랜스포머 내의 블록 구조에서 많이 사용되며, 잔차 연결과 레이어 정규화를 결합하여 네트워크의 안정성과 수렴을 향상시키는 역할을 수행합니다.
이 클래스의 주요 요소들을 한 줄씩 설명해보겠습니다.
class AddNorm(nn.Module):: AddNorm 클래스를 정의하는 시작 부분입니다.
def __init__(self, norm_shape, dropout):: 클래스의 생성자(Constructor)입니다. norm_shape은 레이어 정규화를 적용할 때 사용되는 차원의 모양(shape)을 의미하며, dropout은 드롭아웃 비율을 나타냅니다.
super().__init__(): 상위 클래스 nn.Module의 생성자를 호출하여 초기화합니다.
self.dropout = nn.Dropout(dropout): 드롭아웃을 적용하기 위한 nn.Dropout 레이어를 생성하고 클래스 내 변수 dropout에 할당합니다.
self.ln = nn.LayerNorm(norm_shape): 레이어 정규화를 적용하기 위한 nn.LayerNorm 레이어를 생성하고 클래스 내 변수 ln에 할당합니다.
def forward(self, X, Y):: 순방향 전달 메서드입니다. X는 입력 데이터, Y는 잔차 연결 블록의 출력 데이터입니다.
return self.ln(self.dropout(Y) + X): 잔차 연결과 레이어 정규화를 수행한 결과를 반환합니다. 먼저 드롭아웃이 적용된 Y와 입력 데이터 X를 더한 다음, 이를 레이어 정규화(self.ln)에 통과시켜 최종 출력을 얻습니다.
이러한 AddNorm 클래스는 트랜스포머의 다양한 부분에서 재사용되며, 잔차 연결과 레이어 정규화를 조합하여 모델의 안정성과 훈련 속도를 향상시키는 데 기여합니다.
The residual connection requires that the two inputs are of the same shape so that the output tensor also has the same shape after the addition operation.
residual connection은 덧셈 연산 후에 출력 텐서도 같은 모양을 갖도록 두 입력이 같은 모양이어야 합니다.
shape = (2, 3, 4): 입력 데이터의 모양(shape)을 정의합니다. 이 경우 (batch_size=2, sequence_length=3, hidden_size=4)의 3D 텐서 모양으로 설정합니다.
d2l.check_shape(...): 입력 데이터를 add_norm에 전달하고 결과의 모양을 확인하는 도우미 함수입니다.
add_norm(torch.ones(shape), torch.ones(shape)): 입력 데이터로 torch.ones 함수를 사용하여 생성한 텐서를 add_norm에 전달합니다. 이렇게 하면 잔차 연결과 레이어 정규화가 적용된 결과가 반환됩니다.
shape): 기대되는 결과의 모양입니다. 앞서 정의한 shape과 동일한 (2, 3, 4) 모양을 가집니다.
이 코드의 목적은 AddNorm 클래스가 올바르게 작동하는지 확인하는 것입니다. add_norm에 입력 데이터를 전달하고 출력의 모양이 기대한대로인지 확인하여, 잔차 연결과 레이어 정규화가 정확하게 수행되는지 검증합니다.
11.7.4.Encoder
With all the essential components to assemble the Transformer encoder, let’s start by implementing a single layer within the encoder. The followingTransformerEncoderBlockclass contains two sublayers: multi-head self-attention and positionwise feed-forward networks, where a residual connection followed by layer normalization is employed around both sublayers.
Transformer 인코더를 조립하는 데 필요한 모든 필수 구성 요소를 사용하여 인코더 내에서 단일 레이어를 구현하는 것부터 시작하겠습니다. 다음 TransformerEncoderBlock 클래스에는 multi-head self-attention 및 positionwise feed-forward networks의 두 sublayers이 포함되어 있습니다. 여기에서 두 sublayers 주위에 layer normalization가 뒤따르는 residual connection이 사용됩니다.
위 코드는 TransformerEncoderBlock 클래스의 동작을 테스트하는 부분입니다.
X = torch.ones((2, 100, 24)): 크기가 (2, 100, 24)인 입력 데이터 X를 생성합니다. 이는 미니배치 크기가 2, 시퀀스 길이가 100, 피처 차원이 24인 데이터입니다.
valid_lens = torch.tensor([3, 2]): 유효한 시퀀스 길이를 나타내는 텐서를 생성합니다. 이 예에서 첫 번째 시퀀스의 길이는 3, 두 번째 시퀀스의 길이는 2입니다.
encoder_blk = TransformerEncoderBlock(24, 48, 8, 0.5): TransformerEncoderBlock 클래스를 생성합니다. 인코더 블록의 입력 차원은 24, 피드포워드 신경망의 은닉 상태 크기는 48, 어텐션 헤드 수는 8, 드롭아웃 비율은 0.5로 설정됩니다.
encoder_blk.eval(): 모델을 평가 모드로 설정합니다. 이는 드롭아웃 레이어 등의 동작을 평가 모드로 변경하여 예측 결과의 안정성을 높이는 역할을 합니다.
d2l.check_shape(encoder_blk(X, valid_lens), X.shape): encoder_blk에 입력 데이터 X와 유효한 시퀀스 길이 valid_lens를 입력하여 인코더 블록을 테스트합니다. 그 결과로 얻은 출력의 형상을 기존 입력 데이터 X의 형상과 비교하여 일치하는지를 확인합니다. 이를 통해 인코더 블록이 올바르게 동작하는지 검증합니다.
In the following Transformer encoder implementation, we stacknum_blksinstances of the aboveTransformerEncoderBlockclasses. Since we use the fixed positional encoding whose values are always between -1 and 1, we multiply values of the learnable input embeddings by the square root of the embedding dimension to rescale before summing up the input embedding and the positional encoding.
다음 Transformer Encoder 구현에서는 위의 TransformerEncoderBlock 클래스의 num_blks 인스턴스를 쌓습니다. 값이 항상 -1과 1 사이인 fixed positional encoding을 사용하기 때문에 input embedding과 positional encoding을 합산하기 전에 학습 가능한 input embedding의 값에 embedding dimension의 제곱근을 곱하여 크기를 조정합니다.
class TransformerEncoder(d2l.Encoder): #@save
"""The Transformer encoder."""
def __init__(self, vocab_size, num_hiddens, ffn_num_hiddens,
num_heads, num_blks, dropout, use_bias=False):
super().__init__()
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_blks):
self.blks.add_module("block"+str(i), TransformerEncoderBlock(
num_hiddens, ffn_num_hiddens, num_heads, dropout, use_bias))
def forward(self, X, valid_lens):
# Since positional encoding values are between -1 and 1, the embedding
# values are multiplied by the square root of the embedding dimension
# to rescale before they are summed up
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[
i] = blk.attention.attention.attention_weights
return X
위 코드는 TransformerEncoder 클래스의 정의입니다. 이 클래스는 Transformer의 인코더 부분을 구성합니다.
vocab_size, num_hiddens, ffn_num_hiddens, num_heads, num_blks, dropout, use_bias=False: 다양한 매개변수들이 클래스의 생성자에 전달됩니다. 이들은 인코더의 구성 및 하이퍼파라미터 설정에 사용됩니다.
self.embedding = nn.Embedding(vocab_size, num_hiddens): 입력 토큰을 임베딩하기 위한 임베딩 레이어를 생성합니다. 임베딩 차원은 num_hiddens로 설정됩니다.
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout): 위치 인코딩을 수행하기 위한 위치 인코딩 레이어를 생성합니다. 위치 인코딩은 임베딩 된 토큰 벡터에 추가되어 위치 정보를 제공합니다.
self.blks = nn.Sequential(): 여러 개의 TransformerEncoderBlock 블록을 연결하여 시퀀스를 처리하는데 사용됩니다. nn.Sequential을 사용하여 블록을 연결합니다.
for i in range(num_blks): ...: 입력으로 받은 num_blks 수만큼 루프를 돌며 TransformerEncoderBlock 블록을 추가합니다. 블록의 인수들은 클래스 생성자로부터 전달받은 하이퍼파라미터들로 설정됩니다.
def forward(self, X, valid_lens): ...: 인코더의 순전파를 정의합니다. 입력 X와 유효한 시퀀스 길이 valid_lens를 받아서 처리한 후 결과를 반환합니다. 순전파 과정에서 임베딩, 위치 인코딩, 그리고 여러 개의 TransformerEncoderBlock 블록을 순차적으로 통과하게 됩니다.
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens)): 입력 X를 임베딩하고 위치 인코딩을 적용합니다. 임베딩 된 토큰 벡터에 위치 인코딩을 더하고, 임베딩 차원의 제곱근을 곱해줍니다.
self.attention_weights = [None] * len(self.blks): 각 블록의 어텐션 가중치를 저장하는 빈 리스트를 생성합니다.
for i, blk in enumerate(self.blks): ...: 연결된 블록들을 순회하며 각 블록에 X와 유효한 시퀀스 길이 valid_lens를 입력으로 전달하여 순전파를 수행합니다. 또한, 각 블록의 어텐션 가중치를 self.attention_weights에 저장합니다.
return X: 최종적으로 모든 블록을 통과한 결과를 반환합니다.
Below we specify hyperparameters to create a two-layer Transformer encoder. The shape of the Transformer encoder output is (batch size, number of time steps,num_hiddens).
아래에서 하이퍼파라미터를 지정하여 2계층 트랜스포머 인코더를 생성합니다. Transformer 인코더 출력의 shape은 (배치 크기, 시간 단계 수, num_hiddens)입니다.
위 코드는 TransformerEncoder 클래스의 인스턴스를 생성하고, 해당 인스턴스를 사용하여 입력 데이터의 인코딩을 계산하고 결과의 형상을 확인하는 과정을 나타냅니다.
encoder = TransformerEncoder(200, 24, 48, 8, 2, 0.5): TransformerEncoder 클래스의 인스턴스를 생성합니다. 생성자에 다양한 하이퍼파라미터를 전달하여 인코더의 구성을 설정합니다. 여기서는 입력 어휘 크기(vocab_size)를 200, 은닉 차원(num_hiddens)을 24, 피드포워드 신경망 내부 은닉 차원(ffn_num_hiddens)을 48, 어텐션 헤드 수(num_heads)를 8, 블록 수(num_blks)를 2, 드롭아웃 비율(dropout)을 0.5로 설정합니다.
d2l.check_shape(encoder(torch.ones((2, 100), dtype=torch.long), valid_lens),(2, 100, 24)): 생성한 인코더 객체를 사용하여 입력 데이터의 인코딩을 계산하고 결과의 형상을 확인합니다. 여기서는 입력 데이터의 형상을 (2, 100)로 가정하고, 유효한 시퀀스 길이 정보인 valid_lens를 함께 전달합니다. 그 결과로 얻은 인코딩의 형상을 (2, 100, 24)로 확인합니다.
11.7.5.Decoder
As shown inFig. 11.7.1, the Transformer decoder is composed of multiple identical layers. Each layer is implemented in the followingTransformerDecoderBlockclass, which contains three sublayers: decoder self-attention, encoder-decoder attention, and positionwise feed-forward networks. These sublayers employ a residual connection around them followed by layer normalization.
그림 11.7.1과 같이 Transformer 디코더는 여러 개의 동일한(identical) 레이어로 구성됩니다. 각 계층은 다음 TransformerDecoderBlock 클래스에서 구현되며 여기에는, decoder self-attention, encoder-decoder attention 및 positionwise feed-forward networks 등 세 가지 sublayers이 포함됩니다. 이러한 sublayers은 layer normalization가 뒤따르는 잔여 연결(residual connection)을 사용합니다.
As we described earlier in this section, in the masked multi-head decoder self-attention (the first sublayer), queries, keys, and values all come from the outputs of the previous decoder layer. When training sequence-to-sequence models, tokens at all the positions (time steps) of the output sequence are known. However, during prediction the output sequence is generated token by token; thus, at any decoder time step only the generated tokens can be used in the decoder self-attention. To preserve auto-regression in the decoder, its masked self-attention specifiesdec_valid_lensso that any query only attends to all positions in the decoder up to the query position.
이 섹션의 앞부분에서 설명한 것처럼 masked multi-head decoder 에서 self-attention(첫 번째 하위 계층), 쿼리, 키 및 값은 모두 이전 디코더 계층의 출력에서 옵니다. sequence-to-sequence 모델을 교육할 때 출력 시퀀스의 모든 위치(시간 단계)에 있는 토큰이 알려져 있습니다. 그러나 예측 중에는 출력 시퀀스가 토큰별로 생성됩니다. 따라서 모든 디코더 시간 단계에서 생성된 토큰만 decoder self-attention에서 사용할 수 있습니다. 디코더에서 자동 회귀 auto-regression를 유지하기 위해 masked self-attention는 모든 쿼리가 디코더의 해당 쿼리까지의 모든 positions에만 attends하도록 dec_valid_lens를 지정합니다.
class TransformerDecoderBlock(nn.Module):
# The i-th block in the Transformer decoder
def __init__(self, num_hiddens, ffn_num_hiddens, num_heads, dropout, i):
super().__init__()
self.i = i
self.attention1 = d2l.MultiHeadAttention(num_hiddens, num_heads,
dropout)
self.addnorm1 = AddNorm(num_hiddens, dropout)
self.attention2 = d2l.MultiHeadAttention(num_hiddens, num_heads,
dropout)
self.addnorm2 = AddNorm(num_hiddens, dropout)
self.ffn = PositionWiseFFN(ffn_num_hiddens, num_hiddens)
self.addnorm3 = AddNorm(num_hiddens, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_lens = state[0], state[1]
# During training, all the tokens of any output sequence are processed
# at the same time, so state[2][self.i] is None as initialized. When
# decoding any output sequence token by token during prediction,
# state[2][self.i] contains representations of the decoded output at
# the i-th block up to the current time step
if state[2][self.i] is None:
key_values = X
else:
key_values = torch.cat((state[2][self.i], X), dim=1)
state[2][self.i] = key_values
if self.training:
batch_size, num_steps, _ = X.shape
# Shape of dec_valid_lens: (batch_size, num_steps), where every
# row is [1, 2, ..., num_steps]
dec_valid_lens = torch.arange(
1, num_steps + 1, device=X.device).repeat(batch_size, 1)
else:
dec_valid_lens = None
# Self-attention
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
# Encoder-decoder attention. Shape of enc_outputs:
# (batch_size, num_steps, num_hiddens)
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Z)), state
위 코드는 TransformerDecoderBlock 클래스를 정의하는 부분으로, Transformer 디코더 블록의 동작을 정의하고 있습니다. 이 블록은 Transformer 디코더 내에서 하나의 레이어를 나타내며, 여러 디코더 블록들이 연결되어 전체 디코더를 형성합니다.
def __init__(self, num_hiddens, ffn_num_hiddens, num_heads, dropout, i): 디코더 블록의 생성자입니다. 다양한 하이퍼파라미터들과 블록의 순서를 나타내는 i 값을 받습니다.
self.attention1 = d2l.MultiHeadAttention(num_hiddens, num_heads, dropout): 첫 번째 세트의 멀티헤드 어텐션을 생성합니다. 자기 어텐션입니다.
self.addnorm1 = AddNorm(num_hiddens, dropout): 첫 번째 레이어 정규화와 잔차 연결을 위한 클래스 AddNorm을 생성합니다.
self.attention2 = d2l.MultiHeadAttention(num_hiddens, num_heads, dropout): 두 번째 세트의 멀티헤드 어텐션을 생성합니다. 인코더-디코더 어텐션입니다.
self.addnorm2 = AddNorm(num_hiddens, dropout): 두 번째 레이어 정규화와 잔차 연결을 위한 클래스 AddNorm을 생성합니다.
self.ffn = PositionWiseFFN(ffn_num_hiddens, num_hiddens): 포지션 와이즈 피드포워드 네트워크를 생성합니다.
self.addnorm3 = AddNorm(num_hiddens, dropout): 세 번째 레이어 정규화와 잔차 연결을 위한 클래스 AddNorm을 생성합니다.
def forward(self, X, state): 디코더 블록의 순전파 함수입니다. 입력 데이터 X와 이전 상태 state를 받습니다.
enc_outputs, enc_valid_lens = state[0], state[1]: 상태에서 인코더 출력과 유효한 시퀀스 길이를 가져옵니다.
if state[2][self.i] is None:: 디코딩 중인 경우와 훈련 중인 경우에 따라서 어텐션 키 밸류 값을 설정합니다.
if self.training:: 훈련 중인 경우입니다.
batch_size, num_steps, _ = X.shape: 입력 데이터의 배치 크기와 시퀀스 길이를 가져옵니다.
dec_valid_lens = torch.arange(1, num_steps + 1, device=X.device).repeat(batch_size, 1): 훈련 중인 경우, 유효한 시퀀스 길이 정보를 생성합니다.
X2 = self.attention1(X, key_values, key_values, dec_valid_lens): 자기 어텐션 연산을 수행합니다.
Y = self.addnorm1(X, X2): 첫 번째 어텐션 결과와 입력 데이터를 더하고 레이어 정규화를 수행합니다.
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens): 인코더-디코더 어텐션 연산을 수행합니다.
Z = self.addnorm2(Y, Y2): 두 번째 어텐션 결과와 이전 결과를 더하고 레이어 정규화를 수행합니다.
return self.addnorm3(Z, self.ffn(Z)), state: 세 번째 어텐션 결과와 포지션 와이즈 피드포워드 네트워크를 수행한 결과를 더하고 레이어 정규화를 수행한 최종 결과와 상태를 반환합니다.
To facilitate scaled dot-product operations in the encoder-decoder attention and addition operations in the residual connections, the feature dimension (num_hiddens) of the decoder is the same as that of the encoder.
인코더-디코더 어텐션에서 scaled dot-product operations와 residual connections에서 addition operations을 용이하게 하기 위해 디코더의 feature dimension(num_hiddens)은 인코더의 feature dimension과 동일합니다.
위 코드는 TransformerDecoderBlock 클래스의 인스턴스를 생성하고, 디코더 블록의 순전파를 통해 출력의 형상을 확인하는 과정을 보여주고 있습니다.
decoder_blk = TransformerDecoderBlock(24, 48, 8, 0.5, 0): 디코더 블록 클래스 TransformerDecoderBlock의 인스턴스를 생성합니다. 이 때 필요한 하이퍼파라미터들을 설정합니다.
X = torch.ones((2, 100, 24)): 입력 데이터 X를 생성합니다. 이 예시에서는 2개의 배치, 100개의 시퀀스 길이, 그리고 24차원의 임베딩을 가지는 입력 데이터를 생성합니다.
state = [encoder_blk(X, valid_lens), valid_lens, [None]]: 인코더 블록의 순전파를 통해 인코더의 출력과 유효한 시퀀스 길이를 가지는 상태를 생성합니다. 마지막 리스트는 초기에 디코더 블록 내에서 사용하는 어텐션 키 밸류 값입니다.
d2l.check_shape(decoder_blk(X, state)[0], X.shape): 디코더 블록의 순전파를 통해 출력의 형상을 확인합니다. 디코더 블록의 입력으로 X와 이전 상태 state를 주고, 출력의 형상을 입력 데이터 X의 형상과 비교합니다.
Now we construct the entire Transformer decoder composed ofnum_blksinstances ofTransformerDecoderBlock. In the end, a fully connected layer computes the prediction for all thevocab_sizepossible output tokens. Both of the decoder self-attention weights and the encoder-decoder attention weights are stored for later visualization.
이제 TransformerDecoderBlock의 num_blks 인스턴스로 구성된 전체 Transformer 디코더를 구성합니다. 마지막에 fully connected layer 모든 vocab_size 가능한 출력 토큰에 대한 예측을 계산합니다. self-attention weights와 encoder-decoder attention weights 모두 나중에 시각화하기 위해 저장됩니다.
class TransformerDecoder(d2l.AttentionDecoder):
def __init__(self, vocab_size, num_hiddens, ffn_num_hiddens, num_heads,
num_blks, dropout):
super().__init__()
self.num_hiddens = num_hiddens
self.num_blks = num_blks
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_blks):
self.blks.add_module("block"+str(i), TransformerDecoderBlock(
num_hiddens, ffn_num_hiddens, num_heads, dropout, i))
self.dense = nn.LazyLinear(vocab_size)
def init_state(self, enc_outputs, enc_valid_lens):
return [enc_outputs, enc_valid_lens, [None] * self.num_blks]
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range (2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
# Decoder self-attention weights
self._attention_weights[0][
i] = blk.attention1.attention.attention_weights
# Encoder-decoder attention weights
self._attention_weights[1][
i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights
위 코드는 TransformerDecoder 클래스를 정의하고, 해당 디코더의 동작을 구현한 것입니다.
class TransformerDecoder(d2l.AttentionDecoder): TransformerDecoder 클래스를 정의하며, d2l.AttentionDecoder 클래스를 상속받습니다. 이 클래스는 어텐션 메커니즘을 사용하는 디코더를 나타냅니다.
def init_state(self, enc_outputs, enc_valid_lens): 디코더의 상태를 초기화하는 함수입니다. 인코더의 출력과 유효한 시퀀스 길이를 받아 초기 상태를 생성합니다.
def forward(self, X, state): 순전파 함수를 정의합니다. 입력 X와 현재 상태 state를 받아 디코더 블록들을 통과시키고, 디코더의 출력과 다음 상태를 반환합니다. 각 블록에서의 어텐션 가중치를 _attention_weights에 저장합니다.
@property 데코레이터를 통해 attention_weights 함수를 프로퍼티로 정의합니다. 이 함수는 _attention_weights를 반환하며, 각 블록에서의 어텐션 가중치를 포함합니다.
11.7.6.Training
Let’s instantiate an encoder-decoder model by following the Transformer architecture. Here we specify that both the Transformer encoder and the Transformer decoder have 2 layers using 4-head attention. Similar toSection 10.7.6, we train the Transformer model for sequence to sequence learning on the English-French machine translation dataset.
Transformer 아키텍처를 따라 인코더-디코더 모델을 인스턴스화해 보겠습니다. 여기서 우리는 Transformer 인코더와 Transformer 디코더 모두 4-head Attention을 사용하는 2개의 레이어를 가지도록 설정합니다. 섹션 10.7.6과 유사하게 영어-프랑스어 기계 번역 데이터 세트에서 sequence to sequence 학습을 위해 Transformer 모델을 훈련합니다.
model = d2l.Seq2Seq(...): Seq2Seq 모델을 생성합니다. 인코더, 디코더, 타겟 패딩 토큰 ID, 학습률 등을 설정합니다.
trainer = d2l.Trainer(...): 모델 학습을 위한 트레이너를 생성합니다. 최대 에포크 수, 그래디언트 클리핑 값, GPU 개수 등을 설정합니다.
trainer.fit(model, data): 트레이너를 사용하여 모델을 데이터에 학습시킵니다.
After training, we use the Transformer model to translate a few English sentences into French and compute their BLEU scores.
학습 후 Transformer 모델을 사용하여 몇 개의 영어 문장을 프랑스어로 번역하고 BLEU 점수를 계산합니다.
engs = ['go .', 'i lost .', 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(
data.build(engs, fras), d2l.try_gpu(), data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '<eos>':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{d2l.bleu(" ".join(translation), fr, k=2):.3f}')
위 코드는 학습된 기계 번역 Transformer 모델을 사용하여 주어진 영어 문장을 프랑스어로 번역하고 BLEU 점수를 계산하는 과정을 나타냅니다.
engs와 fras: 번역할 영어 문장과 정답 프랑스어 문장들의 리스트입니다.
preds, _ = model.predict_step(...): 학습된 모델을 사용하여 주어진 영어 문장을 프랑스어로 번역합니다. data.build 함수를 사용하여 입력 데이터를 생성하고, d2l.try_gpu()를 통해 GPU를 사용하도록 설정합니다. data.num_steps는 문장의 최대 길이입니다. 번역 결과와 기타 정보가 preds와 _ 변수에 저장됩니다.
for en, fr, p in zip(engs, fras, preds):: 번역된 결과를 영어 문장, 정답 프랑스어 문장, 번역된 프랑스어 문장과 함께 루프로 반복합니다.
translation = []: 번역된 프랑스어 문장을 저장할 빈 리스트를 생성합니다.
for token in data.tgt_vocab.to_tokens(p):: 번역된 프랑스어 문장의 토큰을 하나씩 확인합니다.
if token == '<eos>':: 토큰이 <eos> (문장 종료 토큰)인 경우 반복을 종료합니다.
print(f'{en} => {translation}, bleu, ...: 영어 문장, 번역된 프랑스어 문장, BLEU 점수를 출력합니다. BLEU 점수는 d2l.bleu 함수를 사용하여 계산하며, 정답 프랑스어 문장과 번역된 프랑스어 문장을 비교합니다.
After training, we use the Transformer model to [translate a few English sentences] into French and compute their BLEU scores.
훈련 후에는 Transformer 모델을 사용하여 영어 문장 몇 개를 프랑스어로 번역하고 BLEU 점수를 계산합니다.
go . => ['va', '!'], bleu,1.000
i lost . => ["j'ai", 'perdu', '.'], bleu,1.000
he's calm . => ['calme', '.'], bleu,0.368
i'm home . => ['je', 'suis', 'chez', 'moi', '.'], bleu,1.000
Let’s visualize the Transformer attention weights when translating the last English sentence into French. The shape of the encoder self-attention weights is (number of encoder layers, number of attention heads,num_stepsor number of queries,num_stepsor number of key-value pairs).
마지막 영어 문장을 프랑스어로 번역할 때 Transformer attention weights를 시각화해 보겠습니다. 인코더 self-attention weights의 형태는 (인코더 레이어 수, 어텐션 헤드 수, num_steps 또는 쿼리 수, num_steps 또는 키-값 쌍 수)입니다.
위 코드는 모델의 self-attention 및 encoder-decoder attention 가중치를 확인하고 검사하는 과정을 나타냅니다.
_, dec_attention_weights = model.predict_step(...): 주어진 영어 문장을 프랑스어로 번역하면서 두 가지의 attention 가중치를 반환합니다. data.build 함수로 입력 데이터를 생성하고, d2l.try_gpu()를 통해 GPU를 사용하도록 설정합니다. data.num_steps는 문장의 최대 길이입니다. True 파라미터는 attention 가중치를 반환하도록 지시합니다.
enc_attention_weights = torch.cat(model.encoder.attention_weights, 0): 인코더의 self-attention 가중치를 모두 하나의 텐서로 결합합니다.
shape = (num_blks, num_heads, -1, data.num_steps): 가중치의 모양을 지정합니다. num_blks는 블록의 수, num_heads는 head의 수, data.num_steps는 문장 길이입니다. -1은 다른 차원을 맞추고 남는 차원을 지정합니다.
enc_attention_weights = enc_attention_weights.reshape(shape): 가중치 텐서의 모양을 지정한 shape로 재구성합니다.
d2l.check_shape(enc_attention_weights, ...: 재구성된 가중치 텐서의 모양을 확인합니다. 정확한 모양은 num_blks, num_heads, 문장 길이, 문장 길이입니다. 이는 인코더 블록에서 self-attention 가중치의 모양을 검사하는 것입니다.
In the encoder self-attention, both queries and keys come from the same input sequence. Since padding tokens do not carry meaning, with specified valid length of the input sequence, no query attends to positions of padding tokens. In the following, two layers of multi-head attention weights are presented row by row. Each head independently attends based on a separate representation subspaces of queries, keys, and values.
인코더 self-attention에서 쿼리와 키는 모두 동일한 입력 시퀀스에서 나옵니다. 패딩 토큰은 의미를 전달하지 않으므로 입력 시퀀스의 지정된 유효 길이를 사용하면 패딩 토큰의 위치에 대한 query attends는 없습니다. 다음에서는 multi-head attention weights의 두 레이어가 행별로 표시됩니다. 각 헤드는 쿼리, 키 및 값의 별도 representation 하위 공간을 기반으로 독립적으로 attends합니다.
d2l.show_heatmaps(
enc_attention_weights.cpu(), xlabel='Key positions',
ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],
figsize=(7, 3.5))
위 코드는 인코더의 self-attention 가중치를 시각화하는 과정을 나타냅니다.
d2l.show_heatmaps(: d2l.show_heatmaps 함수를 호출하여 열쇠(Key) 위치와 질문(Query) 위치에 대한 인코더의 self-attention 가중치를 히트맵으로 표시합니다.
enc_attention_weights.cpu(): 가중치 텐서를 CPU로 이동시킵니다. 이는 히트맵을 생성할 때 GPU와 호환되도록 하는 과정입니다.
xlabel='Key positions', ylabel='Query positions': 히트맵의 x축과 y축에 레이블을 붙입니다. 여기서 x축은 Key 위치, y축은 Query 위치를 나타냅니다.
titles=['Head %d' % i for i in range(1, 5)]: 각 히트맵의 제목을 지정합니다. 인코더 내의 각 head에 대한 히트맵을 생성할 것이며, 제목에는 head의 번호가 포함됩니다.
figsize=(7, 3.5)): 생성되는 히트맵의 크기를 지정합니다. (7, 3.5)는 가로 7, 세로 3.5의 크기를 가진 히트맵을 생성하라는 의미입니다.
이렇게 하면 인코더 내의 self-attention 가중치가 여러 head 및 위치에 대해 시각화된 히트맵이 생성됩니다.
To visualize both the decoder self-attention weights and the encoder-decoder attention weights, we need more data manipulations. For example, we fill the masked attention weights with zero. Note that the decoder self-attention weights and the encoder-decoder attention weights both have the same queries: the beginning-of-sequence token followed by the output tokens and possibly end-of-sequence tokens.
decoder self-attention weights와 encoder-decoder attention weights를 모두 시각화하려면 더 많은 데이터 조작이 필요합니다. 예를 들어 masked attention weights를 0으로 채웁니다. decoder self-attention weights와 encoder-decoder attention weights는 모두 동일한 쿼리를 가집니다. 즉, beginning-of-sequence token 다음에 output tokens 및 end-of-sequence tokens이 올 수 있습니다.
dec_attention_weights_2d = [head[0].tolist()
for step in dec_attention_weights
for attn in step for blk in attn for head in blk]
dec_attention_weights_filled = torch.tensor(
pd.DataFrame(dec_attention_weights_2d).fillna(0.0).values)
shape = (-1, 2, num_blks, num_heads, data.num_steps)
dec_attention_weights = dec_attention_weights_filled.reshape(shape)
dec_self_attention_weights, dec_inter_attention_weights = \
dec_attention_weights.permute(1, 2, 3, 0, 4)
d2l.check_shape(dec_self_attention_weights,
(num_blks, num_heads, data.num_steps, data.num_steps))
d2l.check_shape(dec_inter_attention_weights,
(num_blks, num_heads, data.num_steps, data.num_steps))
위 코드는 디코더의 self-attention 가중치와 인코더-디코더 attention 가중치를 시각화하기 위한 과정을 나타냅니다.
dec_attention_weights_2d: 디코더의 self-attention 가중치를 2차원 리스트 형태로 변환합니다. 이는 향후 데이터 분석을 위한 과정입니다. 여기서 dec_attention_weights는 디코더의 attention 가중치입니다.
dec_attention_weights_filled: 2차원 리스트를 이용해 누락된 값을 0.0으로 채운 텐서를 생성합니다. 이를 통해 향후 시각화를 진행할 때 빈 값을 처리할 수 있습니다.
shape: 텐서의 형태를 재구성하기 위한 shape를 정의합니다. 5차원의 텐서 구조로 만들 것이며, 이는 디코더의 self-attention 및 인코더-디코더 attention 가중치에 대한 구조를 나타냅니다.
dec_attention_weights: 위에서 만든 dec_attention_weights_filled 텐서를 shape에 맞게 재구성합니다. 이렇게 하면 디코더의 self-attention 및 인코더-디코더 attention 가중치가 적절한 구조로 저장됩니다.
dec_self_attention_weights와 dec_inter_attention_weights: dec_attention_weights를 통해 생성된 텐서를 디코더의 self-attention 가중치와 인코더-디코더 attention 가중치로 분리합니다. 이를 위해 텐서의 차원을 조정하고 순서를 변경합니다.
d2l.check_shape: 텐서의 형태를 확인하는 함수를 사용하여 디코더의 self-attention 가중치와 인코더-디코더 attention 가중치의 형태를 검증합니다. 각각의 형태는 (num_blks, num_heads, data.num_steps, data.num_steps)와 같아야 합니다.
이러한 과정을 통해 디코더의 self-attention 가중치와 인코더-디코더 attention 가중치가 적절한 형태로 처리되고 시각화될 준비가 완료됩니다.
Due to the auto-regressive property of the decoder self-attention, no query attends to key-value pairs after the query position.
디코더 self-attention의 auto-regressive 속성으로 인해 query position 이후의 ey-value pairs에 query attends는 없습니다.
d2l.show_heatmaps(
dec_self_attention_weights[:, :, :, :],
xlabel='Key positions', ylabel='Query positions',
titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5))
위 코드는 디코더의 self-attention 가중치를 열쇠 (Key) 위치와 질의 (Query) 위치에 대한 열과 행으로 시각화합니다.
dec_self_attention_weights[:, :, :, :]: 디코더의 self-attention 가중치를 해당하는 범위 내에서 선택합니다. 이렇게 함으로써 시각화할 때 필요한 구간을 선택하게 됩니다.
xlabel과 ylabel: 시각화 결과의 x축과 y축에 표시될 레이블을 설정합니다. 이 경우 "Key positions"와 "Query positions"로 설정되어 key 위치와 query 위치를 의미합니다.
titles: 시각화된 각 히트맵의 제목을 설정합니다. 여기서는 "Head 1", "Head 2", "Head 3", "Head 4"와 같이 각 헤드에 대한 정보를 표시합니다.
figsize: 시각화된 히트맵의 크기를 설정합니다. (7, 3.5)로 설정되어 있으며 가로 7, 세로 3.5의 크기로 히트맵이 표시됩니다.
이를 통해 디코더의 self-attention 가중치가 열쇠 위치와 질의 위치에 따라 시각화되며, 각각의 헤드에 대한 정보도 함께 나타납니다.
Similar to the case in the encoder self-attention, via the specified valid length of the input sequence, no query from the output sequence attends to those padding tokens from the input sequence.
인코더 self-attention의 경우와 유사하게 입력 시퀀스의 지정된 유효 길이를 통해 output sequence에서 input sequence에서 온 padding tokens로의 query는 없습니다.
d2l.show_heatmaps(
dec_inter_attention_weights, xlabel='Key positions',
ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],
figsize=(7, 3.5))
이 코드는 디코더의 self-attention 가중치를 시각화하는 과정을 보여줍니다. 이 코드를 하나씩 설명해보겠습니다.
dec_self_attention_weights[:, :, :, :]: 디코더의 self-attention 가중치를 선택합니다. 이것은 시각화를 위해 해당 가중치의 특정 부분을 선택하는 것입니다.
xlabel 및 ylabel: 시각화된 히트맵의 x축 및 y축에 나타날 레이블을 설정합니다. 이 경우 "Key positions"와 "Query positions"로 설정되어 열쇠 (Key) 위치 및 질의 (Query) 위치를 나타냅니다.
titles: 시각화된 히트맵 각각의 제목을 설정합니다. 여기에서는 "Head 1", "Head 2", "Head 3", "Head 4"와 같이 각 헤드에 대한 정보를 보여줍니다.
figsize: 시각화된 히트맵의 크기를 설정합니다. (7, 3.5)로 설정되어 있으며 가로 7, 세로 3.5의 크기로 히트맵이 표시됩니다.
이 코드의 목적은 디코더의 self-attention 가중치를 시각화하여 열쇠 위치와 질의 위치 간의 관계를 파악하고, 각 헤드에 대한 정보를 시각적으로 확인하는 것입니다.
Although the Transformer architecture was originally proposed for sequence-to-sequence learning, as we will discover later in the book, either the Transformer encoder or the Transformer decoder is often individually used for different deep learning tasks.
Transformer 아키텍처는 원래 sequence-to-sequence 학습을 위해 제안되었지만 이 책의 뒷부분에서 알게 되겠지만 Transformer 인코더 또는 Transformer 디코더는 서로 다른 딥 러닝 작업에 개별적으로 사용되는 경우가 많습니다.
11.7.7.Summary
The Transformer is an instance of the encoder-decoder architecture, though either the encoder or the decoder can be used individually in practice. In the Transformer architecture, multi-head self-attention is used for representing the input sequence and the output sequence, though the decoder has to preserve the auto-regressive property via a masked version. Both the residual connections and the layer normalization in the Transformer are important for training a very deep model. The positionwise feed-forward network in the Transformer model transforms the representation at all the sequence positions using the same MLP.
Transformer는 인코더-디코더 아키텍처의 인스턴스이지만 실제로는 인코더 또는 디코더를 개별적으로 사용할 수 있습니다. 트랜스포머 아키텍처에서 multi-head self-attention은 입력 시퀀스와 출력 시퀀스를 나타내는 데 사용되지만 디코더는 masked version을 통해 자동 회귀 속성을 보존해야 합니다. Transformer의 residual connections과 layer normalization는 모두 아주 deep 한 model을 교육하는 데 중요합니다. Transformer 모델의 positionwise feed-forward network는 동일한 MLP를 사용하여 모든 시퀀스 위치에서 representation을 변환합니다.
11.7.8.Exercises
Train a deeper Transformer in the experiments. How does it affect the training speed and the translation performance?
Is it a good idea to replace scaled dot-product attention with additive attention in the Transformer? Why?
For language modeling, should we use the Transformer encoder, decoder, or both? How to design this method?
What can be challenges to Transformers if input sequences are very long? Why?
How to improve computational and memory efficiency of Transformers? Hint: you may refer to the survey paper byTayet al.(2020).
In deep learning, we often use CNNs or RNNs to encode sequences. Now with attention mechanisms in mind, imagine feeding a sequence of tokens into an attention mechanism such that at each step, each token has its own query, keys, and values. Here, when computing the value of a token’s representation at the next layer, the token can attend (via its query vector) to each other token (matching based on their key vectors). Using the full set of query-key compatibility scores, we can compute, for each token, a representation by building the appropriate weighted sum over the other tokens. Because each token is attending to each other token (unlike the case where decoder steps attend to encoder steps), such architectures are typically described asself-attentionmodels(Linet al., 2017,Vaswaniet al., 2017), and elsewhere described asintra-attentionmodel(Chenget al., 2016,Parikhet al., 2016,Pauluset al., 2017). In this section, we will discuss sequence encoding using self-attention, including using additional information for the sequence order.
딥 러닝에서 우리는 종종 CNN 또는 RNN을 사용하여 시퀀스를 인코딩합니다. 이제 어텐션 메커니즘을 염두에 두고 일련의 토큰을 어텐션 메커니즘에 공급하여 각 단계에서 각 토큰이 고유한 쿼리, 키 및 값을 갖도록 한다고 상상해 보십시오. 여기에서 다음 계층에서 토큰의 representation 값을 계산할 때 토큰은 쿼리 벡터를 통해 서로 토큰에 attend할 수 있습니다(matching based on their key vectors). 쿼리 키 호환성 점수(compatibility scores)의 전체 집합을 사용하여 다른 토큰에 대해 적절한 weighted sum (가중 합계)를 구축하여 각 토큰에 대한 representation을 계산할 수 있습니다. 각 토큰이 서로 토큰에 attending하기 때문에(디코더 단계가 인코더 단계에 attend하는 경우와 달리) 이러한 아키텍처는 일반적으로 self-attention 모델(Lin et al., 2017, Vaswani et al., 2017)로 설명됩니다. 인트라 어텐션 모델로 설명됩니다(Cheng et al., 2016, Parikh et al., 2016, Paulus et al., 2017). 이 섹션에서는 시퀀스 순서에 대한 추가 정보 사용을 포함하여 self-attention을 사용한 시퀀스 인코딩에 대해 설명합니다.
import math
import torch
from torch import nn
from d2l import torch as d2l
11.6.1.Self-Attention
Given a sequence of input tokensx1,…,xnwhere anyxi∈ℝd(1≤i≤n), its self-attention outputs a sequence of the same lengthy1,…,yn, where like this according to the definition of attention pooling in(11.1.1).
임의의 xi∈ℝd(1≤i≤n)인 경우 입력 토큰 x1,...,xn의 시퀀스가 주어지면 self-attention은 동일한 길이 y1...,,yn의 시퀀스를 출력합니다. (11.1.1).
Using multi-head attention, the following code snippet computes the self-attention of a tensor with shape (batch size, number of time steps or sequence length in tokens, d). The output tensor has the same shape.
multi-head attention을 사용하여 다음 코드 스니펫은 shape(배치 크기, 시간 단계 수 또는 토큰의 시퀀스 길이, d)과 함께 텐서의 self-attention을 계산합니다. 출력 텐서는 동일한 모양을 갖습니다.
위 코드는 멀티헤드 어텐션을 생성하고, 입력 데이터를 통해 멀티헤드 어텐션을 실행하며 출력의 형태를 확인하는 과정을 보여줍니다.
num_hiddens, num_heads 변수를 설정하여 어텐션의 히든 크기와 헤드 개수를 정의합니다.
d2l.MultiHeadAttention(num_hiddens, num_heads, 0.5) 코드를 통해 멀티헤드 어텐션 객체를 생성합니다. num_hiddens와 num_heads는 앞서 정의한 값이며, 0.5는 드롭아웃 비율을 나타냅니다.
batch_size, num_queries, valid_lens 변수를 설정하여 미니배치 크기, 쿼리 개수, 그리고 유효한 쿼리 길이를 정의합니다.
X = torch.ones((batch_size, num_queries, num_hiddens)) 코드를 통해 미니배치 크기와 쿼리 개수에 해당하는 크기의 3D 텐서 X를 생성합니다. 이 텐서는 쿼리 데이터를 나타냅니다.
attention(X, X, X, valid_lens)를 호출하여 멀티헤드 어텐션을 실행합니다. 여기서 X를 쿼리, 키, 값으로 사용하며, valid_lens는 유효한 쿼리 길이를 나타냅니다.
d2l.check_shape()를 사용하여 어텐션의 출력 형태를 확인합니다. 출력은 (batch_size, num_queries, num_hiddens)의 형태가 되어야 합니다. 이를 통해 코드의 정확성을 검증합니다.
이 코드는 멀티헤드 어텐션을 생성하고 실행하여 출력의 형태가 기대한 형태와 일치하는지 확인하는 예시입니다.
11.6.2.Comparing CNNs, RNNs, and Self-Attention
Let’s compare architectures for mapping a sequence ofntokens to another sequence of equal length, where each input or output token is represented by ad-dimensional vector. Specifically, we will consider CNNs, RNNs, and self-attention. We will compare their computational complexity, sequential operations, and maximum path lengths. Note that sequential operations prevent parallel computation, while a shorter path between any combination of sequence positions makes it easier to learn long-range dependencies within the sequence(Hochreiteret al., 2001).
n개 토큰의 시퀀스를 동일한 길이의 다른 시퀀스로 매핑하기 위한 아키텍처를 비교해 봅시다. 각 입력 또는 출력 토큰은 d차원 벡터로 표현됩니다. 구체적으로 CNN, RNN, self-attention을 고려할 것입니다. 계산 복잡성, 순차 작업 및 최대 경로 길이를 비교할 것입니다. 순차 작업(sequential operations)은 병렬 계산을 방지하는 반면 시퀀스 positions 조합 사이의 경로가 짧으면 시퀀스 내에서 장거리 종속성을 쉽게 학습할 수 있습니다(Hochreiter et al., 2001).
Fig. 11.6.1 Comparing CNN (padding tokens are omitted), RNN, and self-attention architectures.
Consider a convolutional layer whose kernel size is k. We will provide more details about sequence processing using CNNs in later chapters. For now, we only need to know that since the sequence length isn, the numbers of input and output channels are bothd, the computational complexity of the convolutional layer is𝒪(knd2). AsFig. 11.6.1shows, CNNs are hierarchical, so there are𝒪(1)sequential operations and the maximum path length is𝒪(n/k). For example,x1andx5are within the receptive field of a two-layer CNN with kernel size 3 inFig. 11.6.1.
커널 크기가 k인 컨볼루션 계층을 고려하십시오. 이후 장에서 CNN을 사용한 시퀀스 처리에 대한 자세한 내용을 제공할 것입니다. 지금은 시퀀스 길이가 n이고 입력 및 출력 채널의 수가 모두 d이므로 컨볼루션 계층의 계산 복잡도는 𝒪(knd2)라는 것만 알면 됩니다. 그림 11.6.1에서 볼 수 있듯이 CNN은 계층적이므로 𝒪(1)개의 순차적 작업이 있고 최대 경로 길이는 𝒪(n/k)입니다. 예를 들어 x1과 x5는 그림 11.6.1에서 커널 크기가 3인 two-layer CNN의 receptive field 내에 있습니다.
When updating the hidden state of RNNs, multiplication of thed×dweight matrix and thed-dimensional hidden state has a computational complexity of𝒪(d^2). Since the sequence length isn, the computational complexity of the recurrent layer is𝒪(nd^2). According toFig. 11.6.1, there are𝒪(n)sequential operations that cannot be parallelized and the maximum path length is also𝒪(n).
RNN의 hidden state를 업데이트할 때 d×d 가중치 행렬과 d차원 hidden state의 곱셈은 𝒪(d^2)의 계산 복잡도를 갖습니다. 시퀀스 길이가 n이므로 recurrent layer의 계산 복잡도는 𝒪(nd^2)입니다. 그림 11.6.1에 따르면 병렬화할 수 없는 순차 연산이 𝒪(n)개 있고 최대 경로 길이도 𝒪(n)입니다.
In self-attention, the queries, keys, and values are alln×dmatrices. Consider the scaled dot-product attention in(11.3.6), where a n×dmatrix is multiplied by ad×nmatrix, then the outputn×nmatrix is multiplied by an×dmatrix. As a result, the self-attention has a𝒪(n^2d)computational complexity. As we can see inFig. 11.6.1, each token is directly connected to any other token via self-attention. Therefore, computation can be parallel with 𝒪(1)sequential operations and the maximum path length is also 𝒪(1).
self-attention에서 쿼리, 키, 값은 모두 n×d 행렬입니다. n×d 행렬에 d×n 행렬을 곱한 다음 출력 n×n 행렬에 n×d 행렬을 곱하는 (11.3.6)의 scaled dot-product attention를 고려하십시오. 결과적으로 self-attention은 𝒪(n^2d) 계산 복잡도를 가집니다. 그림 11.6.1에서 볼 수 있듯이 각 토큰은 self-attention을 통해 다른 토큰에 직접 연결됩니다. 따라서 연산은 𝒪(1) 순차 연산과 병행할 수 있으며 최대 경로 길이도 𝒪(1)입니다.
All in all, both CNNs and self-attention enjoy parallel computation and self-attention has the shortest maximum path length. However, the quadratic computational complexity with respect to the sequence length makes self-attention prohibitively slow for very long sequences.
대체로 CNN과 self-attention은 병렬 계산을 즐기고 self-attention은 최대 경로 길이(maximum path length)가 가장 짧습니다. 그러나 시퀀스 길이에 대한 2차 계산 복잡성(quadratic computational complexity)으로 인해 매우 긴 시퀀스의 경우 self-attention이 엄청나게 느려집니다.
quadratic computational complexity란?
'Quadratic computational complexity' refers to the growth rate of computational resources (such as time or memory) required by an algorithm as the input size increases. Specifically, it describes a scenario where the computational cost of an algorithm increases quadratically with the size of the input.
이차 계산 복잡도'는 알고리즘이 입력 크기가 증가함에 따라 필요한 계산 리소스(시간 또는 메모리와 같은)의 증가 속도를 나타냅니다. 구체적으로 말하면, 이는 알고리즘의 계산 비용이 입력 크기의 제곱에 비례하여 증가하는 상황을 의미합니다.
In mathematical terms, an algorithm is said to have quadratic complexity if the time or space it requires is proportional to the square of the input size. This is often denoted as O(n^2), where "n" represents the size of the input.
수학적으로, 알고리즘의 시간 또는 공간 요구 사항이 입력 크기의 제곱에 비례한다면 알고리즘은 이차 복잡도를 가진다고 말합니다. 이는 종종 O(n^2)로 표기되며, 여기서 "n"은 입력 크기를 나타냅니다.
Quadratic complexity is commonly associated with algorithms that involve nested loops, where each iteration of an outer loop contains one or more iterations of an inner loop. As the input size grows, the total number of iterations increases quadratically, leading to a significant increase in computational requirements.
이차 복잡도는 외부 루프의 각 반복이 내부 루프의 하나 이상의 반복을 포함하는 중첩 루프와 관련이 있습니다. 입력 크기가 증가함에 따라 전체 반복 횟수가 이차적으로 증가하므로 계산 요구 사항이 크게 증가합니다.
Algorithms with quadratic complexity are less efficient than those with linear (O(n)), logarithmic (O(log n)), or constant (O(1)) complexity. Therefore, in designing algorithms, it's generally preferable to minimize or avoid quadratic complexity whenever possible to ensure optimal performance as the input size grows.
이차 복잡도를 가진 알고리즘은 선형(O(n)), 로그(O(log n)), 또는 상수(O(1)) 복잡도를 가진 알고리즘보다 효율성이 낮습니다. 따라서 알고리즘을 설계할 때 입력 크기가 증가함에 따라 최적의 성능을 보장하기 위해 이차 복잡도를 최소화하거나 피하는 것이 일반적으로 바람직합니다.
11.6.3.Positional Encoding
Unlike RNNs, which recurrently process tokens of a sequence one by one, self-attention ditches sequential operations in favor of parallel computation. Note, however, that self-attention by itself does not preserve the order of the sequence. What do we do if it really matters that the model knows in which order the input sequence arrived?
시퀀스의 토큰을 하나씩 반복적으로 처리하는 RNN과 달리 self-attention은 병렬 계산을 위해 sequential operations을 버립니다. self-attention 자체는 시퀀스의 순서를 유지하지 않는 다는 것을 주목 하세요. 모델이 입력 시퀀스가 도착한 순서를 아는 것이 정말 중요하다면 어떻게 해야 할까요?
The dominant approach for preserving information about the order of tokens is to represent this to the model as an additional input associated with each token. These inputs are calledpositional encodings. and they can either be learned or fixed a priori. We now describe a simple scheme for fixed positional encodings based on sine and cosine functions(Vaswaniet al., 2017).
토큰 순서에 대한 정보를 보존하기 위한 지배적인 접근 방식은 이를 각 토큰과 관련된 추가 입력으로 모델에 나타내는 것입니다. 이러한 입력을 positional encodings이라고 합니다. 그것들은 선험적으로 학습되거나 고정될 수 있습니다. 이제 사인 및 코사인 함수를 기반으로 fixed positional encodings을 위한 간단한 체계를 설명합니다(Vaswani et al., 2017).
Positional Encodings란?
'Positional Encodings'은 트랜스포머 모델과 같은 시퀀스-투-시퀀스 모델에서 단어의 상대적인 위치 정보를 모델에 전달하는 메커니즘입니다. 트랜스포머 모델은 셀프 어텐션을 통해 시퀀스 내의 단어들 간의 관계를 학습하지만, 이 모델은 단어의 위치 정보를 고려하지 않습니다. 따라서 같은 단어라고 하더라도 문장 내에서의 위치에 따라 의미가 달라질 수 있습니다.
이런 문제를 해결하기 위해 트랜스포머 모델은 'Positional Encodings'을 도입합니다. 이는 각 단어의 임베딩에 위치 정보를 더하는 방식으로 동작합니다. 이러한 위치 정보는 사인과 코사인 함수를 사용하여 계산되며, 이러한 함수의 주기와 진폭이 단어의 위치를 나타냅니다. 이렇게 함으로써 모델은 단어의 상대적인 위치 정보를 학습할 수 있게 됩니다.
예를 들어, "I love coding"이라는 문장에서 "love"라는 단어는 문장 맨 처음과는 다른 위치에 있을 때 다른 의미를 가지게 될 수 있습니다. 'Positional Encodings'을 사용하면 모델은 이러한 상대적인 위치 정보를 학습하여 단어의 의미를 더 정확하게 파악할 수 있습니다.
Suppose that the input representation X∈ℝn×dcontains thed-dimensional embeddings forntokens of a sequence. The positional encoding outputsX+Pusing a positional embedding matrixP∈ℝn×dof the same shape, whose element on thei throw and the(2j)thor the(2j+1)thcolumn is
입력 representation X∈ℝn×d가 시퀀스의 n 토큰에 대한 d차원 임베딩을 포함한다고 가정합니다. positional encoding는 동일한 모양의 positional embedding matrix P∈ℝn×d를 사용하여 X+P를 출력하며, i번째 행과 (2j)번째 또는 (2j+1)번째 열의 요소는 다음과 같습니다.
At first glance, this trigonometric-function design looks weird. Before explanations of this design, let’s first implement it in the followingPositionalEncodingclass.
언뜻 보면 이 삼각함수(trigonometric-function) 디자인이 이상해 보입니다. 이 디자인을 설명하기 전에 먼저 다음 PositionalEncoding 클래스에서 구현해 보겠습니다.
class PositionalEncoding(nn.Module): #@save
"""Positional encoding."""
def __init__(self, num_hiddens, dropout, max_len=1000):
super().__init__()
self.dropout = nn.Dropout(dropout)
# Create a long enough P
self.P = torch.zeros((1, max_len, num_hiddens))
X = torch.arange(max_len, dtype=torch.float32).reshape(
-1, 1) / torch.pow(10000, torch.arange(
0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)
self.P[:, :, 0::2] = torch.sin(X)
self.P[:, :, 1::2] = torch.cos(X)
def forward(self, X):
X = X + self.P[:, :X.shape[1], :].to(X.device)
return self.dropout(X)
위 코드는 트랜스포머 모델에서 사용되는 'Positional Encoding'을 구현한 클래스입니다. 트랜스포머 모델은 단어의 순서 정보를 어텐션 메커니즘을 사용하여 처리하므로, 단어의 상대적인 위치 정보를 인코딩해야 합니다. 이를 위해 'Positional Encoding'이 사용됩니다.
self.P: 시퀀스의 각 위치에 대한 positional encoding을 저장하는 텐서입니다.
X는 트랜스포머에서 사용되는 각 위치의 positional encoding을 생성하는 역할을 합니다. 이때 max_len만큼의 숫자 시퀀스를 생성하고, 이를 이용하여 각 위치의 positional encoding 값을 계산합니다.
torch.pow(10000, ...)를 통해 positional encoding 값의 변화율을 결정합니다.
self.P의 홀수 인덱스 위치에는 사인 값을, 짝수 인덱스 위치에는 코사인 값을 저장하여 positional encoding 값을 구성합니다.
forward(self, X):
X: 임베딩된 입력 토큰 텐서입니다.
forward 메서드는 입력으로 받은 임베딩된 토큰 X에 positional encoding을 더하는 과정을 수행합니다.
X에 self.P를 더하여 positional encoding을 적용합니다. 이 때 입력의 길이에 맞추어 self.P의 길이를 잘라내어 적용합니다. (self.P는 토큰의 개수에 맞게 잘라서 가져온 후, X와 더하여 위치 정보를 추가합니다.)
이후 self.dropout을 적용하여 드롭아웃을 적용한 결과를 반환합니다.
위 클래스는 트랜스포머 모델에서 입력 임베딩에 positional encoding을 추가하는 역할을 수행합니다. 이를 통해 모델은 단어의 상대적인 위치 정보를 반영하여 문장 내 단어의 순서를 고려할 수 있게 됩니다.
In the positional embedding matrixP, rows correspond to positions within a sequence and columns represent different positional encoding dimensions. In the example below, we can see that the6thand the7thcolumns of the positional embedding matrix have a higher frequency than the8thand the9thcolumns. The offset between the6thand the7th(same for the8thand the9th) columns is due to the alternation of sine and cosine functions.
positional embedding matrix P에서 행rows은 시퀀스 내의 위치positions에 해당하고 열columns은 서로 다른 positional encoding dimensions을 나타냅니다. 아래 예에서 positional embedding matrix의 6번째 및 7번째 열이 8번째 및 9번째 열보다 높은 빈도를 갖는 것을 볼 수 있습니다. 6번째 열과 7번째 열(8번째 및 9번째 열과 동일) 사이의 오프셋은 사인 및 코사인 함수의 교체 alternation로 인한 것입니다.
encoding_dim, num_steps = 32, 60
pos_encoding = PositionalEncoding(encoding_dim, 0)
X = pos_encoding(torch.zeros((1, num_steps, encoding_dim)))
P = pos_encoding.P[:, :X.shape[1], :]
d2l.plot(torch.arange(num_steps), P[0, :, 6:10].T, xlabel='Row (position)',
figsize=(6, 2.5), legend=["Col %d" % d for d in torch.arange(6, 10)])
encoding_dim은 positional encoding 차원의 크기를, num_steps는 시퀀스의 길이를 나타냅니다.
PositionalEncoding 클래스를 이용해 pos_encoding 객체를 생성합니다. 이 객체는 위치 정보를 포함한 positional encoding을 생성하는 역할을 합니다.
torch.zeros((1, num_steps, encoding_dim))를 통해 임의의 입력 데이터를 생성하고, 이를 pos_encoding에 적용하여 positional encoding을 얻습니다.
pos_encoding.P[:, :X.shape[1], :]를 통해 얻은 positional encoding 텐서를 P에 저장합니다. 이때 텐서의 형태는 (1, num_steps, encoding_dim)입니다.
d2l.plot 함수를 이용해 특정 인덱스 범위의 positional encoding을 시각화합니다. torch.arange(6, 10)은 6부터 9까지의 열을 선택하여 시각화하겠다는 의미입니다.
xlabel='Row (position)'를 통해 x 축의 레이블을 설정하고, figsize=(6, 2.5)로 그림의 크기를 지정합니다.
legend=["Col %d" % d for d in torch.arange(6, 10)]를 통해 범례에 각 열의 레이블을 추가합니다.
이 코드는 PositionalEncoding을 통해 생성한 positional encoding을 시각화하여, 각 위치와 각 차원의 변화를 확인하는 역할을 합니다.
11.6.3.1.Absolute Positional Information
To see how the monotonically decreased frequency along the encoding dimension relates to absolute positional information, let’s print out the binary representations of0,1,…,7. As we can see, the lowest bit, the second-lowest bit, and the third-lowest bit alternate on every number, every two numbers, and every four numbers, respectively.
인코딩 차원을 따라 단조롭게 감소된 frequency가 절대 위치 정보와 어떻게 관련되는지 확인하기 위해 0,1,…,7의 이진 표현을 출력해 보겠습니다. 보시다시피 가장 낮은 비트, 두 번째로 낮은 비트 및 세 번째로 낮은 비트는 각각 모든 숫자, 두 개의 숫자 및 네 개의 숫자마다 번갈아 나타납니다.
for i in range(8):
print(f'{i} in binary is {i:>03b}')
이 코드는 0부터 7까지의 정수를 이진수로 나타내는 예시를 보여주는 반복문입니다.
for i in range(8):는 0부터 7까지의 정수를 반복하는 루프입니다.
f'{i} in binary is {i:>03b}'은 문자열 포맷팅을 사용하여 출력될 문자열을 생성합니다. 여기서 i는 현재 정수 값이며, i:>03b는 해당 값을 이진수로 나타내는 형식입니다. >03은 문자열을 오른쪽 정렬하고, 최소 3자리로 표현하도록 지시하는 것을 의미합니다.
결과적으로 이 코드는 0부터 7까지의 정수를 이진수로 변환하여 출력합니다. 출력 형태는 각 정수와 해당 이진수 표현을 보여주며, 이때 이진수는 최소 3자리로 오른쪽 정렬된 형태로 출력됩니다.
0 in binary is 000
1 in binary is 001
2 in binary is 010
3 in binary is 011
4 in binary is 100
5 in binary is 101
6 in binary is 110
7 in binary is 111
In binary representations, a higher bit has a lower frequency than a lower bit. Similarly, as demonstrated in the heat map below, the positional encoding decreases frequencies along the encoding dimension by using trigonometric functions. Since the outputs are float numbers, such continuous representations are more space-efficient than binary representations.
binary representations에서 높은 비트는 낮은 비트보다 주파수가 낮습니다. 유사하게, 아래의 열지도heat map에서 볼 수 있듯이 positional encoding은 삼각 함수를 사용하여 encoding dimension을 따라 frequencies를 줄입니다. 출력은 부동 소수점 숫자이므로 이러한 연속 representations은 이진 표현보다 공간 효율적입니다.
이 코드는 위치 인코딩 행렬 P를 시각화하여 행과 열에 대한 히트맵을 표시하는 부분입니다.
P = P[0, :, :].unsqueeze(0).unsqueeze(0)는 P 행렬을 시각화할 수 있도록 데이터 형태를 조정합니다. P는 (1, max_len, num_hiddens)의 형태를 가지는데, 이를 (1, num_steps, encoding_dim)의 형태로 변환합니다. 이는 히트맵을 표시하기 위해 데이터 형태를 변경하는 단계입니다.
d2l.show_heatmaps(P, xlabel='Column (encoding dimension)', ylabel='Row (position)', figsize=(3.5, 4), cmap='Blues')는 d2l 라이브러리의 show_heatmaps 함수를 사용하여 히트맵을 시각화합니다. 여기서 P를 시각화하며, x축은 인코딩 차원(column)을 나타내고, y축은 위치(row)를 나타냅니다. figsize는 그림 크기를 지정하고, cmap은 색상 맵을 지정합니다.
이 코드는 위치 인코딩 행렬을 히트맵으로 시각화하여, 행과 열에 따른 패턴을 확인할 수 있도록 합니다.
11.6.3.2.Relative Positional Information
Besides capturing absolute positional information, the above positional encoding also allows a model to easily learn to attend by relative positions. This is because for any fixed position offset δ (delta), the positional encoding at positioni+δcan be represented by a linear projection of that at positioni.
absolute positional information를 캡처하는 것 외에도 위의 positional encoding을 사용하면 모델이 relative positions에 attend하는 방법을 쉽게 배울 수 있습니다. 이는 임의의 고정된 위치 오프셋 δ(델타)에 대해 위치 i+δ에서의 위치 인코딩이 위치 i에서의 선형 프로젝션으로 표현될 수 있기 때문입니다.
이 projection은 수학적으로 설명 될 수 있습니다.
where the2×2projection matrix does not depend on any position index i.
여기서 2×2 프로젝션 매트릭스는 위치 인덱스 i에 의존하지 않습니다.
11.6.4.Summary
In self-attention, the queries, keys, and values all come from the same place. Both CNNs and self-attention enjoy parallel computation and self-attention has the shortest maximum path length. However, the quadratic computational complexity with respect to the sequence length makes self-attention prohibitively slow for very long sequences. To use the sequence order information, we can inject absolute or relative positional information by adding positional encoding to the input representations.
self-attention에서 쿼리, 키 및 값은 모두 같은 위치에서 옵니다. CNN과 self-attention 모두 병렬 계산을 즐기고 self-attention은 최대 경로 길이가 가장 짧습니다. 그러나 시퀀스 길이에 대한 2차(quadratic) 계산 복잡성으로 인해 매우 긴 시퀀스의 경우 self-attention이 엄청나게 느려집니다. 시퀀스 순서 정보를 사용하기 위해 입력 표현에 위치 인코딩을 추가하여 절대 또는 상대 위치 정보를 주입할 수 있습니다.
11.6.5.Exercises
Suppose that we design a deep architecture to represent a sequence by stacking self-attention layers with positional encoding. What could be issues?
Can you design a learnable positional encoding method?
Can we assign different learned embeddings according to different offsets between queries and keys that are compared in self-attention? Hint: you may refer to relative position embeddings(Huanget al., 2018,Shawet al., 2018).
Self-Attention이란?
'Self-attention'은 주어진 입력 시퀀스 내의 요소들 간의 상관 관계를 계산하기 위해 사용되는 메커니즘입니다. 주로 자연어 처리와 기계 번역과 같은 sequence-to-sequence 모델에서 사용되며, 특히 트랜스포머 (Transformer)와 같은 모델에서 널리 사용됩니다.
Self-attention은 입력 시퀀스의 각 요소가 다른 모든 요소와 얼마나 관련 있는지를 계산하며, 이를 통해 문장 내에서 단어들 간의 의미적 연관성을 포착할 수 있습니다. 이는 문맥을 파악하거나 문장 내에서 중요한 단어를 감지하는 데 유용합니다.
Self-attention 메커니즘은 다양한 방식으로 구현될 수 있지만, 대표적으로 'Scaled Dot-Product Attention', 'Additive Attention', 'Multi-Head Attention' 등이 있습니다. 이러한 메커니즘을 통해 모델은 입력 시퀀스의 각 요소에 대해 가중치를 할당하여 문맥을 이해하고, 이를 기반으로 다음 출력을 생성하거나 문장을 번역하는 작업을 수행할 수 있습니다.
In practice, given the same set of queries, keys, and values we may want our model to combine knowledge from different behaviors of the same attention mechanism, such as capturing dependencies of various ranges (e.g., shorter-range vs. longer-range) within a sequence. Thus, it may be beneficial to allow our attention mechanism to jointly use different representation subspaces of queries, keys, and values.
실제로 동일한 쿼리, 키 및 값 세트가 주어지면 모델이 시퀀스 내에서 다양한 범위(예: 단거리 대 장거리)의 종속성을 캡처하는 것과 같이 동일한 attention 메커니즘의 다양한 동작에서 얻은 지식을 결합하기를 원할 수 있습니다. 따라서 어텐션 메커니즘이 쿼리, 키 및 값의 다른 representation 하위 공간을 공동으로 사용하도록 허용하는 것이 유리할 수 있습니다.
To this end, instead of performing a single attention pooling, queries, keys, and values can be transformed withℎindependently learned linear projections. Then theseℎprojected queries, keys, and values are fed into attention pooling in parallel. In the end,ℎattention pooling outputs are concatenated and transformed with another learned linear projection to produce the final output. This design is calledmulti-head attention, where each of theℎattention pooling outputs is ahead(Vaswaniet al., 2017). Using fully connected layers to perform learnable linear transformations,Fig. 11.5.1describes multi-head attention.
이를 위해 single attention pooling을 수행하는 대신 쿼리, 키 및 값을 ℎ independently학습된 linear projections으로 변환할 수 있습니다. 그런 다음 이러한 ℎ 프로젝션된 쿼리, 키 및 값이 어텐션 풀링에 병렬로 공급됩니다. 결국 ℎ 어텐션 풀링 출력은 최종 출력을 생성하기 위해 다른 학습된 선형 프로젝션과 연결 및 변환됩니다. 이 디자인을 multi-head attention이라고 하며, 각 ℎ 어텐션 풀링 출력은 head입니다(Vaswani et al., 2017). 그림 11.5.1은 학습 가능한 선형 변환을 수행하기 위해 fully connected layers를 사용하여 multi-head attention을 설명합니다.
Fig. 11.5.1 Multi-head attention, where multiple heads are concatenated then linearly transformed.
import math
import torch
from torch import nn
from d2l import torch as d2l
11.5.1.Model
Before providing the implementation of multi-head attention, let’s formalize this model mathematically. Given a queryq∈ℝdq, a keyk∈ℝdk, and a valuev∈ℝdv, each attention headℎi(i=1,…,ℎ) is computed as
멀티 헤드 어텐션을 구현하기 전에 이 모델을 수학적으로 공식화해 보겠습니다. 쿼리 q∈ℝdq, 키 k∈ℝdk 및 값 v∈ℝdv가 주어지면 각 주의 헤드 ℎi(i=1,…,ℎ)는 다음과 같이 계산됩니다.
Based on this design, each head may attend to different parts of the input. More sophisticated functions than the simple weighted average can be expressed.
이 design에 따라 각 헤드는 입력의 다른 부분에 attend 할 것입니다. simple weighted average보다 더 정교한 기능을 표현할 수 있습니다.
11.5.2.Implementation
In our implementation, we choose the scaled dot-product attention for each head of the multi-head attention. To avoid significant growth of computational cost and parameterization cost, we set pq=pk=pv=po/ℎ. Note thatℎheads can be computed in parallel if we set the number of outputs of linear transformations for the query, key, and value topqℎ=pkℎ=pvℎ=po. In the following implementation,pois specified via the argumentnum_hiddens.
이 구현에서 우리는 multi-head attention의 각 헤드에 대해 scaled dot-product attention을 선택합니다. 계산 비용과 매개변수화 비용의 상당한 증가를 피하기 위해 pq=pk=pv=po/ℎ로 설정합니다. 쿼리, 키 및 값에 대한 선형 변환의 출력 수를 pqℎ=pkℎ=pvℎ=po로 설정하면 ℎ 헤드를 병렬로 계산할 수 있습니다. 다음 구현에서 po는 num_hiddens 인수를 통해 지정됩니다.
class MultiHeadAttention(d2l.Module): #@save
"""Multi-head attention."""
def __init__(self, num_hiddens, num_heads, dropout, bias=False, **kwargs):
super().__init__()
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.LazyLinear(num_hiddens, bias=bias)
self.W_k = nn.LazyLinear(num_hiddens, bias=bias)
self.W_v = nn.LazyLinear(num_hiddens, bias=bias)
self.W_o = nn.LazyLinear(num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# Shape of queries, keys, or values:
# (batch_size, no. of queries or key-value pairs, num_hiddens)
# Shape of valid_lens: (batch_size,) or (batch_size, no. of queries)
# After transposing, shape of output queries, keys, or values:
# (batch_size * num_heads, no. of queries or key-value pairs,
# num_hiddens / num_heads)
queries = self.transpose_qkv(self.W_q(queries))
keys = self.transpose_qkv(self.W_k(keys))
values = self.transpose_qkv(self.W_v(values))
if valid_lens is not None:
# On axis 0, copy the first item (scalar or vector) for num_heads
# times, then copy the next item, and so on
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# Shape of output: (batch_size * num_heads, no. of queries,
# num_hiddens / num_heads)
output = self.attention(queries, keys, values, valid_lens)
# Shape of output_concat: (batch_size, no. of queries, num_hiddens)
output_concat = self.transpose_output(output)
return self.W_o(output_concat)
위 코드는 멀티헤드 어텐션(Multi-head Attention)을 구현한 클래스를 나타냅니다.
__init__: 클래스 초기화 메서드입니다. 멀티헤드 어텐션을 구현하기 위해 필요한 구성 요소들을 초기화합니다. num_hiddens는 각 헤드에서 사용할 히든 유닛의 수, num_heads는 헤드의 개수, dropout은 드롭아웃 비율입니다. 나머지 인자들은 부가적인 인자들입니다.
forward: 멀티헤드 어텐션의 순전파를 정의한 메서드입니다. 입력으로 queries, keys, values를 받습니다. 이들은 (batch_size, no. of queries or key-value pairs, num_hiddens) 형태의 텐서입니다. valid_lens는 유효한 길이 정보로, (batch_size,) 혹은 (batch_size, no. of queries) 형태의 텐서입니다. 이 메서드는 멀티헤드 어텐션을 구성하는 다양한 선형 변환과 어텐션 연산을 수행합니다.
transpose_qkv: 어텐션 연산을 위해 Queries, Keys, Values를 준비하는 과정을 담당합니다. 이 메서드는 입력으로 받은 텐서를 일정한 변환을 거쳐 차원을 조절하고 헤드의 개수만큼 복제합니다.
attention: 멀티헤드 어텐션의 주요 어텐션 연산을 수행합니다. d2l.DotProductAttention 클래스를 통해 어텐션 가중치를 계산합니다.
transpose_output: 어텐션 연산 결과를 다시 원래 형태로 되돌리는 메서드입니다. 멀티헤드 어텐션 연산 후 헤드별 결과를 원래의 형태로 병합합니다.
총평하면, 이 클래스는 멀티헤드 어텐션의 순전파를 구현한 것으로, 여러 헤드로 어텐션을 계산하고, 각 헤드의 결과를 병합하여 최종 결과를 반환합니다.
self.transpose_qkv 메서드를 통해 Queries, Keys, Values를 준비합니다.
valid_lens가 주어진 경우, 헤드 수에 맞게 복제하여 준비합니다.
멀티헤드 어텐션 연산을 수행하는 self.attention 객체를 호출합니다.
어텐션 연산 결과를 원래 형태로 변환하고 선형 변환을 거쳐 최종 출력을 만듭니다.
In summary, the MultiHeadAttention class implements the forward pass of multi-head attention, where queries, keys, and values are prepared using linear transformations, and then attention is computed using the self.attention object. The final output is obtained by transforming the attention output using another linear transformation.
요약하면 MultiHeadAttention 클래스는 선형 변환을 사용하여 쿼리, 키 및 값을 준비한 다음 self.attention 개체를 사용하여 주의를 계산하는 다중 헤드 어텐션의 정방향 전달을 구현합니다. 최종 출력은 다른 선형 변환을 사용하여 어텐션 출력을 변환하여 얻습니다.
To allow for parallel computation of multiple heads, the aboveMultiHeadAttentionclass uses two transposition methods as defined below. Specifically, thetranspose_outputmethod reverses the operation of thetranspose_qkvmethod.
multiple heads의 병렬 계산을 허용하기 위해 위의 MultiHeadAttention 클래스는 아래에 정의된 두 가지 transposition 방법을 사용합니다. 구체적으로 transpose_output 메서드는 transpose_qkv 메서드의 동작을 반대로 합니다.
@d2l.add_to_class(MultiHeadAttention) #@save
def transpose_qkv(self, X):
"""Transposition for parallel computation of multiple attention heads."""
# Shape of input X: (batch_size, no. of queries or key-value pairs,
# num_hiddens). Shape of output X: (batch_size, no. of queries or
# key-value pairs, num_heads, num_hiddens / num_heads)
X = X.reshape(X.shape[0], X.shape[1], self.num_heads, -1)
# Shape of output X: (batch_size, num_heads, no. of queries or key-value
# pairs, num_hiddens / num_heads)
X = X.permute(0, 2, 1, 3)
# Shape of output: (batch_size * num_heads, no. of queries or key-value
# pairs, num_hiddens / num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
@d2l.add_to_class(MultiHeadAttention) #@save
def transpose_output(self, X):
"""Reverse the operation of transpose_qkv."""
X = X.reshape(-1, self.num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
위의 코드는 MultiHeadAttention 클래스에 두 개의 새로운 메서드를 추가하는 부분입니다. 이 두 메서드는 멀티헤드 어텐션의 연산을 병렬로 처리하기 위해 입력 데이터의 형태를 변환하는 역할을 수행합니다. 각 메서드에 대해 한 줄씩 설명해보겠습니다.
@d2l.add_to_class(MultiHeadAttention)
def transpose_qkv(self, X):
"""Transposition for parallel computation of multiple attention heads."""
X = X.reshape(X.shape[0], X.shape[1], self.num_heads, -1)
X = X.permute(0, 2, 1, 3)
return X.reshape(-1, X.shape[2], X.shape[3])
transpose_qkv 메서드는 Queries, Keys, Values를 준비하기 위한 변환을 수행합니다.
X는 입력 데이터로, shape는 (batch_size, no. of queries or key-value pairs, num_hiddens)입니다.
먼저, 입력 데이터의 shape을 조정하여 각 헤드에 대한 차원을 추가합니다. 따라서 X의 shape는 (batch_size, no. of queries or key-value pairs, num_heads, num_hiddens / num_heads)이 됩니다.
그 다음, permute를 사용하여 헤드 차원을 뒤로 이동시킵니다. 이렇게 하면 병렬 계산이 가능해집니다. 결과적으로 X의 shape는 (batch_size, num_heads, no. of queries or key-value pairs, num_hiddens / num_heads)가 됩니다.
마지막으로, reshape을 통해 다시 원래의 형태로 되돌립니다. 이렇게 하면 X의 shape는 (batch_size * num_heads, no. of queries or key-value pairs, num_hiddens / num_heads)이 됩니다.
@d2l.add_to_class(MultiHeadAttention)
def transpose_output(self, X):
"""Reverse the operation of transpose_qkv."""
X = X.reshape(-1, self.num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
먼저, X의 shape을 재조정하여 현재의 차원을 헤드 차원으로 되돌립니다. 따라서 X의 shape는 (batch_size * num_heads, no. of queries or key-value pairs, num_hiddens / num_heads)이 됩니다.
그 다음, 다시 permute를 사용하여 차원을 원래대로 조정합니다. 결과적으로 X의 shape는 (batch_size * num_heads, no. of queries or key-value pairs, num_hiddens / num_heads)가 됩니다.
마지막으로, reshape을 통해 원래의 형태로 되돌립니다. 이렇게 하면 X의 shape는 (batch_size, no. of queries or key-value pairs, num_hiddens)가 됩니다.
이렇게 두 메서드를산을 한, 연산 성능을 향상시킬 수 있습니다.
Let’s test our implementedMultiHeadAttentionclass using a toy example where keys and values are the same. As a result, the shape of the multi-head attention output is (batch_size,num_queries,num_hiddens).
키와 값이 동일한 toy example를 사용하여 구현된 MultiHeadAttention 클래스를 테스트해 보겠습니다. 결과적으로 멀티 헤드 어텐션 출력의 모양은 (batch_size, num_queries, num_hiddens)입니다.
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_heads, 0.5)
batch_size, num_queries, num_kvpairs = 2, 4, 6
valid_lens = torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
Y = torch.ones((batch_size, num_kvpairs, num_hiddens))
d2l.check_shape(attention(X, Y, Y, valid_lens),
(batch_size, num_queries, num_hiddens))
위의 코드는 MultiHeadAttention 클래스의 인스턴스를 생성하고 실제 데이터를 이용하여 어텐션 연산을 수행하는 부분입니다. 코드를 한 줄씩 설명하겠습니다.
즉, 위의 코드는 멀티헤드 어텐션 클래스를 이용하여 더미 데이터를 사용하여 실제 어텐션 연산을 수행하고 그 결과의 shape을 확인하는 예시입니다.
11.5.3.Summary
Multi-head attention combines knowledge of the same attention pooling via different representation subspaces of queries, keys, and values. To compute multiple heads of multi-head attention in parallel, proper tensor manipulation is needed.
Multi-head attention은 쿼리, 키 및 값의 다른 representation 하위 공간을 통해 동일한 attention pooling에 대한 지식을 결합합니다. 멀티 헤드 어텐션의 여러 헤드를 병렬로 계산하려면 적절한 텐서 조작이 필요합니다.
Multi Head Attention이란?
'Multi-Head Attention'은 어텐션 메커니즘의 한 종류로, 하나의 어텐션 가중치만을 사용하는 것이 아니라 여러 개의 어텐션 가중치를 병렬로 계산하여 다양한 관점에서 정보를 추출하는 방법을 의미합니다.
일반적인 어텐션 메커니즘은 쿼리(Query)와 키(Key) 그리고 값(Value)의 세 가지 입력을 받아서 쿼리와 각 키 사이의 유사도를 계산한 후, 이 유사도를 가중치로 사용하여 값들을 가중합하여 최종 출력을 얻습니다. 이러한 메커니즘은 쿼리와 키가 비슷한 패턴을 가지는 경우에 유용하게 작동합니다.
하지만 멀티헤드 어텐션은 여러 개의 어텐션 헤드를 사용하여 쿼리, 키, 값에 각각 다른 선형 변환을 수행한 후 병렬로 어텐션 연산을 수행합니다. 이렇게 함으로써 네트워크는 여러 가지 다른 관점에서 정보를 추출하고, 각 헤드의 어텐션 출력을 합치는 것으로 다양한 특징을 동시에 고려할 수 있습니다. 이렇게 다양한 관점에서 정보를 수집하면 모델의 성능이 향상되는 경우가 많습니다.
멀티헤드 어텐션은 주로 트랜스포머(Transformer)와 같은 딥러닝 모델에서 사용되며, 자연어 처리와 기계 번역과 같은 과제에서 특히 효과적인 결과를 보이는 기술입니다.
11.5.4.Exercises
Visualize attention weights of multiple heads in this experiment.
Suppose that we have a trained model based on multi-head attention and we want to prune least important attention heads to increase the prediction speed. How can we design experiments to measure the importance of an attention head?
The Bahdanau Attention Mechanism, also known as Additive Attention, is an attention mechanism introduced by Dzmitry Bahdanau et al. in the context of sequence-to-sequence models for machine translation. This mechanism aims to address the limitation of the basic encoder-decoder architecture, where a fixed-length context vector is used to encode the entire source sequence into a single vector. The Bahdanau Attention Mechanism enhances this architecture by allowing the decoder to focus on different parts of the source sequence as it generates each target word.
바다나우 어텐션 메커니즘, 또는 추가적인 어텐션(Additive Attention),은 Dzmitry Bahdanau 등에 의해 소개된 어텐션 메커니즘으로, 기계 번역을 위한 시퀀스-투-시퀀스 모델의 맥락에서 등장했습니다. 이 메커니즘은 기본적인 인코더-디코더 아키텍처의 한계를 해결하기 위해 개발되었습니다. 이 아키텍처에서는 고정 길이의 컨텍스트 벡터가 사용되어 전체 소스 시퀀스를 하나의 벡터로 인코딩하는 문제가 있었습니다. 바다나우 어텐션 메커니즘은 디코더가 각 타겟 단어를 생성하는 동안 소스 시퀀스의 다른 부분에 초점을 맞출 수 있도록 향상된 아키텍처를 제공합니다.
The key idea behind the Bahdanau Attention Mechanism is to compute attention scores for each source sequence position based on a weighted combination of the decoder's hidden state and the encoder's hidden states. These attention scores indicate the relevance of each source position to the current decoding step. The decoder then combines these attention-weighted encoder hidden states to obtain a context vector, which is used to generate the target word.
The steps of the Bahdanau Attention Mechanism are as follows:
바다나우 어텐션 메커니즘의 핵심 아이디어는 디코더의 현재 은닉 상태와 인코더의 은닉 상태의 가중 결합을 기반으로 각 소스 시퀀스 위치의 어텐션 스코어를 계산하는 것입니다. 이러한 어텐션 스코어는 각 소스 위치가 현재 디코딩 단계에 얼마나 관련성 있는지를 나타냅니다. 디코더는 이러한 어텐션 가중치를 사용하여 은닉 상태를 가중합하여 컨텍스트 벡터를 얻습니다. 이 컨텍스트 벡터는 타겟 단어를 생성하는 데 사용됩니다.
바다나우 어텐션 메커니즘의 단계는 다음과 같습니다:
Compute Alignment Scores: Calculate attention scores between the decoder's current hidden state and each encoder hidden state. 어텐션 스코어 계산: 디코더의 현재 은닉 상태와 각 인코더 은닉 상태 간의 어텐션 스코어를 계산합니다.
Compute Attention Weights: Apply a softmax function to the alignment scores to get attention weights that sum up to 1. These weights represent the importance of each encoder hidden state in generating the current target word. 어텐션 가중치 계산: 어텐션 스코어에 소프트맥스 함수를 적용하여 어텐션 가중치를 얻습니다. 이 가중치는 각 인코더 은닉 상태가 현재 타겟 단어를 생성하는 데 얼마나 중요한지를 나타냅니다.
Calculate the Context Vector: Take a weighted sum of the encoder hidden states using the attention weights to obtain the context vector. 컨텍스트 벡터 계산: 어텐션 가중치를 사용하여 인코더 은닉 상태의 가중합을 계산하여 컨텍스트 벡터를 얻습니다.
Generate the Output: Combine the context vector with the decoder's current hidden state to generate the target word. 출력 생성: 컨텍스트 벡터를 디코더의 현재 은닉 상태와 결합하여 타겟 단어를 생성합니다.
The Bahdanau Attention Mechanism allows the model to selectively focus on different parts of the source sequence as it generates each target word. This helps improve the quality of generated translations and capture more complex relationships between source and target sequences. It has been a fundamental building block in many state-of-the-art sequence-to-sequence models and has contributed to significant improvements in various natural language processing tasks, including machine translation and text generation.
바다나우 어텐션 메커니즘은 모델이 각 타겟 단어를 생성하는 동안 소스 시퀀스의 다른 부분에 집중할 수 있도록 합니다. 이로써 생성된 번역의 품질을 향상시키고 소스와 타겟 시퀀스 간의 복잡한 관계를 더 잘 포착할 수 있습니다. 바다나우 어텐션 메커니즘은 많은 최신 시퀀스-투-시퀀스 모델에서 중요한 구성 요소로 사용되며 기계 번역 및 텍스트 생성과 같은 다양한 자연어 처리 작업에서 큰 향상을 이끌어냈습니다.
When we encountered machine translation inSection 10.7, we designed an encoder-decoder architecture for sequence to sequence (seq2seq) learning based on two RNNs(Sutskeveret al., 2014). Specifically, the RNN encoder transforms a variable-length sequence into afixed-shapecontext variable. Then, the RNN decoder generates the output (target) sequence token by token based on the generated tokens and the context variable.
섹션 10.7에서 기계 번역을 만났을 때 우리는 두 개의 RNN을 기반으로 시퀀스 대 시퀀스(seq2seq) 학습을 위한 인코더-디코더 아키텍처를 설계했습니다(Sutskever et al., 2014). 특히 RNN 인코더는 가변 길이 시퀀스를 고정된 모양의 컨텍스트 변수로 변환합니다. 그러면 RNN 디코더는 생성된 토큰과 컨텍스트 변수를 기반으로 토큰별로 출력(대상) 시퀀스 토큰을 생성합니다.
RecallFig. 10.7.2which we reprint below (Fig. 11.4.1) with some additional detail. Conventionally, in an RNN all relevant information about a source sequence is translated into some internalfixed-dimensionalstate representation by the encoder. It is this very state that is used by the decoder as the complete and exclusive source of information to generate the translated sequence. In other words, the seq2seq mechanism treats the intermediate state as a sufficient statistic of whatever string might have served as input.
그림 10.7.2는 아래에 다시 인쇄되어 있습니다(그림 11.4.1). 일반적으로 RNN에서 소스 시퀀스에 대한 모든 관련 정보는 인코더에 의해 일부 내부 fixed-dimensionalstate representation으로 변환됩니다. 변환된 시퀀스를 생성하기 위한 완전하고 배타적인 정보 소스로서 디코더에 의해 사용되는 바로 이 상태입니다. 즉, seq2seq 메커니즘은 중간 state를 입력으로 제공된 문자열의 충분한 통계로 취급합니다.
Fig. 11.4.1 Sequence to Sequence Model. The state, as generated by the encoder, is the only piece of information shared between the encoder and the decoder.
While this is quite reasonable for short sequences, it is clear that it is infeasible for long sequences, such as a book chapter or even just a very long sentence. After all, after a while there will simply not be enough “space” in the intermediate representation to store all that is important in the source sequence. Consequently the decoder will fail to translate long and complex sentences. One of the first to encounter wasGraves (2013)when they tried to design an RNN to generate handwritten text. Since the source text has arbitrary length they designed a differentiable attention model to align text characters with the much longer pen trace, where the alignment moves only in one direction. This, in turn, draws on decoding algorithms in speech recognition, e.g., hidden Markov models(Rabiner and Juang, 1993).
이것은 짧은 시퀀스에 대해서는 상당히 타당하지만 책의 장이나 매우 긴 문장과 같은 긴 시퀀스에는 실행 불가능하다는 것이 분명합니다. 결국, 잠시 후 소스 시퀀스에서 중요한 모든 것을 저장할 intermediate representation에 충분한 "공간"이 없을 것입니다. 결과적으로 디코더는 길고 복잡한 문장을 번역하지 못합니다. Graves(2013)가 손으로 쓴 텍스트를 생성하기 위해 RNN을 설계하려고 시도했을 때 처음 접한 것 중 하나였습니다. 원본 텍스트의 길이는 임의적이므로 정렬이 한 방향으로만 이동하는 훨씬 더 긴 펜 추적으로 텍스트 문자를 정렬하기 위해 differentiable attention model을 설계했습니다. 이것은 차례로 음성 인식의 디코딩 알고리즘, 예를 들어 hidden Markov models(Rabiner and Juang, 1993)을 사용합니다.
Inspired by the idea of learning to align,Bahdanauet al.(2014)proposed a differentiable attention modelwithoutthe unidirectional alignment limitation. When predicting a token, if not all the input tokens are relevant, the model aligns (or attends) only to parts of the input sequence that are deemed relevant to the current prediction. This is then used to update the current state before generating the next token. While quite innocuous in its description, thisBahdanau attention mechanismhas arguably turned into one of the most influential ideas of the past decade in deep learning, giving rise to Transformers(Vaswaniet al., 2017)and many related new architectures.
Bahdanau et al. (2014)은 단방향 정렬 제한 없이 차별화 가능한 attention model을 제안했습니다. 토큰을 예측할 때 모든 입력 토큰이 관련되지 않은 경우 모델은 현재 예측과 관련이 있는 것으로 간주되는 입력 시퀀스의 일부에만 정렬(또는 attends)합니다. 그런 다음 다음 토큰을 생성하기 전에 현재 상태를 업데이트하는 데 사용됩니다. 이 Bahdanau attention mechanism은 description에서 큰 문제가 없어 보입니다. 그래서 이 방법은 트랜스포머(Vaswani et al., 2017) 및 많은 관련 새로운 아키텍처를 발생시키면서 딥 러닝에서 지난 10년 동안 가장 영향력 있는 아이디어 중 하나로 변모했습니다.
import torch
from torch import nn
from d2l import torch as d2l
11.4.1.Model
We follow the notation introduced by the seq2seq architecture ofSection 10.7, in particular(10.7.3). The key idea is that instead of keeping the state, i.e., the context variablecsummarizing the source sentence as fixed, we dynamically update it, as a function of both the original text (encoder hidden statesℎt) and the text that was already generated (decoder hidden states st′−1). This yieldsct′, which is updated after any decoding time stepc′. Suppose that the input sequence is of lengthT. In this case the context variable is the output of attention pooling:
섹션 10.7, 특히 (10.7.3)의 seq2seq architecture에 의해 도입된 표기법을 따릅니다. 핵심 아이디어는 state를 유지하는 대신, 즉 소스 문장을 고정된 것으로 요약하는 컨텍스트 변수 c를 원본 텍스트(encoder hidden states ℎt)와 이미 생성된 텍스트의 함수로 동적으로 업데이트한다는 것입니다. (decoder hidden states st'-1). 이는 임의의 decoding time step c' 후에 업데이트되는 ct'를 생성합니다. 입력 시퀀스의 길이가 T라고 가정합니다. 이 경우 컨텍스트 변수는 attention pooling의 출력입니다.
We usedst′−1as the query, andℎtas both the key and the value. Note thatct′is then used to generate the statest′and to generate a new token (see(10.7.3)). In particular, the attention weightαis computed as in(11.3.3)using the additive attention scoring function defined by(11.3.7). This RNN encoder-decoder architecture using attention is depicted inFig. 11.4.2. Note that later this model was modified such as to include the already generated tokens in the decoder as further context (i.e., the attention sum does stop atTbut rather it proceeds up tot′−1). For instance, seeChanet al.(2015)for a description of this strategy, as applied to speech recognition.
우리는 쿼리로 st′-1을 사용했고 키와 값으로 ℎt를 사용했습니다. ct'는 상태 st'를 생성하고 새 토큰을 생성하는 데 사용됩니다((10.7.3) 참조). 특히 attention weight α는 (11.3.7)에 의해 정의된 additive attention scoring function를 사용하여 (11.3.3)과 같이 계산됩니다. 주의를 사용하는 이 RNN 인코더-디코더 아키텍처는 그림 11.4.2에 묘사되어 있습니다. 나중에 이 모델은 디코더에 이미 생성된 토큰을 추가 컨텍스트로 포함하도록 수정되었습니다(즉, 주의 합계는 T에서 중지하지만 오히려 t'-1까지 진행함). 예를 들어 Chan et al. (2015) 음성 인식에 적용되는 이 전략에 대한 설명입니다.
Fig. 11.4.2 Layers in an RNN encoder-decoder model with the Bahdanau attention mechanism.
11.4.2.Defining the Decoder with Attention
To implement the RNN encoder-decoder with attention, we only need to redefine the decoder (omitting the generated symbols from the attention function simplifies the design). Let’s begin with the base interface for decoders with attention by defining the quite unsurprisingly namedAttentionDecoderclass.
attention이 있는 RNN 인코더-디코더를 구현하려면 디코더만 재정의하면 됩니다(attention function에서 생성된 기호를 생략하면 설계가 간소화됨). 꽤 놀랍지 않게 명명된 AttentionDecoder 클래스를 정의하여 어텐션이 있는 디코더의 기본 인터페이스부터 시작하겠습니다.
class AttentionDecoder(d2l.Decoder): #@save
"""The base attention-based decoder interface."""
def __init__(self):
super().__init__()
@property
def attention_weights(self):
raise NotImplementedError
위의 코드는 어텐션 기반 디코더의 기본 인터페이스인 AttentionDecoder 클래스를 정의합니다. 이 클래스는 디코더의 기본 구조와 어텐션 메커니즘을 사용하는 인터페이스를 제공합니다.
AttentionDecoder 클래스는 d2l.Decoder 클래스를 상속받아 구현됩니다. d2l.Decoder 클래스는 디코더 모델을 구축하기 위한 기본 클래스로 사용됩니다.
__init__ 메서드는 클래스의 초기화를 수행합니다. 여기서 별다른 초기화 작업은 없고, 부모 클래스인 d2l.Decoder의 생성자를 호출합니다.
@property 데코레이터는 attention_weights라는 프로퍼티를 정의합니다. 이 프로퍼티는 어텐션 가중치를 반환하는 역할을 합니다.
attention_weights 메서드의 내용은 구현되지 않았으며, NotImplementedError를 발생시켜서 해당 메서드가 서브클래스에서 반드시 구현되어야 한다는 것을 나타냅니다. 이렇게 하여 AttentionDecoder 클래스를 상속받는 실제 어텐션 디코더 클래스는 반드시 attention_weights 메서드를 구현해야 합니다.
이렇게 AttentionDecoder 클래스는 어텐션 기반 디코더의 기본 인터페이스를 제공하며, 어텐션 가중치를 반환하는 attention_weights 메서드의 구현을 강제합니다. 이 클래스를 상속받아 실제 어텐션 메커니즘을 사용하는 디코더 클래스를 구현할 수 있습니다.
We need to implement the RNN decoder in theSeq2SeqAttentionDecoderclass. The state of the decoder is initialized with (i) the hidden states of the last layer of the encoder at all time steps, used as keys and values for attention; (ii) the hidden state of the encoder at all layers at the final time step. This serves to initialize the hidden state of the decoder; and (iii) the valid length of the encoder, to exclude the padding tokens in attention pooling. At each decoding time step, the hidden state of the last layer of the decoder, obtained at the previous time step, is used as the query of the attention mechanism. Both the output of the attention mechanism and the input embedding are concatenated to serve as the input of the RNN decoder.
Seq2SeqAttentionDecoder 클래스에서 RNN 디코더를 구현해야 합니다. 디코더의 state는 (i) attention를 위한 keys and values로 사용되는 모든 time steps에서 encoder의 last layer의 hidden states로 초기화됩니다. (ii) 최종 시간 단계에서 모든 계층에서 인코더의 숨겨진 상태. 이는 디코더의 숨겨진 상태를 초기화하는 역할을 합니다. 및 (iii) 어텐션 풀링에서 패딩 토큰을 제외하기 위한 인코더의 유효 길이. 각 디코딩 시간 단계에서 이전 시간 단계에서 얻은 디코더의 마지막 계층의 숨겨진 상태가 어텐션 메커니즘의 쿼리로 사용됩니다. 어텐션 메커니즘의 출력과 입력 임베딩이 모두 연결되어 RNN 디코더의 입력으로 사용됩니다.
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.attention = d2l.AdditiveAttention(num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.LazyLinear(vocab_size)
self.apply(d2l.init_seq2seq)
def init_state(self, enc_outputs, enc_valid_lens):
# Shape of outputs: (num_steps, batch_size, num_hiddens).
# Shape of hidden_state: (num_layers, batch_size, num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
# Shape of enc_outputs: (batch_size, num_steps, num_hiddens).
# Shape of hidden_state: (num_layers, batch_size, num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# Shape of the output X: (num_steps, batch_size, embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# Shape of query: (batch_size, 1, num_hiddens)
query = torch.unsqueeze(hidden_state[-1], dim=1)
# Shape of context: (batch_size, 1, num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# Concatenate on the feature dimension
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# Reshape x as (1, batch_size, embed_size + num_hiddens)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# After fully connected layer transformation, shape of outputs:
# (num_steps, batch_size, vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
위의 코드는 어텐션 메커니즘을 사용하는 시퀀스 투 시퀀스 디코더 모델인 Seq2SeqAttentionDecoder 클래스를 정의합니다.
Seq2SeqAttentionDecoder 클래스는 AttentionDecoder 클래스를 상속받아 구현됩니다. 이 클래스는 어텐션 메커니즘을 활용하여 시퀀스 투 시퀀스 디코더를 정의합니다.
__init__ 메서드는 클래스의 초기화를 수행합니다. 여기서는 어텐션 메커니즘(AdditiveAttention 클래스), 임베딩 레이어(nn.Embedding 클래스), GRU 레이어(nn.GRU 클래스), 그리고 최종 출력 레이어(nn.LazyLinear 클래스) 등을 정의하고 초기화합니다. 또한 d2l.init_seq2seq 함수를 통해 가중치 초기화를 수행합니다.
init_state 메서드는 인코더의 출력과 유효한 길이 정보를 초기 상태로 변환합니다. 이 메서드에서는 인코더의 출력을 차원을 변경하여 디코더에 맞는 형태로 변환하고, 인코더의 은닉 상태와 유효한 길이 정보도 함께 변환합니다.
forward 메서드는 디코더의 순전파 연산을 수행합니다. 입력 데이터 X와 상태 state를 받아 디코더의 출력을 계산합니다. 이 때 어텐션 메커니즘을 활용하여 인코더의 출력과 관련 정보를 활용합니다. 순환 신경망(RNN)을 통해 디코더의 출력을 계산하며, 최종 출력을 반환합니다.
attention_weights 메서드는 어텐션 가중치를 반환합니다. 이 메서드를 통해 디코더가 어텐션 메커니즘을 통해 어떤 부분에 주의를 기울였는지를 확인할 수 있습니다.
이렇게 Seq2SeqAttentionDecoder 클래스는 어텐션 메커니즘을 사용하여 시퀀스 투 시퀀스 디코더 모델을 구현한 클래스입니다. 입력 시퀀스와 인코더의 출력, 상태 정보를 활용하여 디코더의 출력을 생성하는 역할을 합니다.
In the following, we test the implemented decoder with attention using a minibatch of 4 sequences, each of which are 7 time steps long.
다음에서는 각각 7time steps long인 4개 시퀀스의 미니배치를 사용하여 attention 과 함께 구현된 디코더를 테스트합니다.
d2l.check_shape(state[0], (batch_size, num_steps, num_hiddens))는 디코더 상태의 첫 번째 요소(출력)의 크기가 (batch_size, num_steps, num_hiddens)와 일치하는지 확인합니다.
d2l.check_shape(state[1][0], (batch_size, num_hiddens))는 디코더 상태의 두 번째 요소(은닉 상태)의 크기가 (batch_size, num_hiddens)와 일치하는지 확인합니다.
이렇게 코드는 시퀀스 투 시퀀스 모델과 어텐션 메커니즘을 사용하는 디코더 모델의 구조를 설명하고, 입력 데이터를 통해 디코더의 출력과 상태를 확인하는 과정을 보여줍니다.
11.4.3.Training
Now that we specified the new decoder we can proceed analogously toSection 10.7.6: specify the hyperparameters, instantiate a regular encoder and a decoder with attention, and train this model for machine translation.
이제 새 디코더를 지정했으므로 섹션 10.7.6과 유사하게 진행할 수 있습니다. 하이퍼 매개변수를 지정하고 일반 인코더와 디코더를 attention과 함께 인스턴스화하고 기계 번역을 위해 이 모델을 훈련합니다.
encoder 객체는 인코더 모델로, d2l.Seq2SeqEncoder 클래스를 사용하여 생성되며, 소스 언어의 어휘 크기와 위에서 설정한 파라미터들을 입력으로 받습니다.
decoder 객체는 어텐션 메커니즘을 사용하는 디코더 모델로, Seq2SeqAttentionDecoder 클래스를 사용하여 생성되며, 타겟 언어의 어휘 크기와 위에서 설정한 파라미터들을 입력으로 받습니다.
model 객체는 Seq2Seq 모델로, 인코더와 디코더, 그리고 패딩 토큰의 인덱스를 입력으로 받습니다.
trainer 객체는 학습을 관리하는 Trainer 클래스의 객체로, 최대 에포크 수, 그래디언트 클리핑 임계값, 그리고 GPU 개수를 설정합니다.
trainer.fit(model, data)는 위에서 설정한 모델과 데이터를 이용하여 모델을 학습시키는 과정을 수행합니다.
이렇게 코드는 Machine Translation을 위한 Seq2Seq 모델과 어텐션 메커니즘을 구현하고 데이터를 활용하여 학습시키는 과정을 나타냅니다.
After the model is trained, we use it to translate a few English sentences into French and compute their BLEU scores.
모델이 학습된 후 이를 사용하여 영어 문장 몇 개를 프랑스어로 번역하고 BLEU 점수를 계산합니다.
engs = ['go .', 'i lost .', 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(
data.build(engs, fras), d2l.try_gpu(), data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '<eos>':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{d2l.bleu(" ".join(translation), fr, k=2):.3f}')
위의 코드는 학습된 Seq2Seq 모델을 사용하여 번역 결과를 생성하고 BLEU 스코어를 계산하여 출력하는 과정을 나타냅니다.
engs와 fras는 영어-프랑스어 번역을 위한 예시 문장들입니다.
preds, _ = model.predict_step(data.build(engs, fras), d2l.try_gpu(), data.num_steps)는 모델을 사용하여 입력 문장들에 대한 번역 결과를 생성합니다. data.build(engs, fras)는 입력 문장들을 데이터로 변환하는 과정을 나타냅니다. 이 결과는 예측된 토큰 시퀀스와 어텐션 가중치가 반환됩니다.
for en, fr, p in zip(engs, fras, preds):는 각각의 예시 문장과 예측된 결과를 묶어서 순회합니다.
내부 루프에서 data.tgt_vocab.to_tokens(p)는 예측된 토큰 시퀀스를 단어로 변환합니다. to_tokens 함수는 모델의 출력에 대한 토큰들을 어휘 단어로 변환해주는 역할을 합니다. <eos> 토큰을 만날 때까지 변환된 토큰들을 모아 번역 결과를 생성합니다.
d2l.bleu(" ".join(translation), fr, k=2):.3f는 생성된 번역 결과와 실제 프랑스어 문장 간의 BLEU 스코어를 계산하고 출력합니다. BLEU는 번역의 품질을 측정하는 지표로, 높을수록 번역이 원문에 가깝다는 의미입니다.
총결적으로, 이 코드는 학습된 Seq2Seq 모델을 사용하여 예시 문장에 대한 번역 결과를 생성하고, 생성된 결과와 실제 정답 문장 간의 BLEU 스코어를 계산하여 출력하는 과정을 보여줍니다.
go . => ['va', '!'], bleu,1.000
i lost . => ["j'ai", 'perdu', '.'], bleu,1.000
he's calm . => ['je', "l'ai", '.'], bleu,0.000
i'm home . => ['je', 'suis', 'chez', 'moi', '.'], bleu,1.000
BLUE score란?
The "BLEU score" stands for "Bilingual Evaluation Understudy" score. It is a metric used to evaluate the quality of machine-generated translations by comparing them to one or more reference translations (human-generated translations). BLEU is widely used in natural language processing and machine translation tasks to quantitatively measure how well a machine-generated translation aligns with one or more human references.
"BLEU 점수"는 "Bilingual Evaluation Understudy" 점수의 약자로, 기계 번역의 품질을 평가하기 위해 사용되는 지표입니다. 이 점수는 기계 생성 번역과 하나 이상의 참조 번역(인간 생성 번역)을 비교하여 평가합니다. BLEU는 자연어 처리 및 기계 번역 작업에서 기계 생성 번역이 참조 번역과 얼마나 잘 일치하는지를 정량적으로 측정하는 데 널리 사용됩니다.
BLEU computes a score between 0 and 1, where higher scores indicate better translations. The score is calculated based on the overlap of n-grams (contiguous sequences of n words) between the machine-generated translation and the reference translation(s). The basic idea is that the more n-grams are shared between the machine translation and the references, the better the translation quality.
BLEU는 0에서 1 사이의 점수를 계산하며, 높은 점수는 더 좋은 번역을 나타냅니다. 이 점수는 기계 생성 번역과 하나 이상의 인간 참조 번역 간의 n-gram(연속된 n개의 단어로 이루어진 구)의 겹치는 부분을 기반으로 계산됩니다. 기본 아이디어는 기계 번역과 참조 간에 공유되는 n-gram이 더 많을수록 번역 품질이 더 좋다는 것입니다.
In practice, BLEU score computation takes into account precision of n-grams, where precision considers how many of the n-grams in the machine translation appear in the reference, and a brevity penalty to discourage overly short translations. The BLEU score can be computed for various n-gram sizes (typically 1 to 4), and an average BLEU score is often reported.
실제로 BLEU 점수 계산은 n-gram의 정밀도(기계 번역에 나타난 n-gram 중 참조에 포함된 n-gram의 수)와, 너무 짧은 번역을 방지하기 위한 간결성 패널티를 고려합니다. BLEU 점수는 일반적으로 1에서 4까지의 다양한 n-gram 크기에 대해 계산되며, 평균 BLEU 점수가 보통 보고됩니다.
While BLEU is a useful metric, it has limitations, such as not fully capturing the nuances of human language and not being sensitive to word order. More recent evaluation metrics like METEOR, ROUGE, and CIDEr have been developed to address some of these limitations.
BLEU는 유용한 지표이지만, 인간 언어의 뉘앙스를 완전히 포착하지 못하거나 단어 순서에 민감하지 못하는 등의 한계가 있습니다. 최근에는 이러한 한계를 해결하기 위해 METEOR, ROUGE, CIDEr 등의 더 최신의 평가 지표가 개발되었습니다.
Let’s visualize the attention weights when translating the last English sentence. We see that each query assigns non-uniform weights over key-value pairs. It shows that at each decoding step, different parts of the input sequences are selectively aggregated in the attention pooling.
마지막 영어 문장을 번역하는 것에 대한 attention weights를 시각화해 봅시다. 각 쿼리가 키-값 쌍에 대해 균일하지 않은 가중치를 할당하는 것을 볼 수 있습니다. 각 디코딩 단계에서 입력 시퀀스의 다른 부분이 어텐션 풀링에서 선택적으로 집계됨을 보여줍니다.
_, dec_attention_weights = model.predict_step(
data.build([engs[-1]], [fras[-1]]), d2l.try_gpu(), data.num_steps, True)
attention_weights = torch.cat(
[step[0][0][0] for step in dec_attention_weights], 0)
attention_weights = attention_weights.reshape((1, 1, -1, data.num_steps))
# Plus one to include the end-of-sequence token
d2l.show_heatmaps(
attention_weights[:, :, :, :len(engs[-1].split()) + 1].cpu(),
xlabel='Key positions', ylabel='Query positions')
위 코드는 모델의 어텐션 가중치(attention weights)를 시각화하는 과정을 나타냅니다.
model.predict_step: 이 함수를 사용하여 모델의 예측 결과와 어텐션 가중치를 얻습니다. 입력으로는 모델이 예측할 문장의 번역 쌍(영어와 프랑스어)을 사용합니다. 또한 어텐션 가중치를 얻기 위해 세 번째 매개변수 data.num_steps와 True를 전달합니다. 이를 통해 어텐션 가중치의 시각화를 위한 준비를 합니다.
torch.cat와 reshape: dec_attention_weights는 여러 단계에서 얻은 어텐션 가중치의 리스트입니다. 이를 모두 결합하고, 형태를 (1, 1, -1, data.num_steps)로 변경합니다. 여기서 -1은 가변적인 크기를 의미합니다.
show_heatmaps: d2l.show_heatmaps 함수를 사용하여 어텐션 가중치를 히트맵으로 시각화합니다. 이 함수는 어텐션 가중치를 입력으로 받아 시각화된 히트맵을 생성합니다. x축과 y축에는 각각 Key 위치와 Query 위치가 표시됩니다. 이를 통해 어텐션 메커니즘이 입력 문장과 출력 문장 사이의 어디에 집중하는지 시각적으로 확인할 수 있습니다.
총평하면, 이 코드는 모델이 마지막 문장 번역에서 어떤 단어에 어떤 정도로 집중했는지를 시각화하여 확인하는 데 사용됩니다.
11.4.4.Summary
When predicting a token, if not all the input tokens are relevant, the RNN encoder-decoder with the Bahdanau attention mechanism selectively aggregates different parts of the input sequence. This is achieved by treating the state (context variable) as an output of additive attention pooling. In the RNN encoder-decoder, the Bahdanau attention mechanism treats the decoder hidden state at the previous time step as the query, and the encoder hidden states at all the time steps as both the keys and values.
토큰을 예측할 때 모든 입력 토큰이 관련되지 않은 경우 Bahdanau attention mechanism이 있는 RNN 인코더-디코더는 입력 시퀀스의 다른 부분을 선택적으로 집계합니다. 이는 state(컨텍스트 변수)를 additive attention pooling의 출력으로 처리하여 달성됩니다. RNN 인코더-디코더에서 Bahdanau attention mechanism은 이전 단계의 decoder hidden state를 쿼리로 처리하고 모든 단계의 encoder hidden states를 키와 값 모두로 처리합니다.
11.4.5.Exercises
Replace GRU with LSTM in the experiment.
Modify the experiment to replace the additive attention scoring function with the scaled dot-product. How does it influence the training efficiency?
InSection 11.2, we used a number of different distance-based kernels, including a Gaussian kernel to model interactions between queries and keys. As it turns out, distance functions are slightly more expensive to compute than inner products. As such, with the softmax operation to ensure nonnegative attention weights, much of the work has gone intoattention scoring functionsαin(11.1.3)andFig. 11.3.1that are simpler to compute.
섹션 11.2에서 쿼리와 키 간의 상호 작용을 모델링하기 위해 가우시안 커널을 포함하여 다양한 거리 기반 커널을 사용했습니다. 결과적으로 거리 함수는 내적(inner products)보다 계산 비용이 약간 더 비쌉니다. 이와 같이 음이 아닌 attention weights를 보장하기 위한 softmax operation으로 많은 작업이 (11.1.3) 및 그림 11.3.1의 attention scoring functions α로 진행되었으며 이는 계산하기 더 간단합니다.
Innder products (내적) 이란?
"Inner products" refer to a mathematical operation that takes two vectors and produces a scalar value. Also known as a dot product, it quantifies the similarity or alignment between two vectors by calculating the sum of the products of their corresponding components.
"내적"은 두 개의 벡터를 가져와서 스칼라 값을 생성하는 수학적 연산을 나타냅니다. 내적은 또한 점곱이라고도 하며, 두 벡터 간의 대응하는 구성 요소의 곱의 합을 계산하여 두 벡터의 유사성이나 정렬을 측정합니다.
For two vectors x and y in an n-dimensional space, the inner product is calculated as:
n-차원 공간에서 두 벡터 x와 y에 대해서 내적은 다음과 같이 계산됩니다:
x ⋅ y = x₁ * y₁ + x₂ * y₂ + ... + xₙ * yₙ
This operation is often used in various mathematical and computational contexts, such as vector spaces, linear algebra, functional analysis, and machine learning algorithms. Inner products have a wide range of applications, including measuring angles between vectors, calculating distances, finding projections, and solving optimization problems.
이 연산은 벡터 공간, 선형 대수학, 함수 해석 및 기계 학습 알고리즘과 같은 다양한 수학적 및 계산적 맥락에서 사용됩니다. 내적은 벡터 간의 각도를 측정하거나 거리를 계산하며, 투영을 찾는 데 사용되며, 최적화 문제를 해결하는 등 다양한 응용 분야가 있습니다.
Fig. 11.3.1 Computing the output of attention pooling as a weighted average of values, where weights are computed with the attention scoring function α and the softmax operation. 그림 11.3.1 가중 평균 값으로 어텐션 풀링의 출력을 계산합니다. 여기서 가중치는 어텐션 스코어링 함수 α와 소프트맥스 연산으로 계산됩니다.
import math
import torch
from torch import nn
from d2l import torch as d2l
11.3.1.Dot Product Attention
Let’s review the attention function (without exponentiation) from the Gaussian kernel for a moment:
잠시 동안 Gaussian kernel의 attention function(지수 없음)를 검토해 보겠습니다.
First, note that the last term depends onqonly. As such it is identical for all(q,ki)pairs. Normalizing the attention weights to1, as is done in(11.1.3), ensures that this term disappears entirely. Second, note that both batch and layer normalization (to be discussed later) lead to activations that have well-bounded, and often constant norms‖ki‖≈const. This is the case, for instance, whenever the keyskiwere generated by a layer norm. As such, we can drop it from the definition ofαwithout any major change in the outcome.
첫째, last term는 q에만 의존한다는 점에 유의하십시오. 따라서 모든 (q,ki) 쌍에 대해 동일합니다. (11.1.3)에서와 같이 attention weights를 1로 정규화하면 이 term가 완전히 사라집니다. 둘째, batch 및 layer normalization(나중에 논의됨) 모두 well-bounded하고 종종 constant norms인 ki‖≈const를 갖는 활성화로 이어집니다. 예를 들어 키 ki가 layer norm에 의해 생성될 때마다 그렇습니다. 따라서 결과에 큰 변화 없이 α의 정의에서 제외할 수 있습니다.
Last, we need to keep the order of magnitude of the arguments in the exponential function under control. Assume that all the elements of the queryq∈ℝ^dand the keyki∈ℝ^dare independent and identically drawn random variables with zero mean and unit variance. The dot product between both vectors has zero mean and a variance ofd. To ensure that the variance of the dot product still remains one regardless of vector length, we use thescaled dot-product attentionscoring function. That is, we rescale the dot-product by1/ √d. We thus arrive at the first commonly used attention function that is used, e.g., in Transformers(Vaswaniet al., 2017):
마지막으로 지수 함수(exponential function)에서 인수의 크기(magnitude) 순서를 제어할 필요가 있습니다. 쿼리 q∈ℝ^d 및 키 ki∈ℝ^d의 모든 요소가 평균이 0이고 단위 분산이 있는 독립적이고 동일하게 그려진 확률 변수라고 가정합니다. 두 벡터 간의 내적(dot product)은 zero mean이고 a variance ofd입니다. 벡터 길이에 관계없이 내적(dot product)의 분산(variance)이 여전히 1로 유지되도록 scaled dot-product attentionscoring function를 사용합니다. 즉, 내적(dot-product)을 1/ √d로 재조정합니다. 따라서 우리는 예를 들어 Transformers(Vaswani et al., 2017)에서 사용되는 첫 번째 일반적으로 사용되는 attention function에 도달합니다.
Scaled dot product attention이란?
'Scaled Dot Product Attention'은 트랜스포머(Transformer)와 같은 인공 신경망 모델에서 사용되는 어텐션(Attention) 메커니즘 중 하나입니다. 이 어텐션 메커니즘은 특정 쿼리(Query)와 키(Key) 사이의 관계를 계산하여 가중치를 생성하고, 이를 값(Value)에 적용하여 가중 평균을 계산하는 방법을 확장한 것입니다.
'Scaled Dot Product Attention'에서 "Scaled"는 어텐션 스코어를 정규화하기 위해 사용되는 조정 상수(scale factor)입니다. 어텐션 스코어는 쿼리와 각 키 사이의 내적(Dot Product)을 의미합니다. 내적을 스케일링하면 어텐션 스코어의 크기가 키의 차원 수에 영향을 받지 않게 됩니다.
이러한 접근 방식은 어텐션 스코어의 분포를 조절하여 학습을 안정화하고, 어텐션 가중치를 좀 더 관리 가능한 범위로 조절하여 기울기 소실과 폭주 문제를 완화하는 데 도움을 줍니다. 이러한 메커니즘은 트랜스포머의 인코더-디코더 어텐션, 멀티헤드 어텐션 등 다양한 컨텍스트에서 사용되며, 특히 자연어 처리 및 기계 번역과 같은 태스크에서 중요한 역할을 합니다.
Note that attention weightsαstill need normalizing. We can simplify this further via(11.1.3)by using the softmax operation:
attention 가중치 α는 여전히 정규화가 필요합니다. softmax 작업을 사용하여 (11.1.3)을 통해 이를 더 단순화할 수 있습니다.
As it turns out, all popular attention mechanisms use the softmax, hence we will limit ourselves to that in the remainder of this chapter.
밝혀진 바와 같이 모든 인기 있는 어텐션 메커니즘은 소프트맥스를 사용하므로 이 장의 나머지 부분에서는 이에 대해 제한할 것입니다.
11.3.2.Convenience Functions
We need a few functions to make the attention mechanism efficient to deploy. This includes tools to deal with strings of variable lengths (common for natural language processing) and tools for efficient evaluation on minibatches (batch matrix multiplication).
attention mechanism을 효율적으로 배포하려면 몇 가지 기능이 필요합니다. 여기에는 variable lengths의 문자열을 처리하는 도구(자연어 처리에 일반적임)와 미니배치(배치 행렬 곱셈)에서 efficient evaluation를 위한 도구가 포함됩니다.
11.3.2.1.Masked Softmax Operation
One of the most popular applications of the attention mechanism is to sequence models. Hence we need to be able to deal with sequences of different lengths. In some cases, such sequences may end up in the same minibatch, necessitating padding with dummy tokens for shorter sequences (seeSection 10.5for an example). These special tokens do not carry meaning. For instance, assume that we have the following three sentences:
attention mechanism의 가장 인기 있는 애플리케이션 중 하나는 sequence models입니다. 따라서 길이가 다른 시퀀스를 처리할 수 있어야 합니다. 경우에 따라 이러한 시퀀스는 더 짧은 시퀀스를 위해 dummy tokens으로 padding해야 하는 동일한 미니 배치로 끝날 수 있습니다(예는 섹션 10.5 참조). 이러한 특수 토큰에는 의미가 없습니다. 예를 들어, 다음 세 문장이 있다고 가정합니다.
(길이를 같게 하기 위해 넣은 blank는 아무런 의미가 없다.)
Dive into Deep Learning
Learn to code <blank>
Hello world <blank> <blank>
Since we do not want blanks in our attention model we simply need to limit∑ni=1 α(q,ki)vito∑li=1α(q,ki)vifor however longl ≤ nthe actual sentence is. Since it is such a common problem, it has a name: themasked softmax operation.
우리는 attention model에서 공백을 원하지 않기 때문에 실제 문장이 l ≤ n인 경우 ∑n i=1 α(q,ki)vi를 ∑l i=1 α(q,ki)vi로 제한하기만 하면 됩니다. 이는 매우 일반적인 문제이므로 masked softmax operation이라는 이름이 있습니다.
Let’s implement it. Actually, the implementation cheats ever so slightly by setting the values to zerovi=0fori>l. Moreover, it sets the attention weights to a large negative number, such as−106in order to make their contribution to gradients and values vanish in practice. This is done since linear algebra kernels and operators are heavily optimized for GPUs and it is faster to be slightly wasteful in computation rather than to have code with conditional (if then else) statements.
이제 이것을 구현합시다. 실제로 구현은 i>l에 대해 vi=0으로 값을 0으로 설정하여 약간 속입니다. 또한 attention weights를 -10**6과 같은 큰 음수로 설정하여 기울기와 값에 대한 기여도가 실제로 사라지도록 합니다. 이것은 선형 대수학 커널과 연산자가 GPU에 크게 최적화되어 있고 조건문(if then else)이 있는 코드를 사용하는 것보다 계산에서 약간 낭비하는 것이 더 빠르기 때문에 수행됩니다.
(blank가 있는 부분은 값을 0으로 설정하고 attention weights를 큰 음수로 설정해 기울기가 사라지도록 해서 계산에서 제외 시킵니다.)
def masked_softmax(X, valid_lens): #@save
"""Perform softmax operation by masking elements on the last axis."""
# X: 3D tensor, valid_lens: 1D or 2D tensor
def _sequence_mask(X, valid_len, value=0):
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# On the last axis, replace masked elements with a very large negative
# value, whose exponentiation outputs 0
X = _sequence_mask(X.reshape(-1, shape[-1]), valid_lens, value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
이 코드는 마스크된 소프트맥스 연산을 수행하는 함수인 masked_softmax를 정의합니다.
_sequence_mask 함수 정의: 이 함수는 시퀀스 길이에 따라 마스크를 생성하는 기능을 합니다. 주어진 시퀀스 길이(valid_len)보다 긴 부분을 마스크로 처리하여 지정된 값(기본값은 0)으로 설정합니다.
masked_softmax 함수 정의: 이 함수는 입력 텐서 X와 유효한 길이 정보 valid_lens를 받아 마스크된 소프트맥스 연산을 수행합니다.
valid_lens가 주어지지 않은 경우에는 nn.functional.softmax를 사용하여 전체 소프트맥스를 계산합니다.
valid_lens가 주어진 경우에는 입력 텐서의 shape를 확인하고, 만약 valid_lens가 1차원 텐서인 경우 각 위치에 대해 동일한 값을 반복합니다. 그렇지 않은 경우, valid_lens를 1차원으로 변형합니다.
마지막 축에서 마스크된 원소를 매우 작은 음수 값(-1e6)으로 대체하여 소프트맥스의 분모로 들어가지 않도록 합니다.
최종적으로 소프트맥스를 계산하고, 마스크가 적용된 부분의 출력이 0이 되도록 처리합니다.
이 함수는 특히 시계열 데이터와 같은 길이가 다양한 시퀀스에 대한 소프트맥스 연산을 처리하는 데 유용하며, 모델이 패딩된 부분을 무시하고 중요한 정보만 고려할 수 있게 합니다.
To illustrate how this function works, consider a minibatch of two examples of size2×4, where their valid lengths are2and3, respectively. As a result of the masked softmax operation, values beyond the valid lengths for each pair of vectors are all masked as zero.
이 함수가 어떻게 작동하는지 설명하기 위해 유효한 길이가 각각 2와 3인 크기 2×4의 두 가지 예의 미니 배치를 고려하십시오. 마스킹된 소프트맥스 연산의 결과 각 벡터 쌍의 유효 길이를 초과하는 값은 모두 0으로 마스킹됩니다.
위의 코드는 masked_softmax 함수를 사용하여 소프트맥스 연산을 수행하는 예시입니다.
torch.rand(2, 2, 4): 크기가 (2, 2, 4)인 무작위 값을 가진 3D 텐서입니다.
torch.tensor([2, 3]): 길이가 2인 1D 텐서로, 각 원소는 시퀀스 길이를 나타냅니다.
masked_softmax 함수는 입력 텐서와 유효한 길이 정보를 받아 소프트맥스 연산을 수행합니다. 이 예시에서는 다음과 같이 동작합니다:
입력 텐서의 크기: (2, 2, 4)
유효한 길이 정보: [2, 3]
입력 텐서의 각 요소에 대해 소프트맥스를 계산하되, 유효한 길이에 따라 패딩된 부분은 처리하지 않고 아주 작은 음수 값(-1e6)으로 대체하여 해당 부분의 소프트맥스 값이 0이 되도록 합니다. 결과적으로, 소프트맥스 연산을 수행한 결과가 반환됩니다.
예
If we need more fine-grained control to specify the valid length for each of the two vectors per example, we simply use a two-dimensional tensor of valid lengths. This yields:
예제당 두 벡터 각각에 대해 유효한 길이를 지정하기 위해 더 세밀한 제어가 필요한 경우 유효한 길이의 2차원 텐서를 사용하기만 하면 됩니다. 결과는 다음과 같습니다.
위의 코드는 masked_softmax 함수를 사용하여 소프트맥스 연산을 수행하는 또 다른 예시입니다.
torch.rand(2, 2, 4): 크기가 (2, 2, 4)인 무작위 값을 가진 3D 텐서입니다.
torch.tensor([[1, 3], [2, 4]]): 크기가 (2, 2)인 2D 텐서로, 각 행별로 시퀀스 길이를 나타냅니다.
이 경우, masked_softmax 함수가 다음과 같이 동작합니다:
입력 텐서의 크기: (2, 2, 4)
유효한 길이 정보: [[1, 3], [2, 4]]
입력 텐서의 각 요소에 대해 소프트맥스를 계산하되, 각 행별로 다른 길이를 가지므로 각 행의 마지막 원소를 제외한 부분은 아주 작은 음수 값(-1e6)으로 대체하여 해당 부분의 소프트맥스 값이 0이 되도록 합니다. 결과적으로, 소프트맥스 연산을 수행한 결과가 반환됩니다.
11.3.2.2.Batch Matrix Multiplication
Another commonly used operation is to multiply batches of matrices with another. This comes in handy when we have minibatches of queries, keys, and values. More specifically, assume that
일반적으로 사용되는 또 다른 작업은 행렬 배치를 다른 행렬과 곱하는 것입니다. 이는 쿼리, 키 및 값의 미니 배치가 있을 때 유용합니다. 더 구체적으로 가정하자면
Then the batch matrix multiplication (BMM) computes the element-wise product
그런 다음 BMM(배치 행렬 곱셈)은 요소별 곱을 계산합니다.
Let’s see this in action in a deep learning framework.
여기서 torch.bmm(Q, K)는 두 배치 행렬 텐서 Q와 K 간의 배치 매트릭스 곱셈을 수행하는 연산입니다. 이 결과 텐서의 크기는 (2, 3, 6)이 됩니다.
따라서 위의 코드에서 d2l.check_shape(torch.bmm(Q, K), (2, 3, 6))는 행렬 곱셈의 결과가 기대한 크기인 (2, 3, 6)과 동일한지를 확인하는 코드입니다. 만약 결과 텐서의 크기가 기대한 크기와 다르다면 오류가 발생할 것입니다.
batch matrix multiplation이란?
배치 행렬 곱셈(batch matrix multiplication)은 딥러닝에서 자주 사용되는 연산 중 하나로, 배치 처리를 통해 여러 입력 데이터에 대한 행렬 곱셈을 동시에 수행하는 것을 의미합니다. 이 연산은 주로 어텐션 메커니즘, 순환 신경망 (RNN), 변환자 (Transformer) 등에서 활발하게 활용됩니다.
배치 행렬 곱셈은 다음과 같이 정의됩니다:
두 개의 입력 텐서 X와 Y가 주어집니다.
X의 마지막 차원의 크기와 Y의 뒤에서 두 번째 차원의 크기가 일치해야 합니다. 즉, X의 크기는 (batch_size, d1, d2)이고 Y의 크기는 (batch_size, d2, d3)이라면 d2는 동일한 값이어야 합니다.
결과 텐서 Z의 크기는 (batch_size, d1, d3)가 됩니다.
이러한 배치 행렬 곱셈을 수행하면 각 배치의 입력 행렬이 행렬 곱셈을 거쳐 결과 행렬로 변환됩니다. 이 과정은 각각의 배치 데이터에 대해 병렬적으로 이루어지며, 배치 처리를 통해 연산 속도를 향상시킬 수 있습니다.
배치 행렬 곱셈은 신경망의 다양한 부분에서 사용되며, 주로 선형 변환과 어텐션 계산에 활용됩니다.
Let’s return to the dot-product attention introduced in(11.3.2). In general, it requires that both the query and the key have the same vector length, say d, even though this can be addressed easily by replacingq⊤kwithq⊤MkwhereMis a suitably chosen matrix to translate between both spaces. For now assume that the dimensions match.
(11.3.2)에서 소개한 내적 주의로 돌아가 봅시다. 일반적으로 쿼리와 키 모두 동일한 벡터 길이(예: d)를 가져야 합니다. q⊤k를 q⊤Mk로 대체하여 쉽게 해결할 수 있지만 여기서 M은 두 공간 사이를 변환하기 위해 적절하게 선택된 행렬입니다. 지금은 dimensions수가 일치한다고 가정합니다.
In practice, we often think in minibatches for efficiency, such as computing attention fornqueries andmkey-value pairs, where queries and keys are of lengthdand values are of lengthv. The scaled dot-product attention of queriesQ∈ℝn×d, keysK∈ℝm×d, and valuesV∈ℝm×vthus can be written as
실제로 우리는 쿼리와 키의 길이가 d이고 값의 길이가 v인 nqueries와 mkey-value pairs에 대한 어텐션을 계산하는 것과 같이 효율성을 위해 미니배치를 생각하는 경우가 많습니다. 쿼리의 scaled dot-product attention Q∈ ℝm×v, keys K∈ℝn×d 및 값 K∈ℝm×d는 다음과 같이 쓸 수 있습니다.
Note that when applying this to a minibatch, we need the batch matrix multiplication introduced in(11.3.5). In the following implementation of the scaled dot product attention, we use dropout for model regularization.
이것을 미니 배치에 적용할 때 (11.3.5)에서 소개한 배치 행렬 곱셈 batch matrix multiplication이 필요합니다. scaled dot product attention의 다음 구현에서는 모델 정규화 model regularization를 위해 dropout을 사용합니다.
class DotProductAttention(nn.Module): #@save
"""Scaled dot product attention."""
def __init__(self, dropout):
super().__init__()
self.dropout = nn.Dropout(dropout)
# Shape of queries: (batch_size, no. of queries, d)
# Shape of keys: (batch_size, no. of key-value pairs, d)
# Shape of values: (batch_size, no. of key-value pairs, value dimension)
# Shape of valid_lens: (batch_size,) or (batch_size, no. of queries)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# Swap the last two dimensions of keys with keys.transpose(1, 2)
scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
이 코드는 스케일 조절된 점곱 어텐션(DotProductAttention)을 구현한 파이토치(nn.Module) 클래스입니다. 어텐션 메커니즘은 주어진 쿼리(queries)와 키(keys)의 쌍에 대한 가중합을 구하는데 사용되며, 자연어 처리 및 시계열 데이터 처리와 같은 다양한 딥러닝 모델에서 사용됩니다.
여기서 어텐션은 다음과 같이 작동합니다:
쿼리(queries)와 키(keys)는 주어진 입력에 대한 임베딩입니다.
쿼리와 키 간의 점곱을 계산하고, 각 값에 대한 가중치를 얻습니다.
가중치는 스케일링된(스케일 조절) 소프트맥스 함수를 통과하여 정규화됩니다.
가중치를 값을(values)에 적용하여 어텐션 가중합을 계산합니다.
위 코드에서 forward 함수의 인자들은 다음과 같습니다:
queries: 쿼리 행렬로, 크기는 (batch_size, no. of queries, d)입니다. 여기서 d는 임베딩 차원을 나타냅니다.
keys: 키 행렬로, 크기는 (batch_size, no. of key-value pairs, d)입니다.
values: 값 행렬로, 크기는 (batch_size, no. of key-value pairs, value dimension)입니다. 값 차원은 쿼리와 키에 대한 가중합 후의 결과 차원을 나타냅니다.
valid_lens: 옵션으로 주어진 유효한 시퀀스 길이입니다. 이를 사용하여 마스킹을 수행합니다.
이어서 코드 내부를 살펴보면, 점곱 어텐션의 연산 과정을 담은 것을 확인할 수 있습니다. 최종적으로 어텐션 가중합을 구하고 이를 값(values)에 적용하여 반환합니다.
torch.bmm() 에 대하여.
The torch.bmm() function in PyTorch stands for "batch matrix-matrix" multiplication. It is used to perform matrix multiplication between two batches of matrices. This function is particularly useful in deep learning, especially in scenarios involving neural networks, where batch operations are common due to the parallel processing capabilities of modern hardware.
torch.bmm() 함수는 파이토치에서 "배치 행렬-행렬" 곱셈을 수행하는 기능입니다. 이 함수는 두 개의 행렬 배치 간의 행렬 곱셈을 수행하는 데 사용됩니다. 특히 현대 하드웨어의 병렬 처리 능력으로 인해 배치 작업이 일반적인 딥 러닝에서 유용하게 사용됩니다.
Here's how torch.bmm() works:
torch.bmm() 함수의 작동 방식은 다음과 같습니다:
Inputs: It takes two input tensors of shape (batch_size, n, m) and (batch_size, m, p), where batch_size is the number of samples in the batch, and n, m, and p are the dimensions of the matrices. 입력: torch.bmm()은 (batch_size, n, m) 모양과 (batch_size, m, p) 모양의 두 개의 입력 텐서를 가져옵니다. 여기서 batch_size는 배치의 샘플 수이고, n, m, p는 행렬의 차원입니다.
Output: The output of torch.bmm() will be a tensor of shape (batch_size, n, p). 출력: torch.bmm()의 출력은 (batch_size, n, p) 모양의 텐서입니다.
Multiplication: For each batch sample, the function performs matrix multiplication between the corresponding matrices in the two input tensors. 곱셈: 각 배치 샘플에 대해 함수는 두 입력 텐서의 해당 행렬 사이의 행렬 곱셈을 수행합니다.
In other words, torch.bmm() computes the matrix product for each pair of matrices within the batch and stacks the results into an output tensor. This is especially useful when dealing with batches of sequences in sequence-to-sequence models, where each sequence can be represented as a matrix.
Here's a simple example of using torch.bmm():
다시 말해, torch.bmm()은 배치 내 각 행렬 쌍에 대한 행렬 곱셈을 계산하고 결과를 출력 텐서로 스택합니다. 이는 특히 시퀀스 간 변환 모델에서 시퀀스 배치를 다룰 때 유용합니다. 여기 간단한 torch.bmm() 사용 예시가 있습니다:
import torch
batch_size = 2
n = 3
m = 4
p = 2
# 두 개의 배치 행렬 생성
A = torch.randn(batch_size, n, m)
B = torch.randn(batch_size, m, p)
# 배치 행렬-행렬 곱셈 수행
C = torch.bmm(A, B)
print(C.shape) # 출력: torch.Size([2, 3, 2])
In this example, A and B are batched matrices with dimensions (2, 3, 4) and (2, 4, 2) respectively. After performing torch.bmm(A, B), the resulting tensor C will have dimensions (2, 3, 2), which corresponds to the batch size, number of rows, and number of columns of the multiplied matrices.
이 예제에서 A와 B는 각각 (2, 3, 4)와 (2, 4, 2) 차원의 배치 행렬입니다. torch.bmm(A, B)를 수행한 후 결과 텐서 C는 차원이 (2, 3, 2)이며 이는 배치 크기, 행의 개수 및 열의 개수에 해당합니다.
To illustrate how theDotProductAttentionclass works, we use the same keys, values, and valid lengths from the earlier toy example for additive attention. For the purpose of our example we assume that we have a minibatch size of2, a total of10keys and values, and that the dimensionality of the values is4. Lastly, we assume that the valid length per observation is2and6respectively. Given that, we expect the output to be a2×1×4tensor, i.e., one row per example of the minibatch.
DotProductAttention 클래스의 작동 방식을 설명하기 위해 추가 주의를 위해 이전 toy example와 동일한 키, 값 및 유효한 길이를 사용합니다. 예제의 목적을 위해 미니배치 크기가 2이고 총 10개의 키와 값이 있고 값의 차원이 4라고 가정합니다. 마지막으로 관찰당 유효한 길이는 각각 2와 6이라고 가정합니다. . 이를 감안할 때 출력이 2×1×4 텐서, 즉 미니배치의 예당 하나의 행이 될 것으로 예상합니다.
위 코드는 DotProductAttention 클래스를 사용하여 어텐션 메커니즘을 시연하는 예시입니다. 주어진 쿼리(queries), 키(keys), 값(values), 그리고 유효한 시퀀스 길이(valid_lens)로부터 어텐션 결과를 계산하고 그 크기를 확인하는 과정을 보여줍니다.
여기서 주어진 텐서들은 다음과 같습니다:
queries: 쿼리 행렬로, 크기는 (2, 1, 2)입니다. 두 개의 쿼리가 있고, 각 쿼리의 임베딩 차원은 2입니다.
keys: 키 행렬로, 크기는 (2, 10, 2)입니다. 두 개의 쿼리에 대해 10개의 키가 있으며, 각 키의 임베딩 차원은 2입니다.
values: 값 행렬로, 크기는 (2, 10, 4)입니다. 두 개의 쿼리에 대해 10개의 값이 있으며, 각 값의 차원은 4입니다.
valid_lens: 유효한 시퀀스 길이로, 크기는 (2,6)입니다. 각 쿼리에 대한 유효한 길이가 포함되어 있습니다.
이어서 DotProductAttention 클래스를 초기화하고, eval() 메서드를 호출하여 드롭아웃을 비활성화합니다. 그리고 이 클래스를 이용하여 주어진 입력으로 어텐션을 수행하고 그 결과의 크기를 d2l.check_shape 함수를 통해 확인합니다. 이를 통해 어텐션 결과의 크기가 예상한 것과 일치하는지 검증하는 것이 목적입니다.
Pytorch에서 eval() 메소드란?
eval()은 PyTorch 모델의 메서드 중 하나로, 모델을 평가 모드로 설정하는 역할을 합니다. 평가 모드로 설정되면 모델 내부에서 발생하는 일부 동작이 변경되어 학습 중에만 사용되는 요소들을 비활성화하거나 조정합니다.
일반적으로 학습 중에 사용되는 요소 중에는 드롭아웃(Dropout)과 배치 정규화(Batch Normalization)이 있습니다. 드롭아웃은 학습 중에 일부 뉴런을 무작위로 비활성화하여 과적합을 방지하는데 사용됩니다. 배치 정규화는 배치 단위로 입력 데이터의 평균과 분산을 조정하여 학습을 안정화하는 역할을 합니다.
eval()을 호출하면 모델 내부의 드롭아웃과 배치 정규화 등 학습 중에만 활성화되는 부분들이 비활성화됩니다. 이로써 모델의 평가 결과가 학습 결과와 일관성을 유지하게 되며, 실제 평가나 추론에 사용될 때의 모델 동작을 정확하게 반영할 수 있습니다.
예를 들어, 위에서 설명한 코드에서 attention.eval()을 호출한 이유는 모델의 학습 시에 사용되는 드롭아웃을 비활성화하여 평가 모드에서도 일관된 결과를 얻기 위함입니다.
Let’s check whether the attention weights actually vanish for anything beyond the second and sixth column respectively (due to setting valid length to2and6).
유효 길이를 2와 6으로 설정했기 때문에 각각 두 번째와 여섯 번째 열을 넘어서는 어텐션 가중치가 실제로 사라지는지 확인해 봅시다.
위 코드는 주어진 DotProductAttention 모델의 어텐션 가중치(attention weights)를 시각화하여 히트맵으로 나타내는 작업을 수행합니다.
show_heatmaps 함수는 매트릭스 형태의 데이터를 입력으로 받아서 히트맵으로 시각화해주는 함수입니다. 이를 통해 어텐션 가중치를 시각화하면 어떤 키(key)가 어떤 쿼리(query)에 얼마나 중요한지를 확인할 수 있습니다.
attention.attention_weights는 어텐션 메커니즘을 통해 계산된 각 쿼리에 대한 키의 가중치입니다. 이를 통해 어텐션 가중치를 show_heatmaps 함수에 넣어 시각화하면, 행이 쿼리(Query)를, 열이 키(Keys)를 나타내는 히트맵이 생성됩니다. 각 히트맵 셀의 색상이 진할수록 해당 키가 해당 쿼리에 높은 가중치를 부여한 것을 의미합니다.
11.3.4.Additive Attention
When queries qand keyskare vectors of different dimensionalities, we can either use a matrix to address the mismatch viaq⊤Mk, or we can use additive attention as the scoring function. Another benefit is that, as its name indicates, the attention is additive. This can lead to some minor computational savings. Given a queryq∈ℝqand a keyk∈ℝk, theadditive attentionscoring function(Bahdanauet al., 2014)is given by
쿼리 q와 키 k가 서로 다른 차원의 벡터인 경우 행렬을 사용하여 q⊤Mk를 통해 불일치를 해결하거나 additive attention를 scoring function로 사용할 수 있습니다. 또 다른 이점은 이름에서 알 수 있듯이 attention is additive라는 것입니다. 이것은 약간의 계산 절감으로 이어질 수 있습니다. 쿼리 q∈ℝq와 키 k∈ℝk가 주어지면 additive attentionscoring function(Bahdanau et al., 2014)는 다음과 같이 제공됩니다.
whereWq∈ℝℎ×q, Wk∈ℝℎ×k, andwv∈ℝℎare the learnable parameters. This term is then fed into a softmax to ensure both nonnegativity and normalization. An equivalent interpretation of(11.3.7)is that the query and key are concatenated and fed into an MLP with a single hidden layer. Usingtanhas the activation function and disabling bias terms, we implement additive attention as follows:
여기서 Wq∈ℝℎ×q, Wk∈ℝℎ×k 및 wv∈ℝℎ는 learnable parameters입니다. 그런 다음 이 term을 소프트맥스에 입력하여 nonnegativity과 normalization를 모두 보장합니다. (11.3.7)의 equivalent interpretation은 쿼리와 키가 연결되어 단일 숨겨진 레이어가 있는 MLP에 공급된다는 것입니다. tanh를 활성화 함수로 사용하고 biasterms을 비활성화하여 다음과 같이 additive attention를 구현합니다.
class AdditiveAttention(nn.Module): #@save
"""Additive attention."""
def __init__(self, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
self.W_k = nn.LazyLinear(num_hiddens, bias=False)
self.W_q = nn.LazyLinear(num_hiddens, bias=False)
self.w_v = nn.LazyLinear(1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
queries, keys = self.W_q(queries), self.W_k(keys)
# After dimension expansion, shape of queries: (batch_size, no. of
# queries, 1, num_hiddens) and shape of keys: (batch_size, 1, no. of
# key-value pairs, num_hiddens). Sum them up with broadcasting
features = queries.unsqueeze(2) + keys.unsqueeze(1)
features = torch.tanh(features)
# There is only one output of self.w_v, so we remove the last
# one-dimensional entry from the shape. Shape of scores: (batch_size,
# no. of queries, no. of key-value pairs)
scores = self.w_v(features).squeeze(-1)
self.attention_weights = masked_softmax(scores, valid_lens)
# Shape of values: (batch_size, no. of key-value pairs, value
# dimension)
return torch.bmm(self.dropout(self.attention_weights), values)
위 코드는 AdditiveAttention 클래스를 정의하는 파이토치 모듈입니다. 이 클래스는 추가적인 어텐션 메커니즘을 구현한 것으로, 주어진 쿼리(query)와 키(key)를 이용하여 가중치를 계산하여 값을 어텐션을 통해 결합하는 과정을 수행합니다.
__init__: 클래스 생성자로, 초기화를 위한 함수입니다. 여기서는 nn.LazyLinear 레이어를 이용하여 가중치 매개변수를 정의합니다. 쿼리와 키에 각각 W_q와 W_k 매개변수를 통과시키고, 가중치 값을 계산할 때 w_v 매개변수를 이용합니다.
forward: 클래스의 순전파 연산을 정의하는 함수입니다. 주어진 쿼리와 키에 각각 W_q와 W_k를 적용하여 차원을 변환하고, 차원을 확장하여 쿼리와 키를 더합니다. 그 후에는 tanh 함수를 이용하여 활성화 값을 생성하고, 이 값을 w_v 매개변수에 통과시켜 가중치 스코어를 계산합니다. 마지막으로, 어텐션 가중치를 정규화한 후, 해당 가중치를 값을 어텐션을 통해 결합하여 반환합니다.
이러한 방식으로, AdditiveAttention 클래스는 쿼리와 키의 특성을 추가하여 어텐션 가중치를 계산하고, 이를 사용하여 값을 어텐션을 통해 결합합니다.
unsqueeze를 사용하여 쿼리와 키의 차원을 확장하여 덧셈이 가능한 형태로 변환합니다.
tanh 함수를 적용하여 활성화 값을 생성합니다.
w_v를 사용하여 어텐션 스코어를 계산하고, 마지막 차원을 제거하여 scores를 얻습니다.
masked_softmax 함수를 사용하여 어텐션 가중치를 계산합니다.
self.attention_weights에 어텐션 가중치를 저장합니다.
최종적으로 어텐션 가중치를 이용하여 값들을 결합한 결과를 반환합니다.
이렇게 정의된 AdditiveAttention 클래스는 입력된 쿼리와 키를 이용하여 어텐션 가중치를 계산하고, 이를 사용하여 값들을 결합하는 과정을 수행합니다.
Let’s see howAdditiveAttentionworks. In our toy example we pick queries, keys and values of size(2,1,20),(2,10,2)and(2,10,4), respectively. This is identical to our choice forDotProductAttention, except that now the queries are20-dimensional. Likewise, we pick(2,6)as the valid lengths for the sequences in the minibatch.
AdditiveAttention이 어떻게 작동하는지 살펴보겠습니다. 우리의 toy example에서는 크기가 각각 (2,1,20), (2,10,2) 및 (2,10,4)인 쿼리, 키 및 값을 선택합니다. 이제 쿼리가 20차원이라는 점을 제외하면 DotProductAttention에 대한 선택과 동일합니다. 마찬가지로 미니배치의 시퀀스에 유효한 길이로 (2,6)을 선택합니다.
위 코드는 AdditiveAttention 클래스를 사용하여 어텐션 연산을 수행하는 예시입니다.
queries는 (batch_size, no. of queries, d) 형태의 입력 쿼리 텐서입니다. 이 예시에서는 크기가 (2, 1, 20)인 텐서를 사용합니다.
attention 객체는 AdditiveAttention 클래스의 인스턴스입니다.
attention.eval()은 모델을 평가 모드로 설정하는 메서드입니다. 드롭아웃 등의 영향을 받지 않습니다.
attention(queries, keys, values, valid_lens)는 AdditiveAttention 클래스의 forward 메서드를 호출하여 어텐션 연산을 수행합니다. 여기서 keys, values, valid_lens는 정의되지 않았지만, 이전에 정의된 값들을 사용하는 것으로 가정합니다.
d2l.check_shape는 계산된 결과의 형태를 확인하는 메서드입니다. 이 코드에서는 결과의 형태가 (2, 1, 4)인지 확인하고 있습니다.
When reviewing the attention function we see a behavior that is qualitatively quite similar to that fromDotProductAttention. That is, only terms within the chosen valid length(2,6)are nonzero.
attention function을 검토할 때 DotProductAttention의 동작과 질적으로 매우 유사한 동작을 볼 수 있습니다. 즉, 선택한 유효 길이(2,6) 내의 항만 0이 아닙니다.
attention.attention_weights는 어텐션 가중치를 나타내는 텐서입니다. 이 값은 이전에 정의된 어텐션 연산을 통해 계산된 것으로 가정합니다.
attention.attention_weights.reshape((1, 1, 2, 10))는 어텐션 가중치를 히트맵으로 표시하기 위해 형태를 재구성하는 것입니다. 여기서 (1, 1, 2, 10)은 히트맵 형태를 지정하고 있습니다. 첫 번째 차원은 배치 크기를 나타내며, 두 번째 차원은 어텐션 쿼리의 개수, 세 번째 차원은 어텐션 키의 개수, 네 번째 차원은 키의 특성 개수를 나타냅니다.
xlabel과 ylabel은 각각 x축과 y축의 라벨을 지정하는 매개변수입니다.
결과적으로, 어텐션 가중치를 히트맵으로 시각화하여 키와 쿼리 간의 관련성을 확인할 수 있습니다.
11.3.5.Summary
In this section we introduced the two key attention scoring functions: dot product and additive attention. They are effective tools for aggregating across sequences of variable length. In particular, the dot product attention is the mainstay of modern Transformer architectures. When queries and keys are vectors of different lengths, we can use the additive attention scoring function instead. Optimizing these layers is one of the key areas of advance in recent years. For instance,Nvidia’s Transformer Libraryand Megatron(Shoeybiet al., 2019)crucially rely on efficient variants of the attention mechanism. We will dive into this in quite a bit more detail as we review Transformers in later sections.
이 섹션에서는 두 가지 주요 attention scoring functions인 dot product 및 additive attention을 소개했습니다. 가변 길이의 시퀀스를 집계하는 데 효과적인 도구입니다. 특히 ***dot product attention***은 현대 트랜스포머 아키텍처의 중심입니다. 쿼리와 키가 길이가 다른 벡터인 경우 additive attention scoring function을 대신 사용할 수 있습니다. 이러한 계층을 최적화하는 것은 최근 몇 년간 발전의 핵심 영역 중 하나입니다. 예를 들어 Nvidia의 Transformer Library와 Megatron(Shoeybi et al., 2019)은 어텐션 메커니즘의 efficient variants에 결정적으로 의존합니다. 이후 섹션에서 트랜스포머를 검토하면서 이에 대해 좀 더 자세히 살펴보겠습니다.
attention scoring functions 란?
'어텐션 스코어 함수(Attention Scoring Function)'는 어텐션 메커니즘에서 사용되는 핵심 요소 중 하나입니다. 이 함수는 쿼리(Query)와 키(Key) 간의 관련성을 계산하여 어텐션 가중치(Attention Weights)를 생성합니다. 어텐션 스코어 함수는 주어진 쿼리와 키의 조합에 대해 얼마나 관련성이 높은지를 측정하여 어텐션 가중치를 결정하는 역할을 합니다.
어텐션 스코어 함수의 목적은 쿼리와 키 간의 유사도를 정량화하여 어텐션 가중치를 생성하는 것입니다. 이렇게 생성된 어텐션 가중치는 값이 높을수록 해당 키가 해당 쿼리에 더 많은 영향을 미치도록 하는 역할을 합니다. 어텐션 스코어 함수는 다양한 형태와 방식으로 정의될 수 있으며, 이는 어텐션 메커니즘의 종류에 따라 달라질 수 있습니다.
어텐션 스코어 함수는 주로 내적(Dot Product), 유클리디안 거리(Euclidean Distance), 맨하탄 거리(Manhattan Distance), 다양한 커널 함수(Kernel Function) 등을 활용하여 구현될 수 있습니다. 이 함수의 선택은 어텐션 메커니즘의 성능과 특성에 영향을 미칩니다.
Dot Product란?
'닷 프로덕트(Dot Product)'는 두 벡터 사이에서 각 성분을 곱한 후 그 결과를 더한 값을 나타내는 연산입니다. 두 벡터의 내적(Dot Product)이라고도 불립니다. 닷 프로덕트는 벡터 간의 유사도, 방향, 정사영 등을 계산하는 데 사용됩니다.
두 벡터 A와 B의 닷 프로덕트는 다음과 같이 표현됩니다:
A⋅B=∑i=1nAi×Bi
여기서 Ai와 Bi는 각 벡터 A와 B의 i번째 성분을 나타냅니다. 닷 프로덕트의 결과는 스칼라 값으로 나타납니다.
닷 프로덕트는 다양한 분야에서 사용되며, 특히 선형 대수학, 머신 러닝, 신경망 등에서 많이 활용됩니다. 벡터의 내적이나 유사도 측정, 정사영 등 다양한 개념과 연관되어 사용됩니다.
Dot product attention이란?
'Dot Product Attention'은 어텐션 메커니즘 중 하나로, 입력된 쿼리(Query)와 키(Key) 간의 내적(점곱)을 통해 유사도를 계산하여 어텐션 가중치를 생성하는 방식입니다. 이 방법은 입력된 쿼리와 키의 유사성을 측정하는 과정에서 내적 연산을 활용하여 어텐션 가중치를 계산합니다.
'Dot Product Attention'의 주요 특징은 다음과 같습니다:
내적 연산: 쿼리와 키의 벡터를 내적 연산으로 곱하여 유사도를 계산합니다. 내적은 벡터의 방향성을 고려하는 연산으로, 유사한 방향성을 가지는 벡터일수록 더 높은 유사도 값을 얻게 됩니다.
활성화 함수: 내적 연산을 통해 계산된 유사도 값을 활성화 함수(일반적으로 소프트맥스)를 사용하여 정규화하여 어텐션 가중치를 생성합니다.
출력 계산: 어텐션 가중치와 키 벡터를 가중합하여 출력 벡터를 생성합니다.
'Dot Product Attention'은 계산이 간단하고 효과적으로 유사도를 측정할 수 있어서 주로 자연어 처리(NLP) 분야에서 사용되며, 특히 트랜스포머(Transformer) 모델의 어텐션 메커니즘에 많이 활용됩니다.
Additive Attention 이란?
'Additive Attention'은 쿼리(Query)와 키(Key)가 서로 다른 차원을 가지는 경우에 사용되는 어텐션 메커니즘입니다. 이 메커니즘은 쿼리와 키 간의 차원을 일치시키기 위해 가산(Additive) 함수를 사용하여 어텐션 스코어를 계산합니다.
일반적인 어텐션 메커니즘에서는 쿼리와 키가 동일한 차원을 가지며 내적(Dot Product) 또는 유사도 함수를 통해 어텐션 점수를 계산합니다. 하지만 'Additive Attention'에서는 쿼리와 키의 차원이 다르므로, 이를 일치시키기 위해 선형 변환과 활성화 함수를 사용하여 어텐션 스코어를 생성합니다.
일반적으로 'Additive Attention'은 다음과 같은 단계로 이루어집니다:
쿼리와 키를 각각 선형 변환하여 차원을 맞춥니다.
각 변환된 쿼리와 키 간의 유사도를 계산합니다.
계산된 유사도에 활성화 함수(예: 하이퍼볼릭 탄젠트)를 적용하여 어텐션 스코어를 생성합니다.
어텐션 스코어를 정규화하고 가중합하여 최종 어텐션 출력을 계산합니다.
'Additive Attention'은 특히 트랜스포머 아키텍처에서 사용되는 어텐션 메커니즘 중 하나로, 입력의 다른 부분 간의 상관 관계를 모델링하고 시퀀스 정보를 캡처하는 데 사용됩니다.
11.3.6.Exercises
Implement distance-based attention by modifying theDotProductAttentioncode. Note that you only need the squared norms of the keys‖ki‖2for an efficient implementation.
Modify the dot product attention to allow for queries and keys of different dimensionalities by employing a matrix to adjust dimensions.
How does the computational cost scale with the dimensionality of the keys, queries, values, and their number? What about the memory bandwidth requirements?